
Alfc Oleol
41 posts


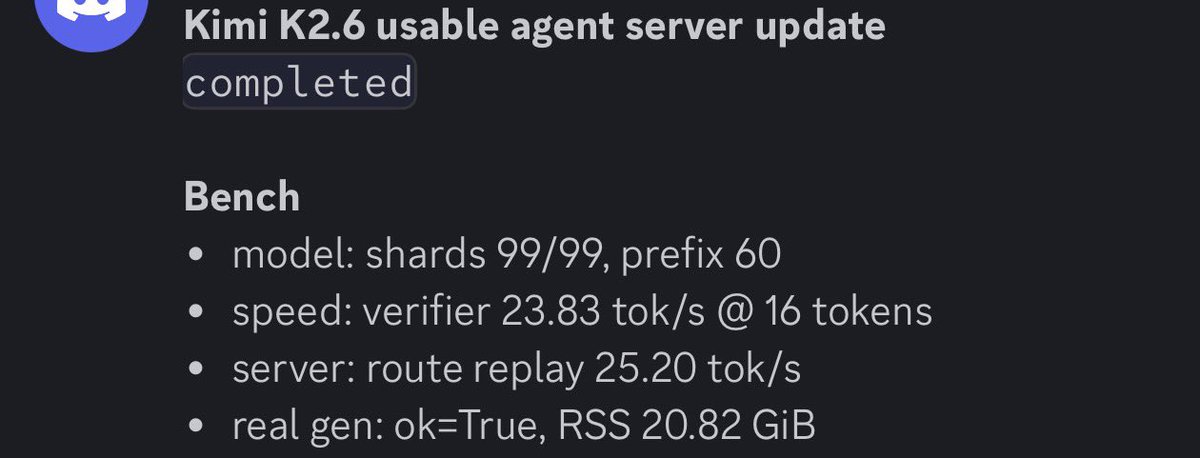
Working on only loading MoE expert on GPU,
25tok/s on very short context right now
English
Running Kimi-k2.6 1T 8bit with only 21GB RAM on my Macbook at speed of 25tok/s.
Some of my theory worked, but architecture is not perfect.
Need to fix a lot of stuff, but there is hope.
Working hard on this future method of Local LLM.
English

@Hesamation rebranding as thinking machines just to ship a gpt-4o clone is the ultimate 2026 tech move. we’re officially in the 're-skinning 2024' era and nobody’s even trying to hide the wrappers anymore
English

WAIT WAIT WAIT. is anyone gonna talk about the fact how Thinking Machines demo looks insanely similar to GPT 4o demo from 2 YEARS AGO?
Thinking Machines@thinkymachines
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way. We share our approach, early results, and a quick look at our model in action. thinkingmachines.ai/blog/interacti…
English





