Sabitlenmiş Tweet

Agentic RL environments are becoming critical. We integrated OpenReward (openreward.ai) into Alibaba’s ROLE (alibaba.github.io/ROLL/).
Details: github.com/alibaba/ROLL/p…
English
Shamane Siri | Pluralis
496 posts

@GShamane
Tinkering Transformers | Coding by Day, Hallucinating by Night



300,000 AI builders filled their hardware profile on @huggingface and we're sharing the results: hf.co/hardware. Excited to see how it evolves in the coming months especially with the explosion of local AI!

wow
Some enterprise tasks are challenging to hill-climb with RL-based methods since they involve very out-of-distribution behavior. On-policy self-distillation (OPSD) gives a model learning signal for every token it writes, far richer than the single scalar reward of RL. But that channel is noisy: most tokens don't reflect the behavior you're after. We introduce Relevance-Masked Self-Distillation (RMSD), which uses a two-step filtered loss mask to cut through the noise and find the tokens with the highest signal. Compared to OPSD it trains more stably, provides higher data efficiency, and reaches a higher performance ceiling.



Today we're releasing Agora: the first ever pretraining stack that allows non-collocated consumer GPUs to be competitive with centralized clusters Agora is 15x faster than Megatron-LM in this setting and is only 1.5x less efficient in terms of tokens per unit compute than TorchTitan on H100s, despite running on devices that have no NVLink or InfiniBand support.



