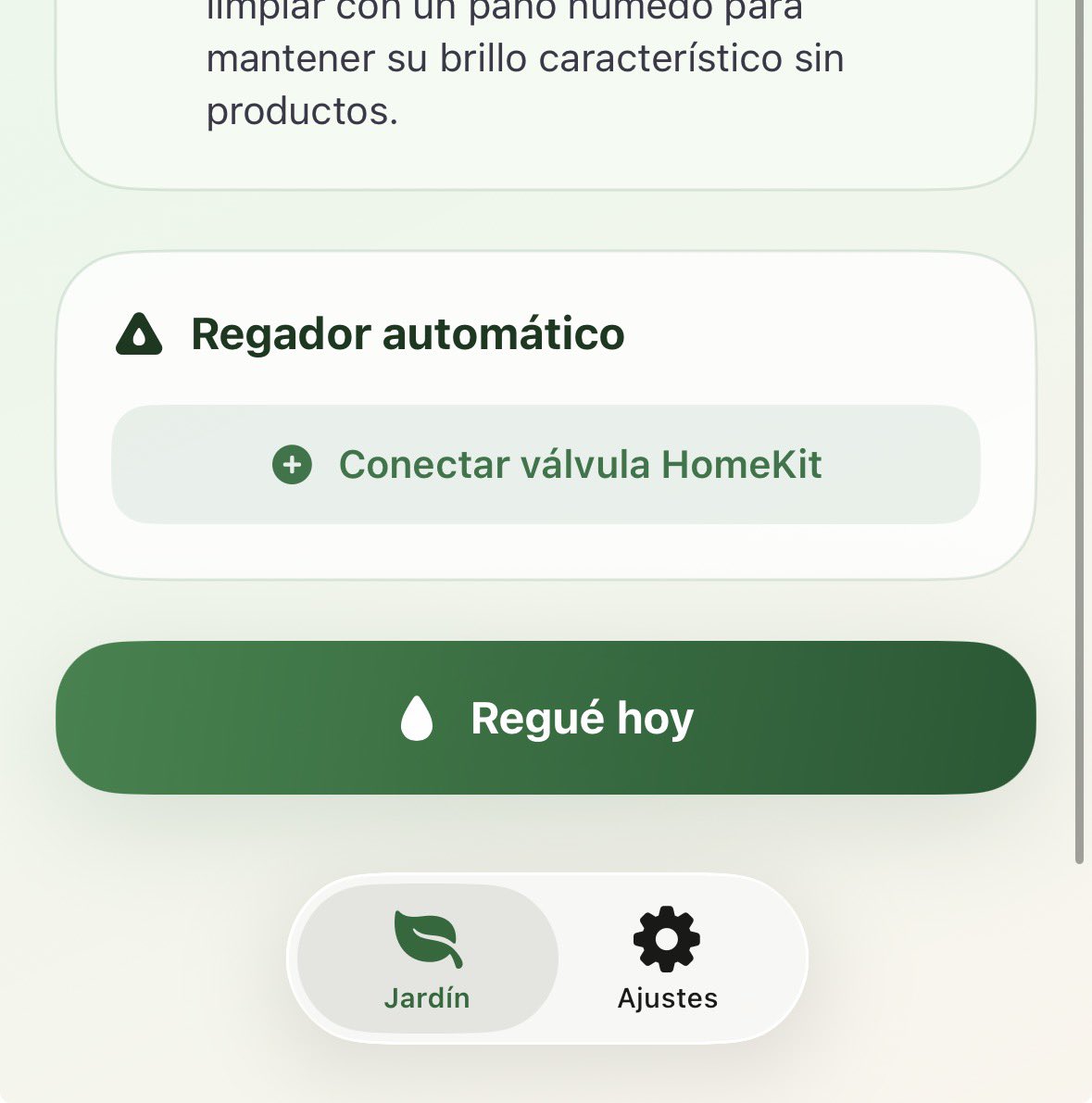
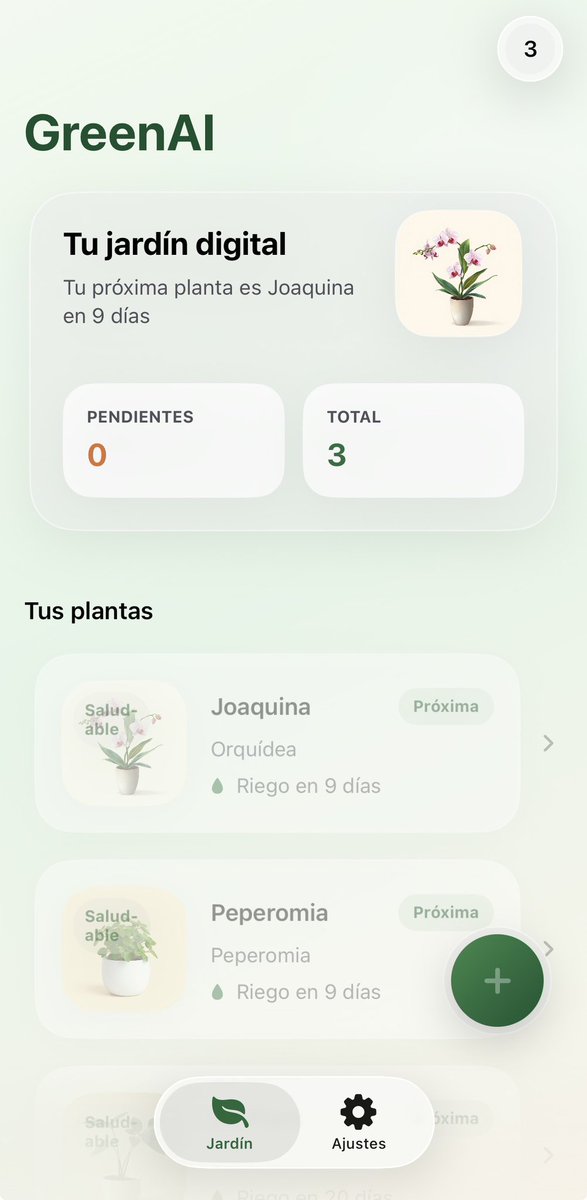
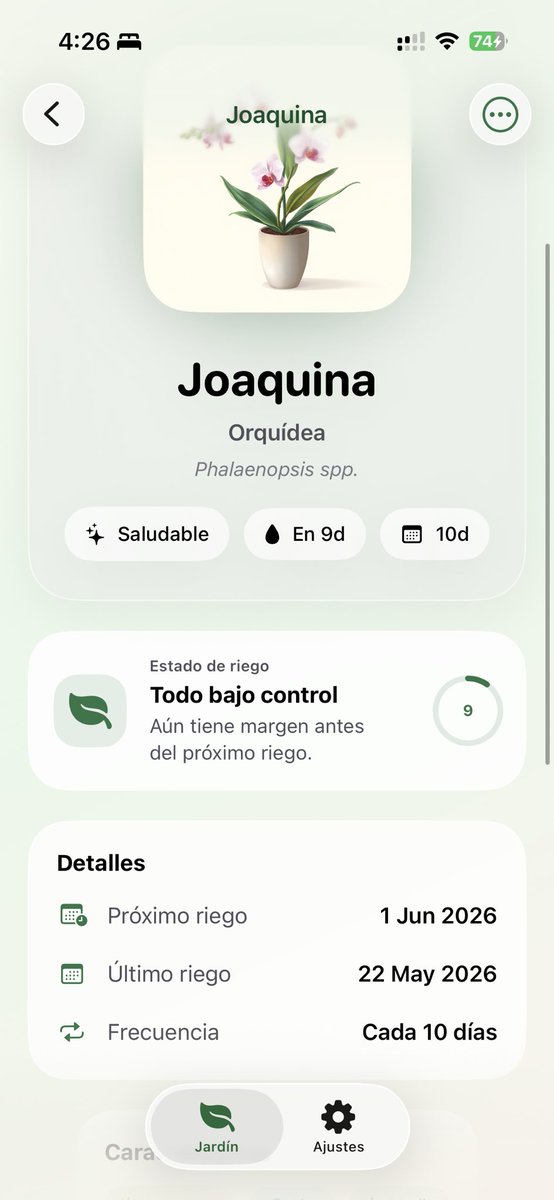
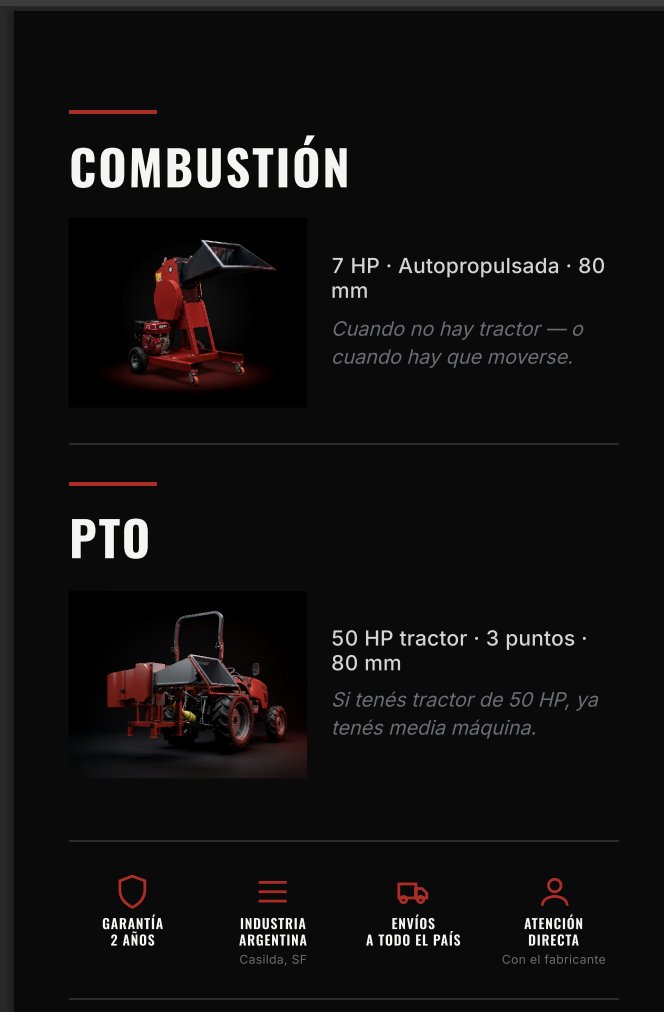
testeando docling con nuextract3, luego voy con langextract
Franco@FrancoDev_
Si tuvieran que extraer data estructurada de cantidades considerables de pdfs -algunos cientos-, cada uno variando de 1 a 30 mb, por qué modelo cost-efficient irían hoy en día?
Español