ive got myself in a bit of a predicament.
i have an insane line up of new features basically all ready
- opencode, pi, claude
- new QUIC qr code type of connection type thats a lot better for mobile
- file picker to mount dirs from Files
- a bunch of updates for the local linux
but the kitty app is pretty good right now and i dont wanna mess up the experience while these are being tested
the issue is that ive got an open TestFlight and android beta and there are already like 3000 people in it, a lot of them using it regularly.
i need to somehow get the people who dont understand that this is for testing off the test channels
English
@SIGKITTEN Why not use fork of ish like ish-arm64 for more performance?
English
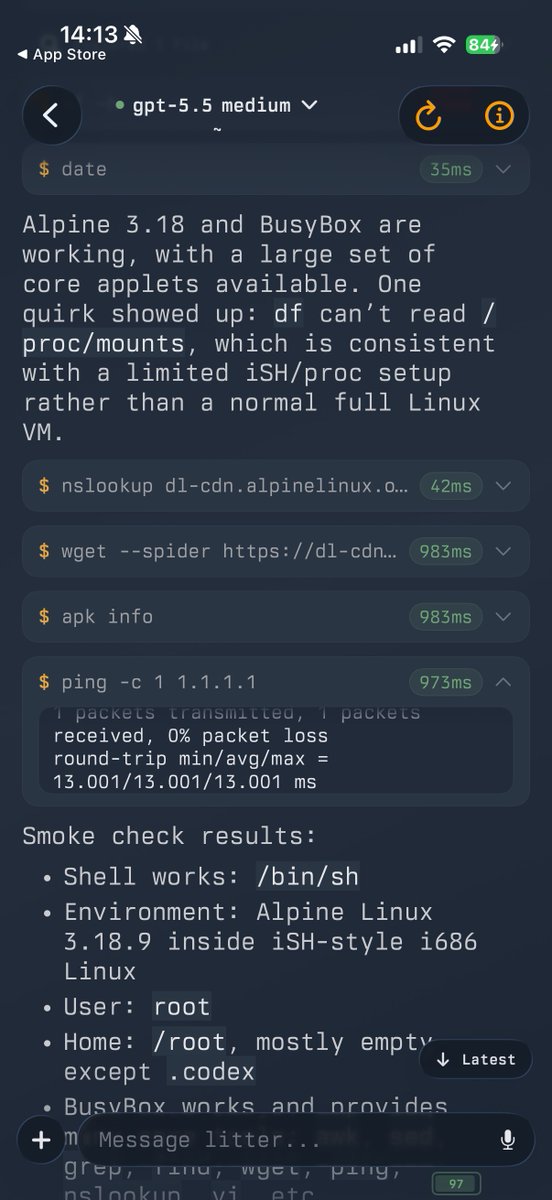
HAAH AHAH AH HAHAH
i fkn got codex with full linux on the app store

SIGKITTEN@SIGKITTEN
come on apple
English

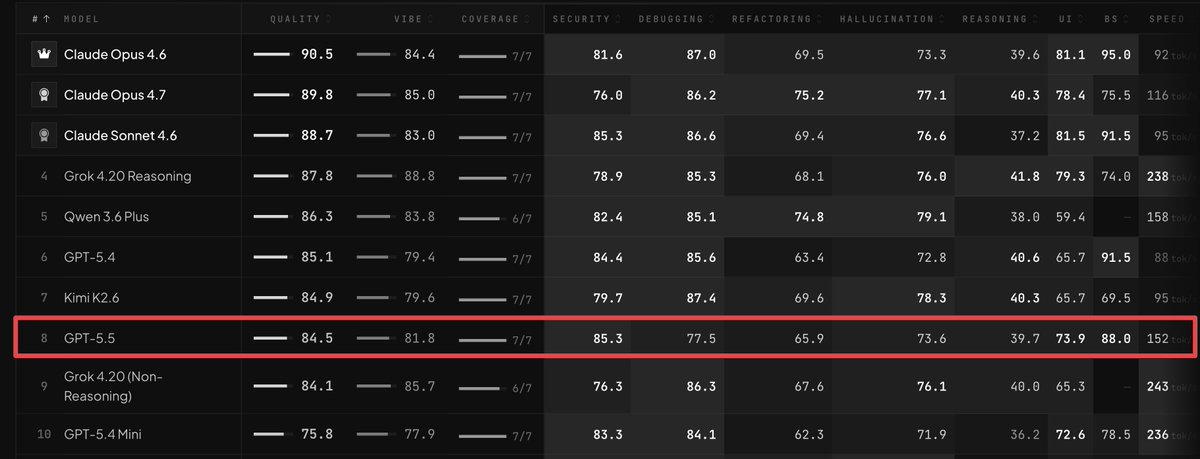
GPT 5.5 just debuted on BridgeBench.
It ranks below GPT 5.4.
Read that again.
The "most intelligent model ever built" scores worse than its predecessor on real world vibe coding.
#8 overall. 84.5 quality.
GPT 5.4 sits at #6 with 85.1.
Behind Claude Opus 4.6. Behind Claude Opus 4.7. Behind Claude Sonnet 4.6. Behind Grok 4.20. Behind Qwen 3.6 Plus.
The smartest model in the world is not the best coding model in the world.
BridgeBench just proved it.
bridgebench.ai
English
@neural_avb Why with this logic you dont use Minimax M2.7 (230B-A10B)
Only 10B active parameters man! Better then deepseek v4 flash and grok
English

