
Hongwu Peng
147 posts
Hongwu Peng
@Hongwu_Peng
Foundation model pretraining @Adobe Research Ph.D. @ UConn CSE. https://t.co/FPAiorbsK3
Katılım Eylül 2023
491 Takip Edilen113 Takipçiler

Let's do the KV cache math for Qwen3.5:
- KV heads: 2
- Head dimension: 256
- gated attention layers: 15
- bytes per element (BF16): 2
2 x 256 x 15 x 2 = 15 360
This is the same for K and V.
So, we multiply by 2: 30 720 bytes
Roughly 31 kb per token of context.
Meaning at max context length (262144):
30 720 x 262 144 = 8.05 GB
So at max context length, Qwen3.5 will only consume 8.05 GB, or 4.025 GB if quantized to FP8.
It's small, and it's thanks to the use of 45 gated deltanet layers.
If all 60 layers were normal attention layers, the full sequence would consume 32 GB.
English
Hongwu Peng retweetledi

An exciting new approach for doing continual learning, using nested optimization for enhancing long context processing.
Google Research@GoogleResearch
Introducing Nested Learning: A new ML paradigm for continual learning that views models as nested optimization problems to enhance long context processing. Our proof-of-concept model, Hope, shows improved performance in language modeling. Learn more: goo.gle/47LJrzI @GoogleAI
English
@elonmusk @iScienceLuvr For fair comparison, the paper should apply text augmentation into AR LLMs for multi-epoch training, not just overfitting the AR LLM and claim it doesn't work well
English


Diffusion Language Models are Super Data Learners
"when unique data is limited, diffusion language models (DLMs) consistently surpass autoregressive (AR) models by training for more epochs."
"At scale, a 1.7B DLM trained with a ∼ 1.5T - token compute budget on 10B unique Python tokens overtakes an AR coder trained with strictly matched settings. In addition, a 1B-parameter DLM achieves > 56% accuracy on HellaSwag and > 33% on MMLU using only 1B tokens, without any special tricks, just by repeating standard pre-training data."

English
Hongwu Peng retweetledi

🚀 NorMuon: Muon + Neuron-wise adaptive learning rates: +21.7% training efficiency vs Adam, +11.3% vs Muon on 1.1B pretrain.
🚀 Distributed Normuon: A highly efficient FSDP2 implementation.
Paper 👉 arxiv.org/abs/2510.05491
#LLM #AI #DeepLearning #Optimizer


