Hugo Touvron retweetledi

Introducing Meta Llama 3: the most capable openly available LLM to date.
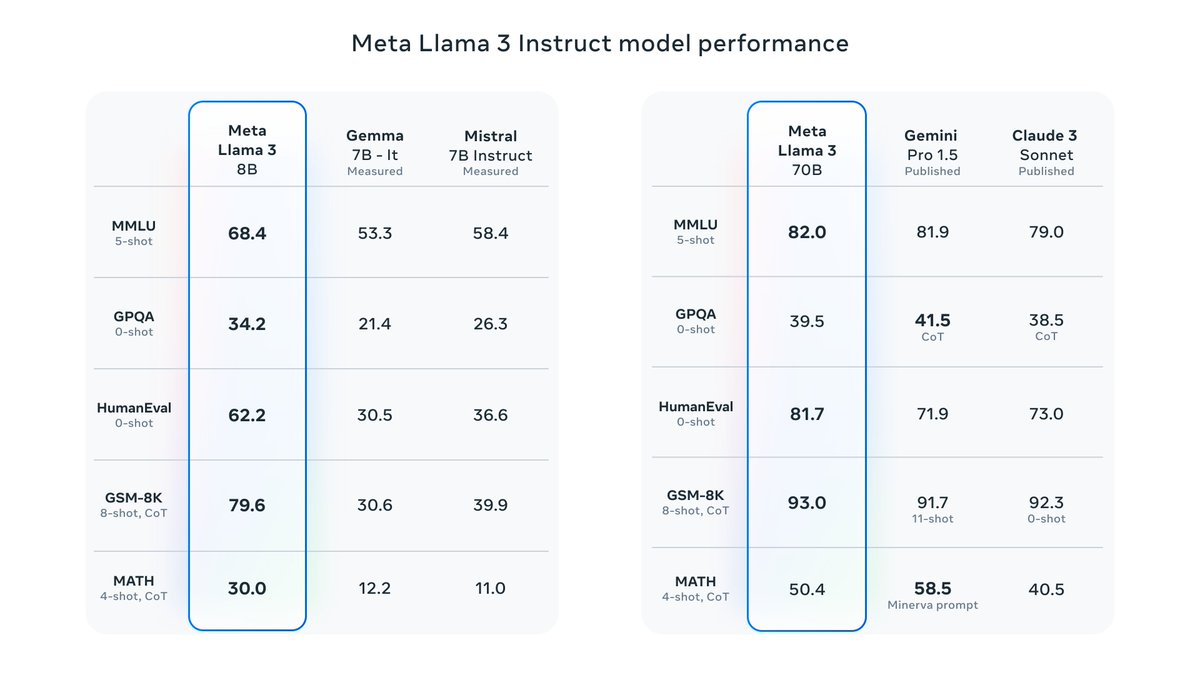
Today we’re releasing 8B & 70B models that deliver on new capabilities such as improved reasoning and set a new state-of-the-art for models of their sizes.
Today's release includes the first two Llama 3 models — in the coming months we expect to introduce new capabilities, longer context windows, additional model sizes and enhanced performance + the Llama 3 research paper for the community to learn from our work.
More details ➡️ go.fb.me/i2y41n
Download Llama 3 ➡️ go.fb.me/ct2xko
English