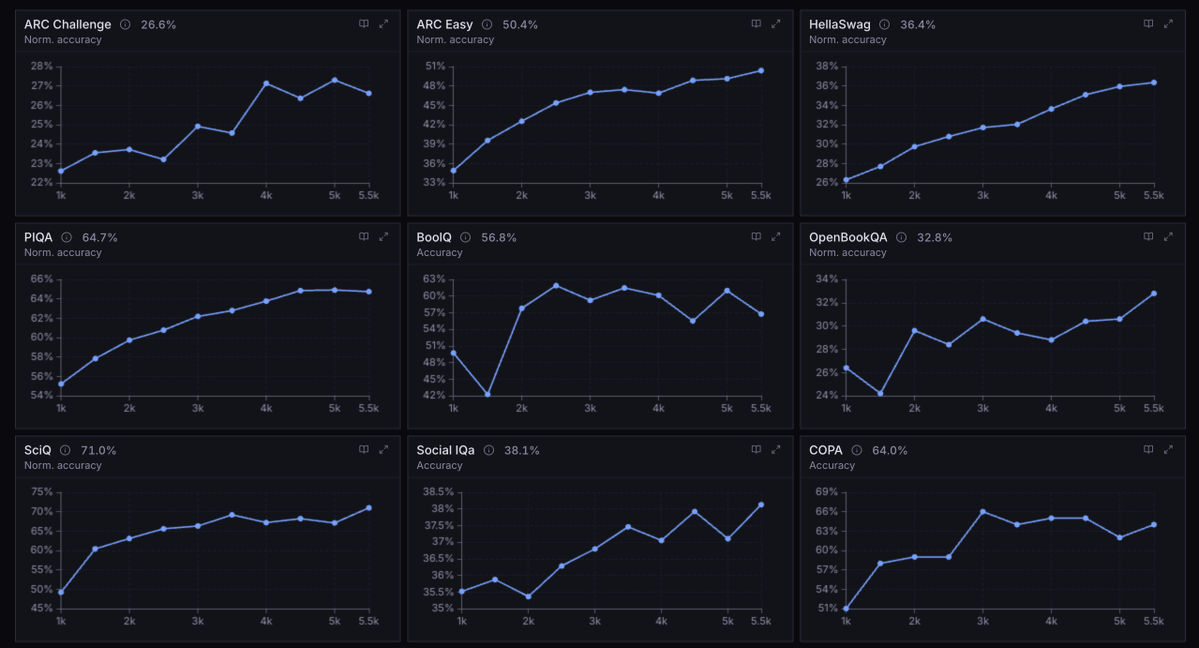
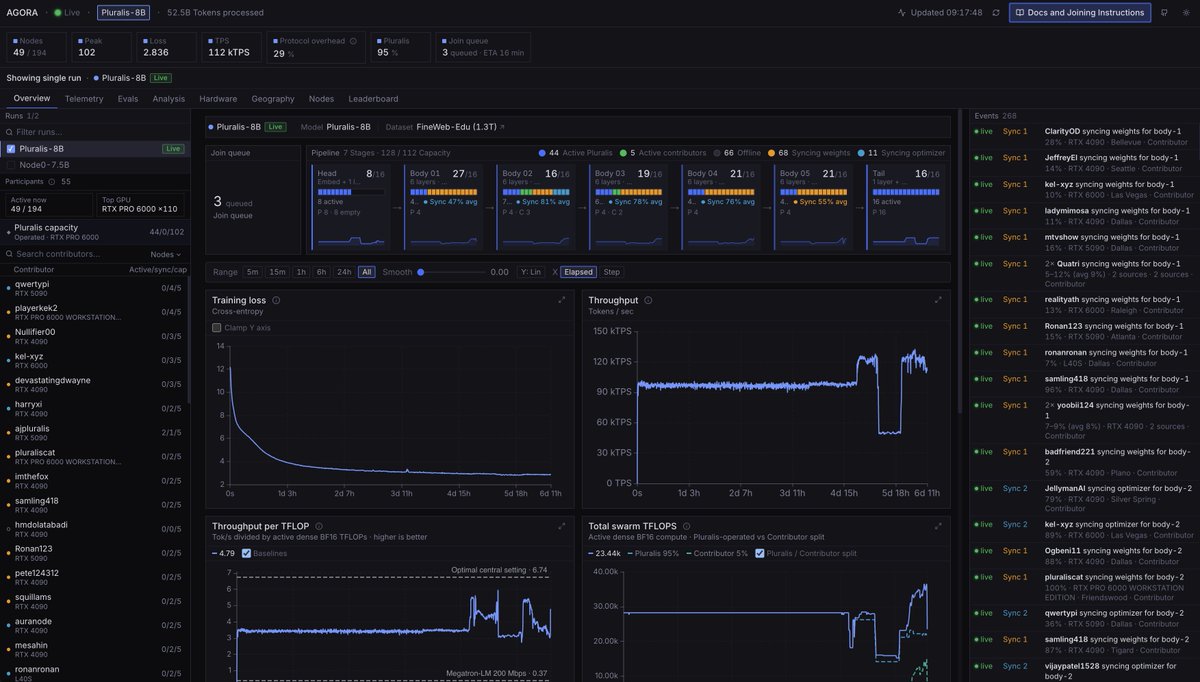

Today we're releasing Agora: the first ever pretraining stack that allows non-collocated consumer GPUs to be competitive with centralized clusters Agora is 15x faster than Megatron-LM in this setting and is only 1.5x less efficient in terms of tokens per unit compute than TorchTitan on H100s, despite running on devices that have no NVLink or InfiniBand support.


Digital agent learning needs massive rollouts. But digital agent rollouts are painfully slow due to heavy environments. 🐌 🚀 We introduce NanoRollout, a lightweight open infra (900 lines core code) for digital agent rollout at scale, validated with three workloads: 🏋️ Large batchsize (4K) SWE Agent RL -> surpasses DeepSWE-32B 🧪 250k+ distilled coding trajectories -> SOTA ≤32B open coding agent ⚡ Fast evaluation on coding/cua/unified agent -> finish Check our Blog: cocoa-org.notion.site/nanorollout



