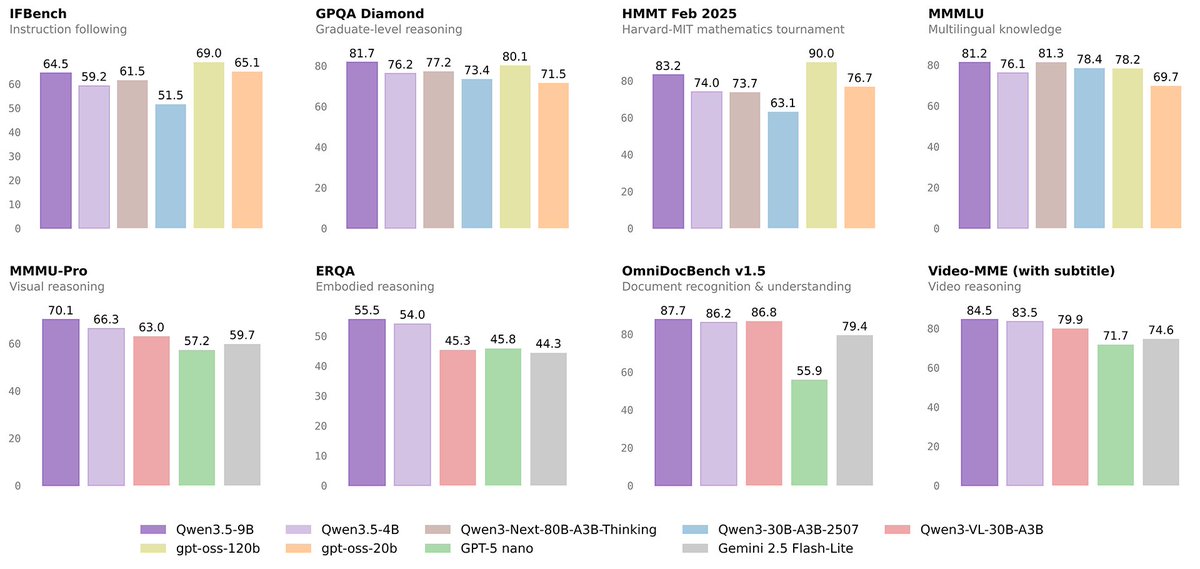
Sabitlenmiş Tweet

Virtūs et Honos
1.5K posts

@IntrepidTF07
Do not go quietly into that good night... Rage, rage against the dying of the light.



We're aware people are hitting usage limits in Claude Code way faster than expected. Actively investigating, will share more when we have an update!



@bcherny @UltraLinx please at least fix the uncontrollable scrolling/flickering before the next 3000 features