Sabitlenmiş Tweet

Voting, Ensembles and bringing AI to life
alphacephei.com/nsh/2022/06/14…
English
AlphaCephei
1.8K posts

@alphacep
Developers of Vosk Speech Toolkit







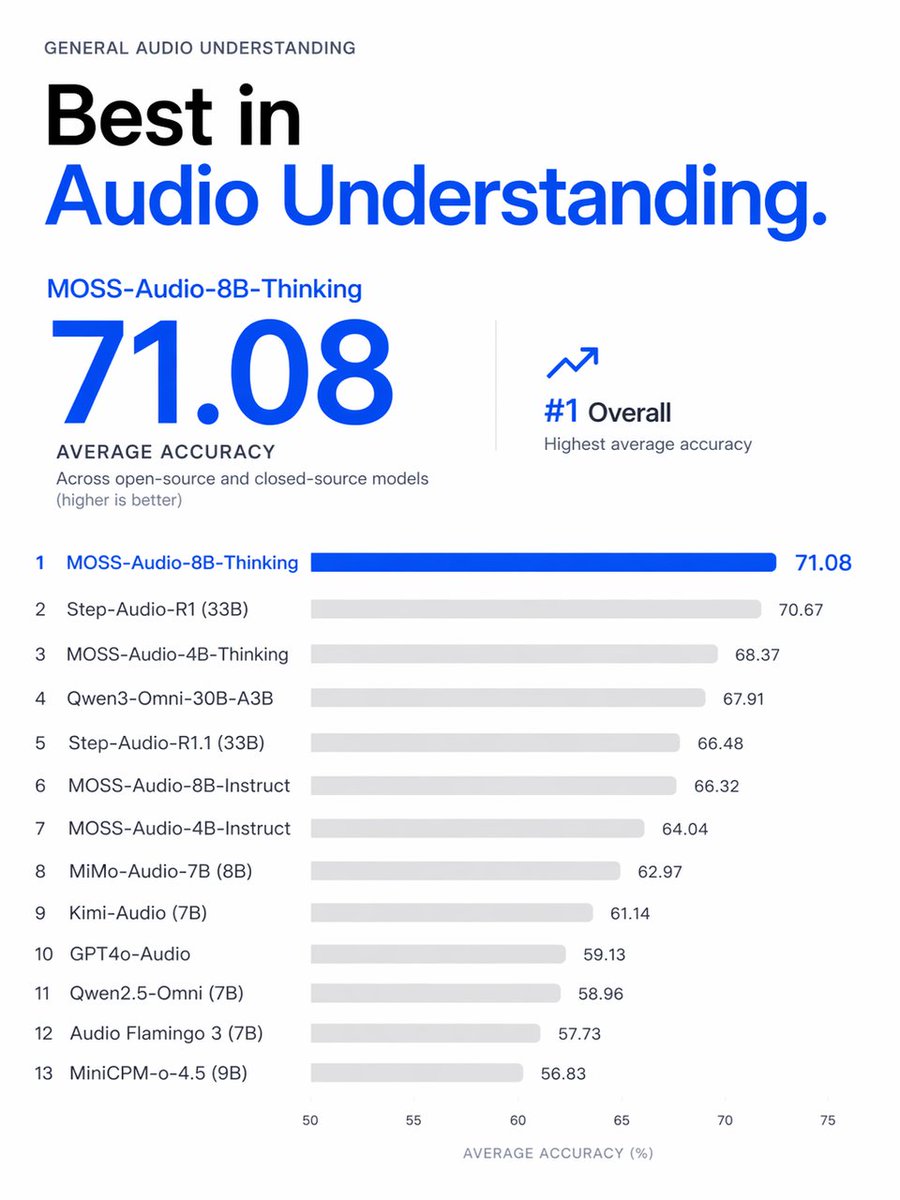




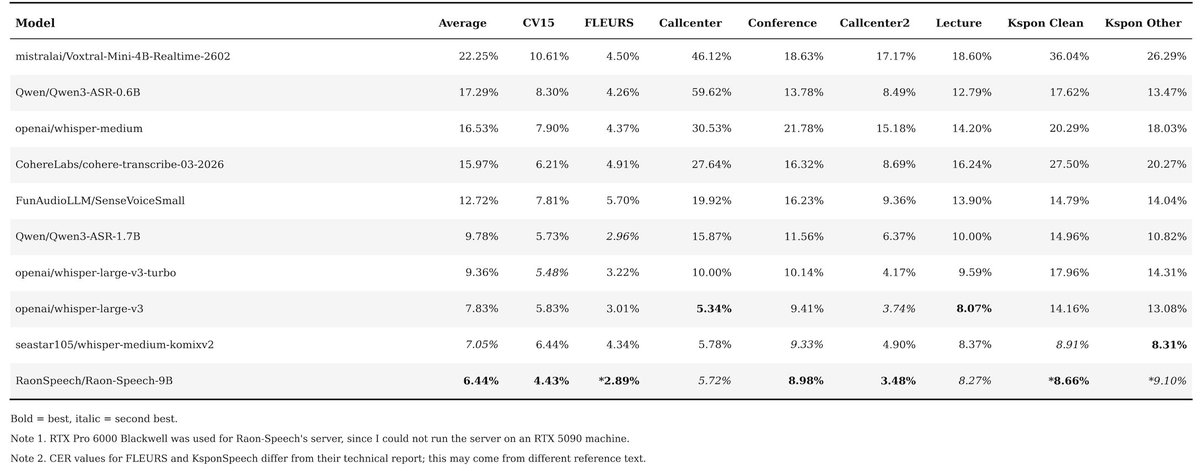
There were various asr model release(qwen3-asr, cohere-transcribe, voxtral-realtime) supporting korean. Real question is "Is it better than Whisper?" So I tested on various korean dataset. github.com/seastar105/oss… And, still whisper-large-v3 is king





Interesting tiny 1.6M params TTS engine, based on StyleTTS github.com/tronghieuit/ti…