OpenAI has announced they will be winding down fine tuning. I got the email today. Existing active @OpenAI customers can keep running fine-tuning jobs until January 6, 2027, but after that no new training jobs can be created. Existing fine-tuned models will still run, but only until the underlying base model is eventually deprecated. I get the argument that newer models follow instructions much better, and that prompts plus RAG cover more use cases than before. But not all of them.
📝 Agentic RL Infra Notes Insights from Zhihu Contributor 低级炼丹师 📝 🔍 Core Difference: Agentic RL vs Traditional RL • Traditional RL (RLVR): Single-time generation (answer → reward → update) — trains a "response-generating" model, no dynamic interaction. • Agentic RL: Continuous action (tools + context + multi-round interaction) 🚀 — trains an "action-executing" model for real-world dynamic tasks. 🧩 Key Challenge: It’s a System Problem, Not Just Long Sequences 🧩 Core pain points: Agent access (white/black-box), environment management, long-tail rollout, training-deployment consistency. 4 systems solve these! 🛠️ Core Goal (Forge): Maximize Training Gain Formula: Effective Gain = Throughput × Sample Efficiency Constraints: Support any Agent + Stable convergence. 🌟 Core Solution: Separate Agent from RL Framework • Agent = Trajectory producer (handles context/tool calls) • RL System = Collect trajectories + Update models (no Agent simulation!) 🚀 4 Key Systems (1 Sentence Each) • Forge (MiniMax): 3-layer architecture, supports white/black-box Agents & solves TITO inconsistency. • ROLL (Alibaba): Splits Agent/environment/training, optimizes rollout bottleneck with Chunked MDP. • Slime (Zhipu AI): Rollout as HTTP service, fixes TITO mismatch & manages off-policy errors. • Seer (Moonshot): Sync optimization, splits rollout to cut long-tail latency + model-free speculation. ⏳ Key Optimizations • Prefix Tree Merging: Cut duplicate computation from shared trajectory prefixes. • Global KV Cache: Speed up inference for long Agent contexts. • Clean Environment: Avoid reward pollution from residues/test leaks. 