Sabitlenmiş Tweet

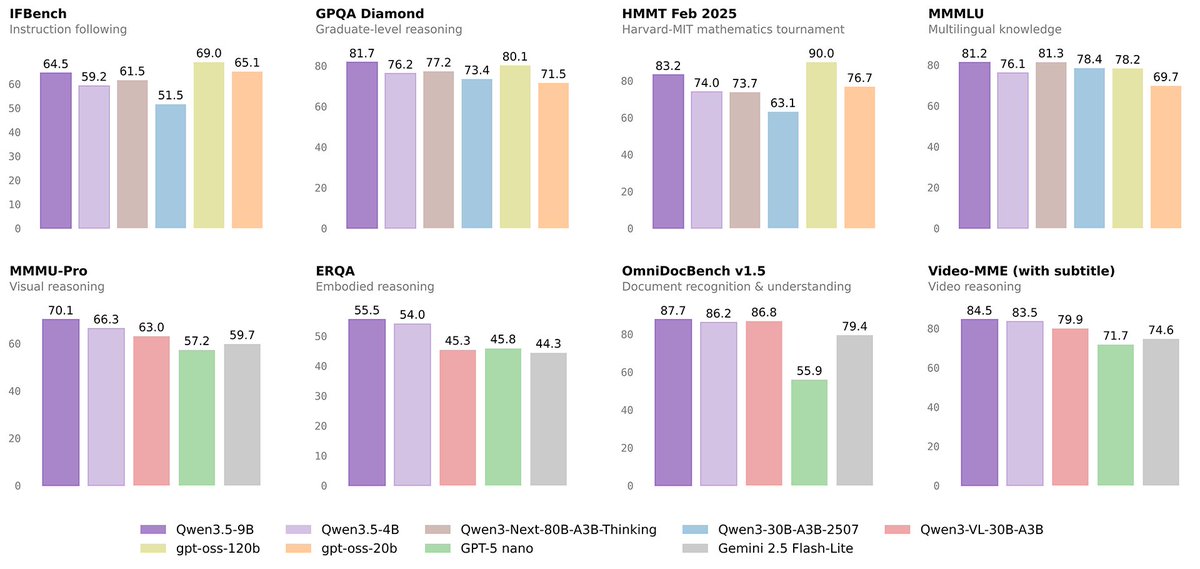
🚀 Excited to share that our paper Fast-ThinkAct has been accepted to #CVPR2026! 🎉
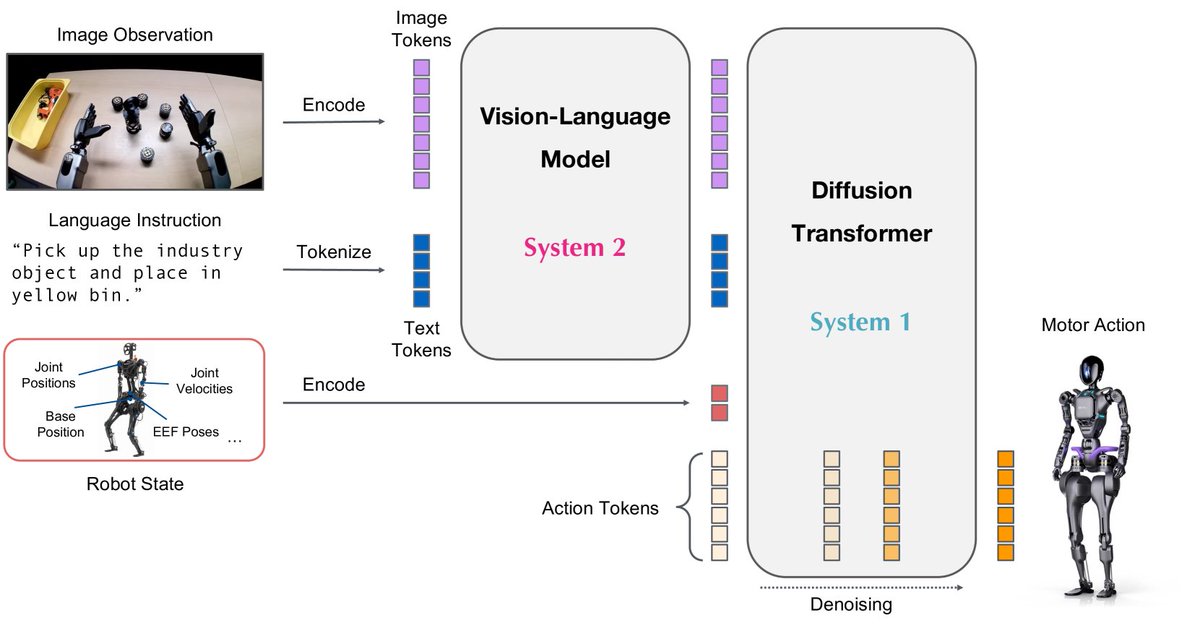
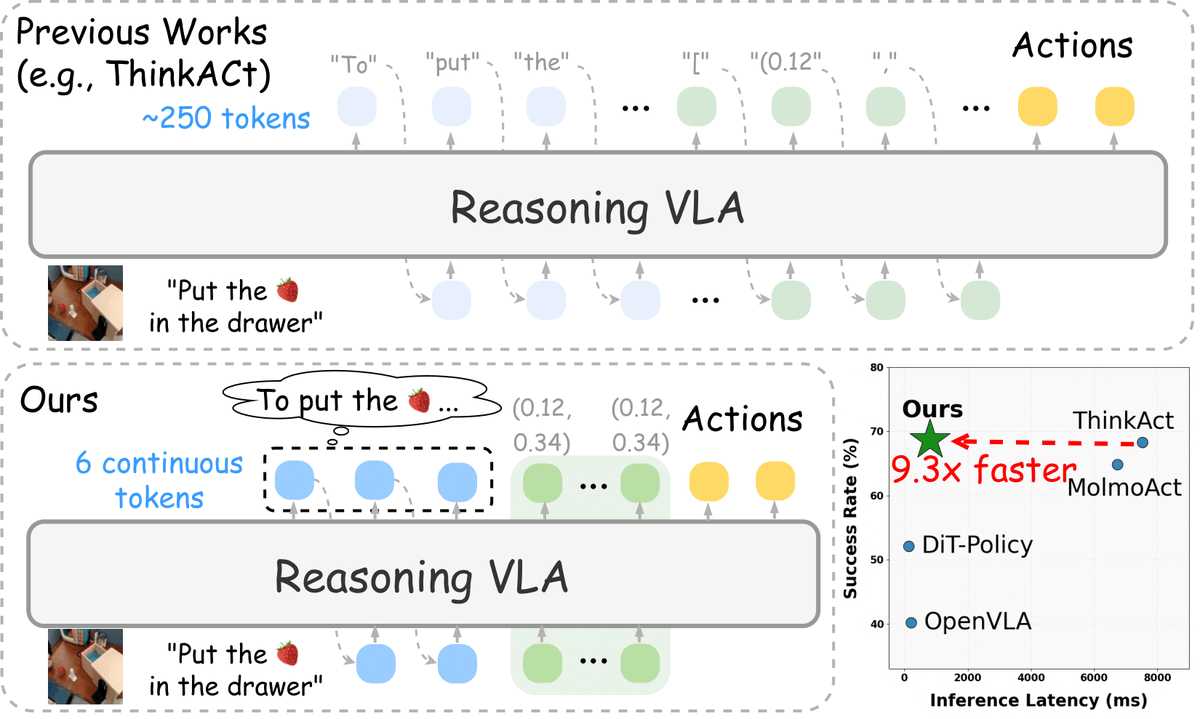
Efficient Vision-Language-Action reasoning via verbalizable latent planning — enabling embodied agents to think fast internally without lengthy textual reasoning.
⚡ Achieves 9.3× faster inference (89% latency reduction) than ThinkAct-7B — bringing Reasoning VLA closer to real-time robotic control.
📄 arxiv.org/abs/2601.09708
🎥 jasper0314-huang.github.io/fast-thinkact/
🙌 Huge congrats to @chipinhxyz, @yunzeman, @ZhidingYu, @CMHungSteven, @jankautz, Yu-Chiang Frank Wang, @FuEnYang1
#EmbodiedAI #PhysicalAI #VLA #Robotics #NVIDIAResearch @NVIDIAAI @NVIDIARobotics
Fu-En (Fred) Yang@FuEnYang1
🤖 How can embodied agents think fast—like humans do internally—without lengthy textual reasoning, and still act effectively? 🚀 Introducing Fast-ThinkAct: compact, efficient, verbalizable latent reasoning for Vision-Language-Action models. Fast think, fast act. 🧠⚡🤲
English