English
⚡🛡️ Evan Pappas
6.7K posts

@Hevalon
🛡️ Ex Technologia Libertas - Έλευθερία διὰ τῆς τέχνης - (Dec/Acc)


On the @theallinpod this week, @chamath asked @nvidia CEO Jensen Huang about decentralized AI training, calling our Covenant-72B run "a pretty crazy technical accomplishment." One correction: it's 72 billion parameters, not four. Trained permissionlessly across 70+ contributors on commodity internet. The largest model ever pre-trained on fully decentralized infrastructure. Jensen's answer is worth hearing too.




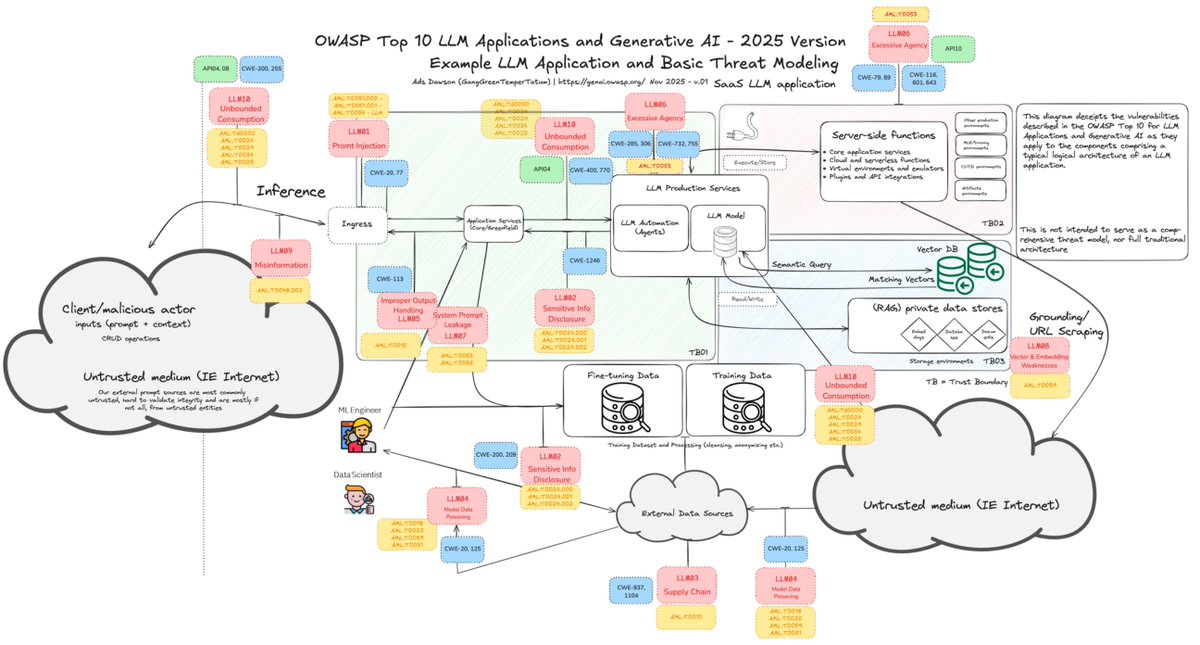
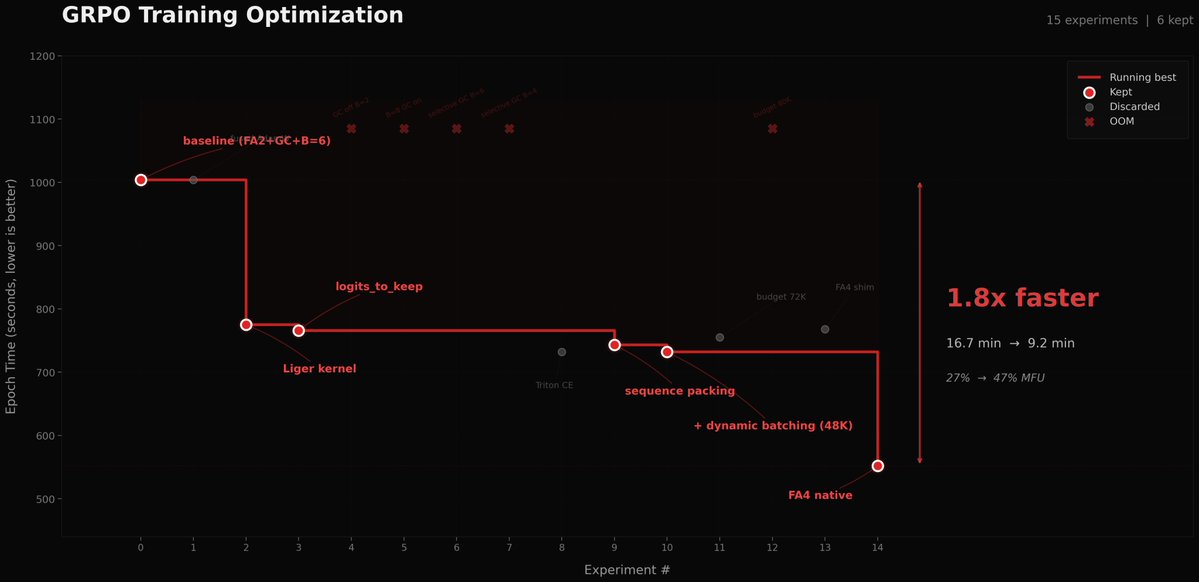
Used autoresearch to make @grail_ai GRPO trainer 1.8x faster on a single B200. I kept postponing this for weeks since the bottleneck in our decentralized framework was mainly communication. But after our proposed technique, PULSE, made weight sync 100x faster, the training update itself became the bottleneck. Even with a fully async trainer and inference, a slow trainer kills convergence speed. A task that could've eaten days of my time ran in parallel while I worked on other stuff. Unlike original autoresearch, where each experiment is 5 min, our feedback loop is way longer (10-17 min per epoch + 10-60 minutes of installations and code changes), so I did minimal steering when it was heading in bad directions to avoid burning GPU hours. The agent tried so many things that failed. But, eventually found the wins: Liger kernel, sequence packing, token-budget dynamic batching, and native FA4 via AttentionInterface. 27% to 47% MFU. 16.7 min to 9.2 min per epoch. If you wanna dig deeper or contribute: github.com/tplr-ai/grail We're optimizing everything at the scale of global nodes to make decentralized post-training as fast as centralized ones. Stay tuned for some cool models coming out of this effort. Cheers!


TGIF #29 tomorrow! The Covenant-72B thread reached well beyond Bittensor this week. @DistStateAndMe and the full @covenant_ai team talk about what that traction means, where decentralized AI sits in the broader conversation, and what comes next. Miners, come celebrate with us. We are opening the stage to anyone who contributed compute to the run or has a story to share. Request to speak and we will bring you up. x.com/i/spaces/1oKMv…


We just completed the largest decentralised LLM pre-training run in history: Covenant-72B. Permissionless, on Bittensor subnet 3. 72B parameters. ~1.1T tokens. Commodity internet. No centralized cluster. No whitelist. Anyone with GPUs could join or leave freely. 1/n
We just completed the largest decentralised LLM pre-training run in history: Covenant-72B. Permissionless, on Bittensor subnet 3. 72B parameters. ~1.1T tokens. Commodity internet. No centralized cluster. No whitelist. Anyone with GPUs could join or leave freely. 1/n

Seven subnet ideas are heading to testnet, backed by @basilic_ai compute credits. Basilica sponsors the Ideathon because the best way to validate a subnet design is to run it, and compute should not be the bottleneck. Congratulations to all the teams advancing.