English
Hongwu Peng retweetledi

Wow, pretty cool that they also open sourced a FSDP2 compatible Muon and PolyNorm working with @huggingface kernels!
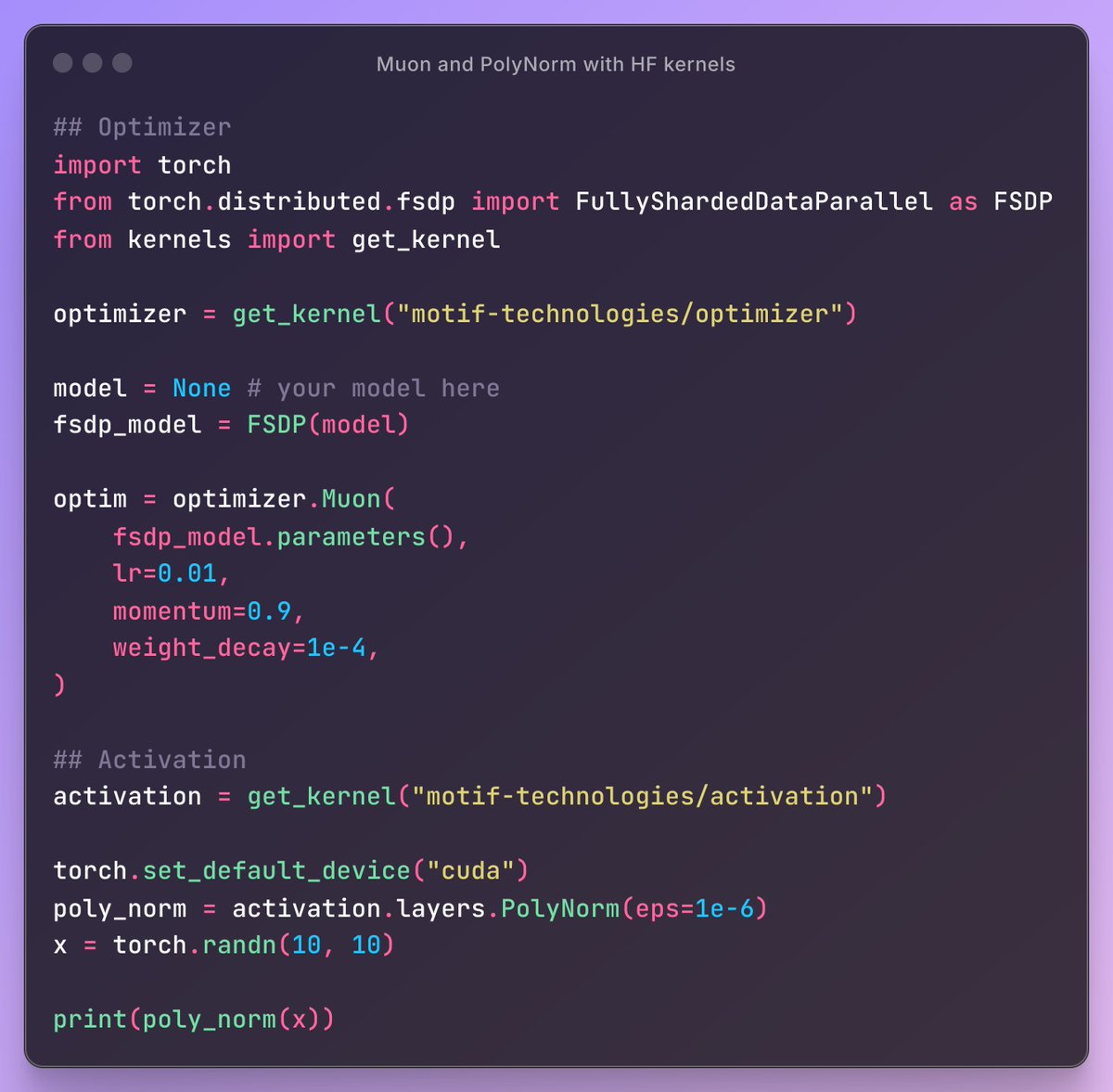
elie@eliebakouch
Motif 2.6B tech report is pretty insane, first time i see a model with differential attention and polynorm trained at scale! > It's trained on 2.5T of token, with a "data mixture schedule" to continuously adjust the mixture over training. > They use WSD with a "Simple moving average" averaging the last 6 ckpt every 8B token. > They trained on Finemath, Fineweb2, DCLM, TxT360. > Lot of details in the finetuning data they used, for instance they used EvolKit and did some "dataset fusion" to have more compressed knowledge into the data. > They mention they also tried Normalized GPT, QK-Norm and Cross Layer Attention.
English
Hongwu Peng retweetledi

Hongwu Peng retweetledi

Adobe announced the addition of new video generation capabilities to its Firefly AI model and Premiere Pro
The new Firefly Video Model is now in 'limited public beta' and allows users to generate video from text prompts or images
English
Hongwu Peng retweetledi

Very proud to introduce two of our recent long-context works:
HELMET (best long-context benchmark imo): shorturl.at/JnBHD
ProLong (a cont’d training & SFT recipe + a SoTA 512K 8B model): shorturl.at/XQV7a
Here is a story of how we arrived there

English

I did not even have 10 submissions…. There are two different “Bo Dai”.
Peter Richtarik@peter_richtarik
Source: papercopilot.com/paper-list/neu…
English
@melon_thief @yuntiandeng It's just for research purpose to understand LLM reasoning behavior😂
English

@yuntiandeng I don’t understand why it doesn’t just know use code to solve any math problem?
English

Is OpenAI's o1 a good calculator? We tested it on up to 20x20 multiplication—o1 solves up to 9x9 multiplication with decent accuracy, while gpt-4o struggles beyond 4x4. For context, this task is solvable by a small LM using implicit CoT with stepwise internalization. 1/4

English
Hongwu Peng retweetledi

5 papers you want to read to understand better how @OpenAI o1 might work. Focusing on Improving LLM reasoning capabilities for complex tasks via training/RLHF, not prompting. 👀
> Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking (huggingface.co/papers/2403.09…) from Stanford
> Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents (huggingface.co/papers/2408.07…) from MultiOn/Stanford
> Let's Verify Step by Step (huggingface.co/papers/2305.20…) from OpenAI
> V-STaR: Training Verifiers for Self-Taught Reasoners (huggingface.co/papers/2402.06…**) from Microsoft, Mila**
> Learn Beyond The Answer: Training Language Models with Reflection for Mathematical Reasoning (huggingface.co/papers/2406.12…) from Notre Dam, Tencent
I'm not claiming this is how O1 works, but it helps us better understand it. I'll share summary posts in the coming days. Make sure to follow! 🫡