Honest thoughts:
- Qwen-27B is a 27B param dense model, Deepseek Flash is a MoE model with 13B active params... It will also run faster if you are able to fit it in your gpu
- Larger models 100% hold way more world knowledge
- I trust no benchmarks these days, they feel gamed
Base Camp Bernie@basecampbernie
Deepseek V4 Flash 284B is just one point better than qwen3.6 27B .. @alibaba @Alibaba_Qwen and a 3090
English
@basecampbernie @Alibaba @Alibaba_Qwen Why with this logic you dont use Minimax M2.7 (230B-A10B)
Only 10B active parameters man! Better then deepseek v4 flash and grok
English

Deepseek V4 Flash 284B is just one point better than qwen3.6 27B .. @alibaba @Alibaba_Qwen and a 3090

English

We are committed to continually improving the GPT Image 2 model! I am actively fixing various issues from the community feedback. Just reply or DM me your GPT conversation! Features like 2K or 4K images are already available via the experimental API. Hope you enjoy the model!

English

GPT-Image-2 is fundamentally broken and should not have been released in this state. The noise artifact issue is no joke. It affects all images, some more than others, and the problem is amplified by iterative editing.
English
GPT-Image-2 has image quality issues, and nobody is talking about them... Except me. So the image is slightly grainy, fuzzy, and also low resolution (1K). Nano Banana 2 is better in that regard. After the initial hype you will see that other people start noticing it too.
English

Validated MoE Prefill dedup algo for GLM-5.1, Kimi K2.5, Qwen 3.5, Gemma4, MiniMax-2.7. See 4K prefill below
Branch/doc
github.com/Anemll/anemll-…
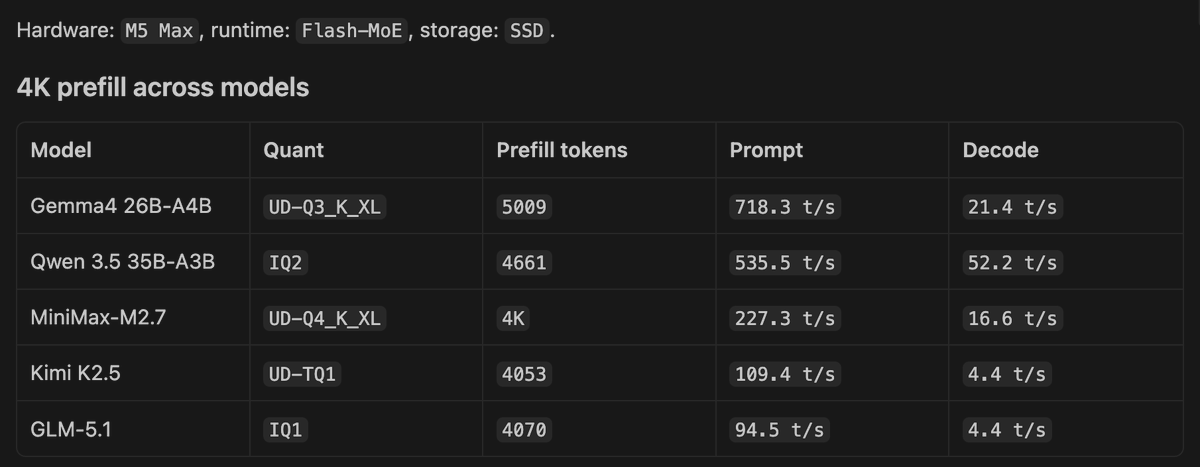
Anemll@anemll
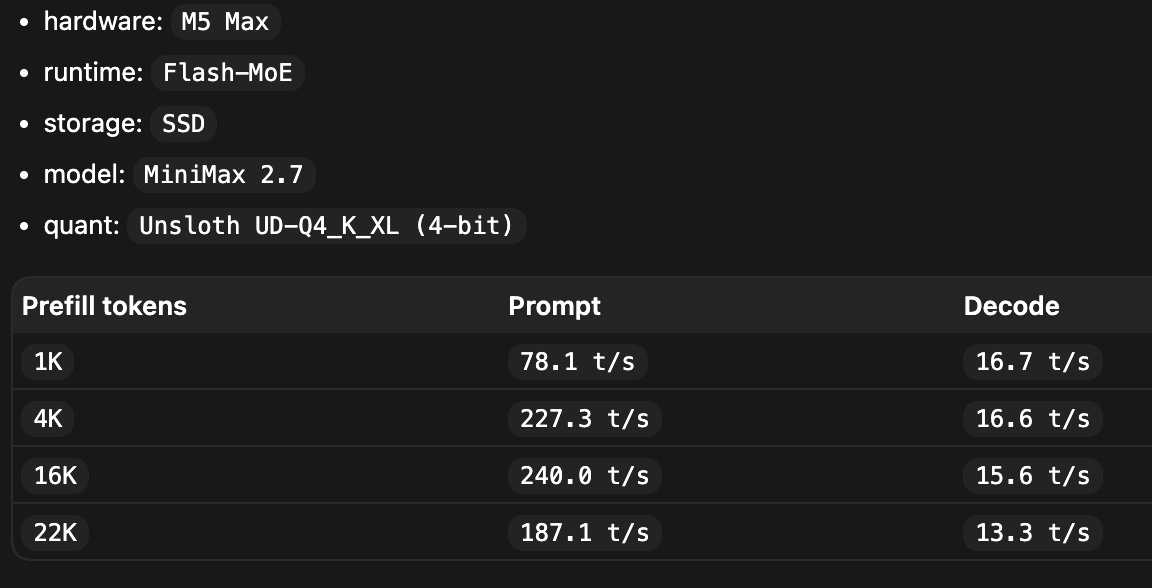
WIP: Merged: prefill dedup for Flash-MoE. MiniMax only for now while I validate the other models Layer-major prefill runs one layer at a time, groups repeated expert picks across the prefill chunk, loads each unique expert from SSD once, and reuses it for every token that picked it , instead of reloading per token. Bigger prefill chunk → more reuse → cheaper prefill. Prefill is now compute-bound, not I/O-bound. That should help both GPU and ANE prefill at large batch sizes. Can we speedup regular MoE MLX prefill 🤔 github.com/Anemll/anemll-…
English
WIP: Merged: prefill dedup for Flash-MoE. MiniMax only for now while I validate the other models
Layer-major prefill runs one layer at a time, groups
repeated expert picks across the prefill chunk, loads each unique expert from SSD once, and reuses it for every token that picked it , instead of reloading per token.
Bigger prefill chunk → more reuse → cheaper prefill.
Prefill is now compute-bound, not I/O-bound.
That should help both GPU and ANE prefill at large batch sizes. Can we speedup regular MoE MLX prefill 🤔
github.com/Anemll/anemll-…
English


