
Hanhan
28 posts










I tested Kimi-K2.6 for few hours today.
It is way better than k2.5 or GLM5.1
It can do almost anything that Claude does.
Open-source will win.
English

OpenAI 这昨天才端出来了 GPT Image2 让大家眼前一亮,这是又打算接连推出 GPT-5.5 啦?
能干翻 Claude Opus4.7 吗?🤣
中文

套壳Kimi 的Cursor卖了SpaceX 600亿美金,而Kimi的母公司月之暗面现在估值180亿美金。
市场热度在变,从Web3到AI,不变的是中美的估值悬殊。
中文

@bridgemindai This is meaningless. I'm in China, and almost all domestic large models overfit on test projects but are useless in actual production tasks.
English

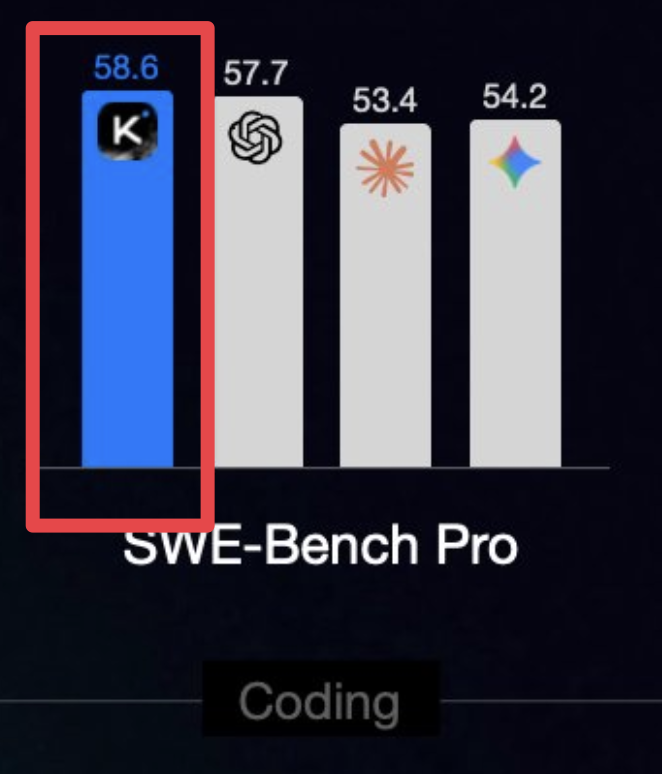
Kimi K2.6 just dropped.
And it crushed Claude Opus 4.6 on SWE-Bench Pro.
Kimi K2.6: 58.6
GPT-5.4 xhigh: 57.7
Gemini 3.1 Pro: 54.2
Claude Opus 4.6: 53.4
An open source Chinese model is now #1 on agentic coding.
Frontier labs have a problem.
English




@Russell3402 Most Agent tools first support Mac, and recently, the cost-performance of Mac has also significantly caught up
English

@Liuran_yanagi I originally mainly used Claude, but when it didn't meet my expectations, I tried Codex, and it has been able to surprise me, so I have completely switched to Codex recently.
English

@Moting284 Liberal arts students and science students don't have much of a fundamental difference. The key still lies in logical ability and insight into the world.
English


Bro to Bro: build your x account
Just say “hello” and gain 800 mutuals here.

English
@Jackywine I'm increasingly liking Codex, especially after Claude keeps getting worse.
English


@marmaduke091 Very looking forward to Image2, but even as a $200/month GPT Pro subscriber, I haven't received the grayscale test version yet.
English

@Anas_founder I have a Mac mini m4 Pro, it only cost me 8000 RMB, it's simply the best product in the world
English