🔧 Deep Dive: Key Technical Points • Agent Abstraction Layer: Defines unified interface (Observation → Action) to adapt white-box (customizable weights) & black-box (API-only) Agents, ensuring framework compatibility. • Rollout Optimization: Chunked MDP splits long trajectories into manageable chunks; asynchronous rollout decouples Agent execution from training, reducing latency. • TITO Consistency: Aligns training (Train)、inference (Infer)、test (Test)、online (Online) environments/Agent versions to avoid performance degradation after deployment. • Off-Policy Data Management: Uses replay buffer with priority sampling to filter low-quality trajectories, improving sample efficiency; Slime’s HTTP-based rollout ensures data traceability. • Context Efficiency: Global KV Cache reuses shared context prefixes; Prefix Tree Merging eliminates redundant computation in multi-branch trajectories. ⚠️ Common Pitfalls & Avoidance Tips • Over-Optimizing Throughput: Ignoring sample efficiency leads to wasted computing resources — balance throughput with priority trajectory sampling. • Neglecting TITO Mismatch: Training on offline data but deploying to inconsistent online environments causes performance drop — align all four environments (Train/Infer/Test/Online) upfront. • Agent Over-Simulation: Simulating Agent logic in RL framework increases complexity — stick to decoupling (Agent = trajectory producer, RL = training/collection). 📌 Practical Application Scenarios • Tool-Using Agents: E-commerce customer service (multi-round tool calls: order query → refund processing) — relies on rollout optimization & context efficiency. • Autonomous Decision-Making: Industrial control (dynamic adjustment based on real-time data) — benefits from TITO consistency & off-policy data management. 🎯 Epilogue ✅ Agentic RL infra = Decouple Agent + Optimize rollout + Ensure stability Let’s build better Agentic RL infra together! 🌍 🔗 Highly recommend you to read the full article: zhuanlan.zhihu.com/p/202278614808… #AgenticRL #AI #ROLL #Agent
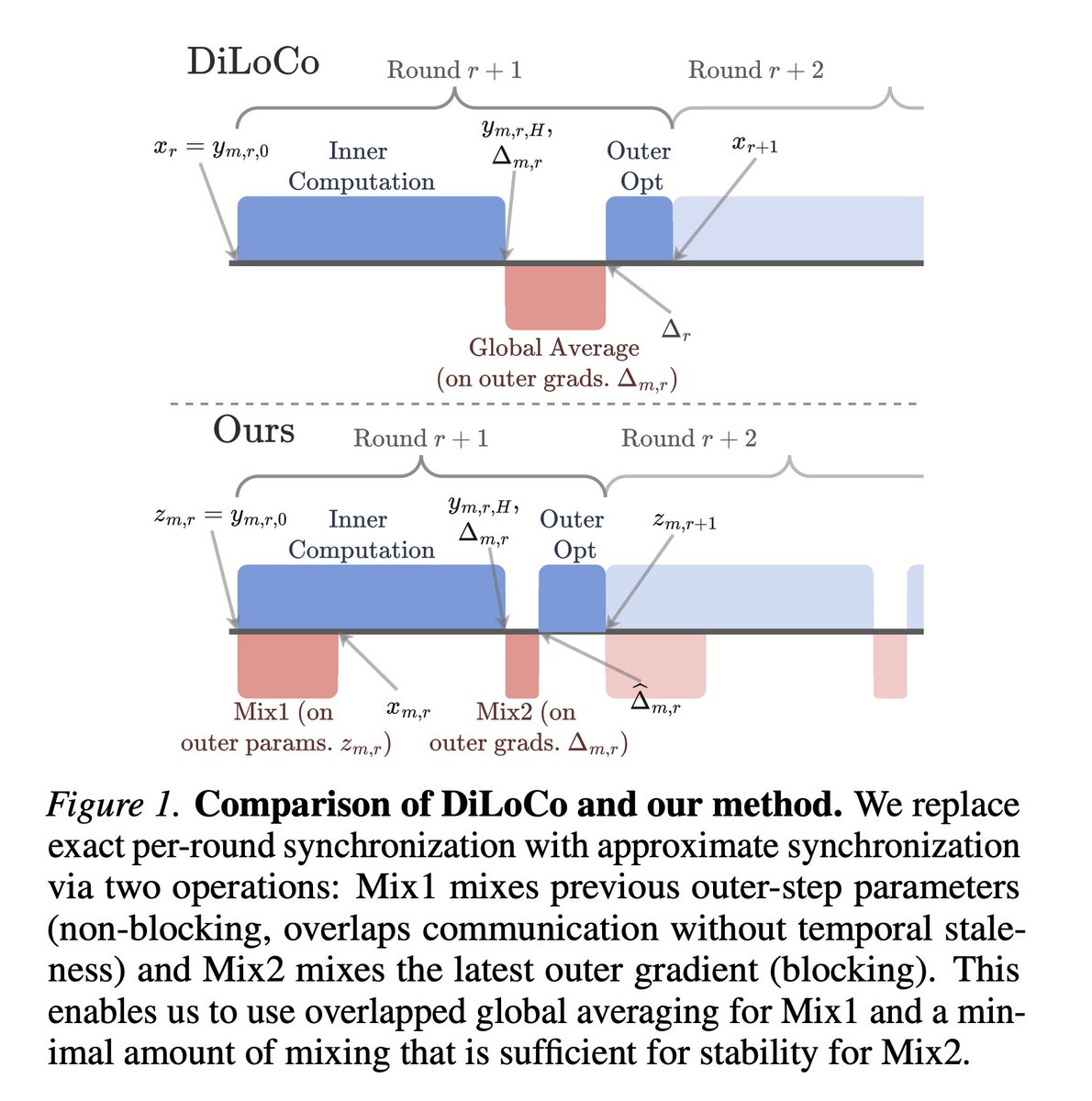

I gave a talk at ICLR 2026 about how we are scaling RL on frontier LLMs with 1T+ parameters, on experimental data from our physical lab at Periodic! Here's a rough recording of the talk:


I gave a talk at ICLR 2026 about how we are scaling RL on frontier LLMs with 1T+ parameters, on experimental data from our physical lab at Periodic! Here's a rough recording of the talk:
