Sabitlenmiş Tweet

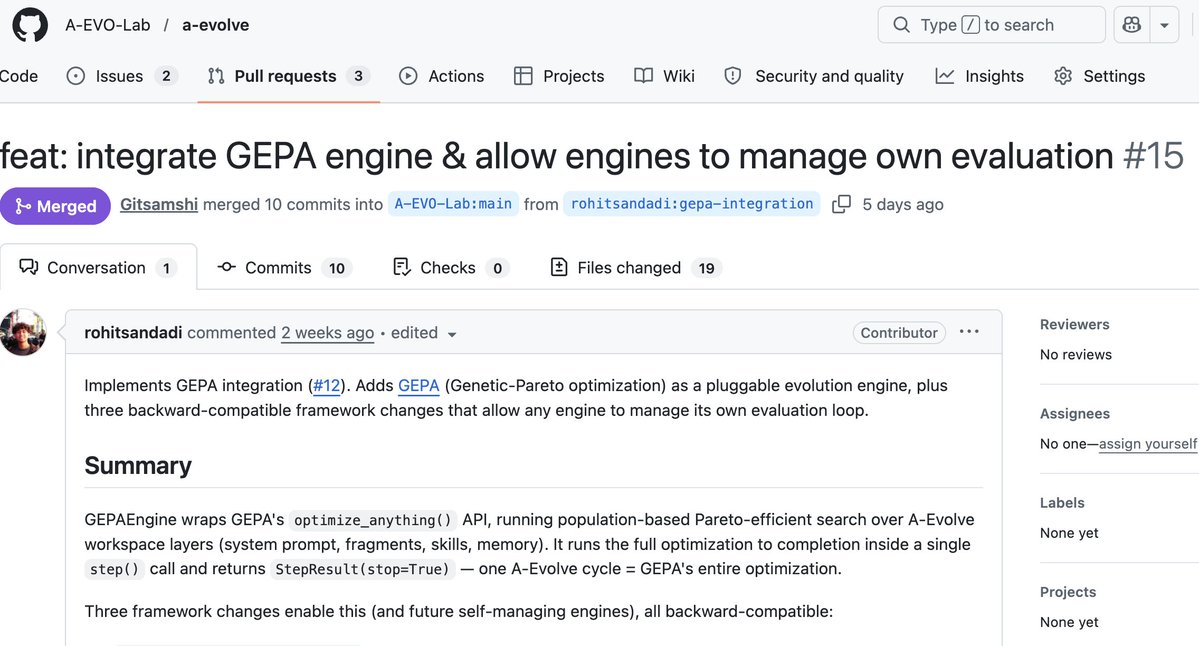
🚀 Big update: @gepa_ai has now been officially integrated into A-Evolve (by community member)!
We added GEPA as a new pluggable evolution algorithm inside A-Evolve.
This makes it even easier for any agent to leverage GEPA’s capabilities with zero extra setup — just plug and let the agent self-evolve. And also make it easy to compare GEPA with other self-evolve algorithms including MetaHarness, A-Evolve.
(Full integration details + results in the reply below 👇)
#AgenticAI #AEvolve #SelfImprovingAgents #GEPA
Henry Lu@HenryL_AI
Launch Post🧬 A-Evolve: The PyTorch Moment for Self-evolving AI Today we at @amazon launch the universal infrastructure that turns any agent into a self-improving SOTA agent — zero human intervention. You give it a base agent → it returns a continuously evolving Top-10 agent. 3 lines of code. 0 hours of manual harness engineering: 🟢 MCP-Atlas → 79.4% (#1) +3.4pp 🔵 SWE-bench Verified → 76.8% (~#5) +2.6pp 🟣 Terminal-Bench 2.0 → 76.5% (~#7) +13.0pp 🟡 SkillsBench → 34.9% (#2) +15.2pp Thanks @binghe2727 @YisiSang @sammyershi @linminhua16 for the contribution! #AgenticAI #AEvolve #SelfImprovingAgents
English