Sabitlenmiş Tweet

No training needed!
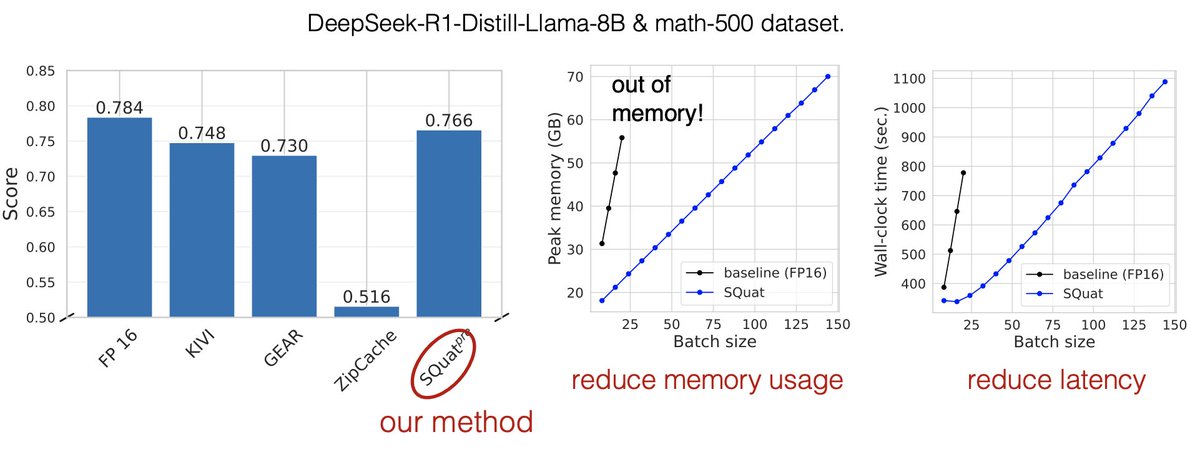
While improve your SLM to o-1 level math performance with particle filtering based inference scaling 🎊
Paper, code, and blogpost are all released 🔥
If this interesting to you, please like share, comment to support open-sourcing cutting-edge AI at RedHat!
Isha Puri@ishapuri101
[1/x] can we scale small, open LMs to o1 level? Using classical probabilistic inference methods, YES! Joint @MIT_CSAIL / @RedHat AI Innovation Team work introduces a particle filtering approach to scaling inference w/o any training! check out …abilistic-inference-scaling.github.io
English