Honestly this chart makes me more bullish on GPT 5.4 Pro than anything else.
People are focusing on Mythos looking strong, but what stands out to me is how well 5.4 Pro already stacks up on the overlap we actually have. GPQA is basically a tie at 94.4 vs 94.5. BrowseComp is a win for GPT 5.4 Pro at 89.3 vs 86.9. Yes, Mythos is ahead on Humanity’s Last Exam, 56.8 vs 42.7 without tools and 64.7 vs 58.7 with tools, but the bigger point is that 5.4 Pro is already this competitive right now.
So if GPT 5.4 Pro is already THIS COMPETITIVE here, then Spud Pro, the next OpenAI flagship, is guaranteed to beat Mythos. This chart makes OpenAI look extremely close before its next real jump, and once that next jump lands I do not think Mythos stays ahead.

English

Grok 4.20 Reasoning just took the #1 spot on the BridgeBench reasoning benchmark. 🔥
Beating GPT-5.4, Claude Opus 4.6, Google Gemini and others.
Week after week, Grok keeps climbing across benchmarks. 🚀
English
@svpino Its bug, find fixed llama cpp fork with usable tool calling with gemma 4
English

I'm running Gemma 4 on my computer with Ollama.
Unusable with Claude Code. It can't even load and execute skills, so I had to stop.
But the model is pretty decent as a chatbot using the Ollama UI. I've been cross-posting questions across Claude and Gemma 4, and I can use Gemma's answers without any problems.
I wish we had a better UI harness for the model (with projects, memory, etc.)
English