English
@OlamicShelter @tianle_cai Even garbage token may help improve reasoning
English

@tianle_cai Same idea, obviously not any helpful for the result. But these expressions are not hard to clean up. I think maybe they are intentionally adding that to let consumers feel that LLM is thinking.
English

o1's chain of thought contains a lot of verbal expressions like 'Hmm', 'But how?', etc. Are they using lecture recordings to train this model...
English
Hongwu Peng retweetledi
Mindblowing! 🤯 A 70B open @AIatMeta Llama 3 better than @AnthropicAI Claude 3.5 Sonnet and @OpenAI GPT-4o using Reflection-Tuning! In Reflection Tuning, the LLM is trained on synthetic, structured data to learn reasoning and self-correction. 👀
In the assistant response, the LLM:
1️⃣ Begins by outputting its reasoning within tags.
2️⃣ If the model detects an error in its reasoning, it uses tags within the section to signal this and attempt to correct itself.
3️⃣ Once satisfied with its reasoning, it provides the final answer within

English
Hongwu Peng retweetledi

I'm excited to announce Reflection 70B, the world’s top open-source model.
Trained using Reflection-Tuning, a technique developed to enable LLMs to fix their own mistakes.
405B coming next week - we expect it to be the best model in the world.
Built w/ @GlaiveAI.
Read on ⬇️:

English
English

New paper📢 LLM folks have been supervised finetuning their models with data from large and expensive models (e.g., Gemini Pro).
However, we achieve better perf. by finetuning on the samples from the smaller and weaker LLMs (e.g., Flash)!
w/@kazemi_sm @arianTBD @agarwl_ @vqctran

English
Hongwu Peng retweetledi

Introducing *Transfusion* - a unified approach for training models that can generate both text and images. arxiv.org/pdf/2408.11039
Transfusion combines language modeling (next token prediction) with diffusion to train a single transformer over mixed-modality sequences. This allows us to leverage the strengths of both approaches in one model. 1/5


English
Hongwu Peng retweetledi

So freaking proud of the AGI safety&alignment team -- read here a retrospective of the work over the past 1.5 years across frontier safety, oversight, interpretability, and more. Onwards! alignmentforum.org/posts/79BPxvSs…
English
Hongwu Peng retweetledi

I shared the following note with my OpenAI colleagues today:
I've made the difficult decision to leave OpenAI. This choice stems from my desire to deepen my focus on AI alignment, and to start a new chapter of my career where I can return to hands-on technical work. I've decided to pursue this goal at Anthropic, where I believe I can gain new perspectives and do research alongside people deeply engaged with the topics I'm most interested in. To be clear, I'm not leaving due to lack of support for alignment research at OpenAI. On the contrary, company leaders have been very committed to investing in this area. My decision is a personal one, based on how I want to focus my efforts in the next phase of my career.
I joined OpenAI almost 9 years ago as part of the founding team after grad school. It's the first and only company where I've ever worked, other than an internship. It's also been quite a lot of fun. I'm grateful to Sam and Greg for recruiting me back at the beginning, and Mira and Bob for putting a lot of faith in me, bringing great opportunities and helping me successfully navigate various challenges. I'm proud of what we've all achieved together at OpenAI; building an unusual and unprecedented company with a public benefit mission.
I am confident that OpenAI and the teams I was part of will continue to thrive without me. Post-training is in good hands and has a deep bench of amazing talent. I get too much credit for ChatGPT -- Barret has done an incredible job building the team into the incredibly competent operation it is now, with Liam, Luke, and others. I've been heartened to see the alignment team coming together with some promising projects. With leadership from Mia, Boaz and others, I believe the team is in very capable hands.
I'm incredibly grateful for the opportunity to participate in such an important part of history and I'm proud of what we've achieved together. I'll still be rooting for you all, even while working elsewhere.
English
Hongwu Peng retweetledi
Glad to see Medusa keep advancing cutting-edge models and go beyond language 😍
Rohan Paul@rohanpaul_ai
New ultra-fast ‘multi-head’ speech recognition model drop from @_aiOla, beats OpenAI Whisper. Officially dubbed Whisper-Medusa, the model builds on Whisper but uses a novel “multi-head attention” architecture that predicts far more tokens at a time So they seem to have added more attention heads on top of whisper. They claim the same accuracy but 50% faster. Their demo does one text in 1.9s while "baseline" whisper does it in 4s. Code and weights opensource under MIT. they have started with a 10-head model but will soon expand to a larger 20-head version capable of predicting 20 tokens at a time, leading to faster recognition and transcription without any loss of accuracy.
English