OMG this was way to fun (and easy) to make. I love her! (don't worry Rosie you are still #1)


English
István Lőrincz
378 posts


@IstvanSpace
Making knowledge find you, not hide from you | Founder at Internode AI @internode_ai

What if your team gave standup updates, and GPT-Realtime-2 moved the tickets?
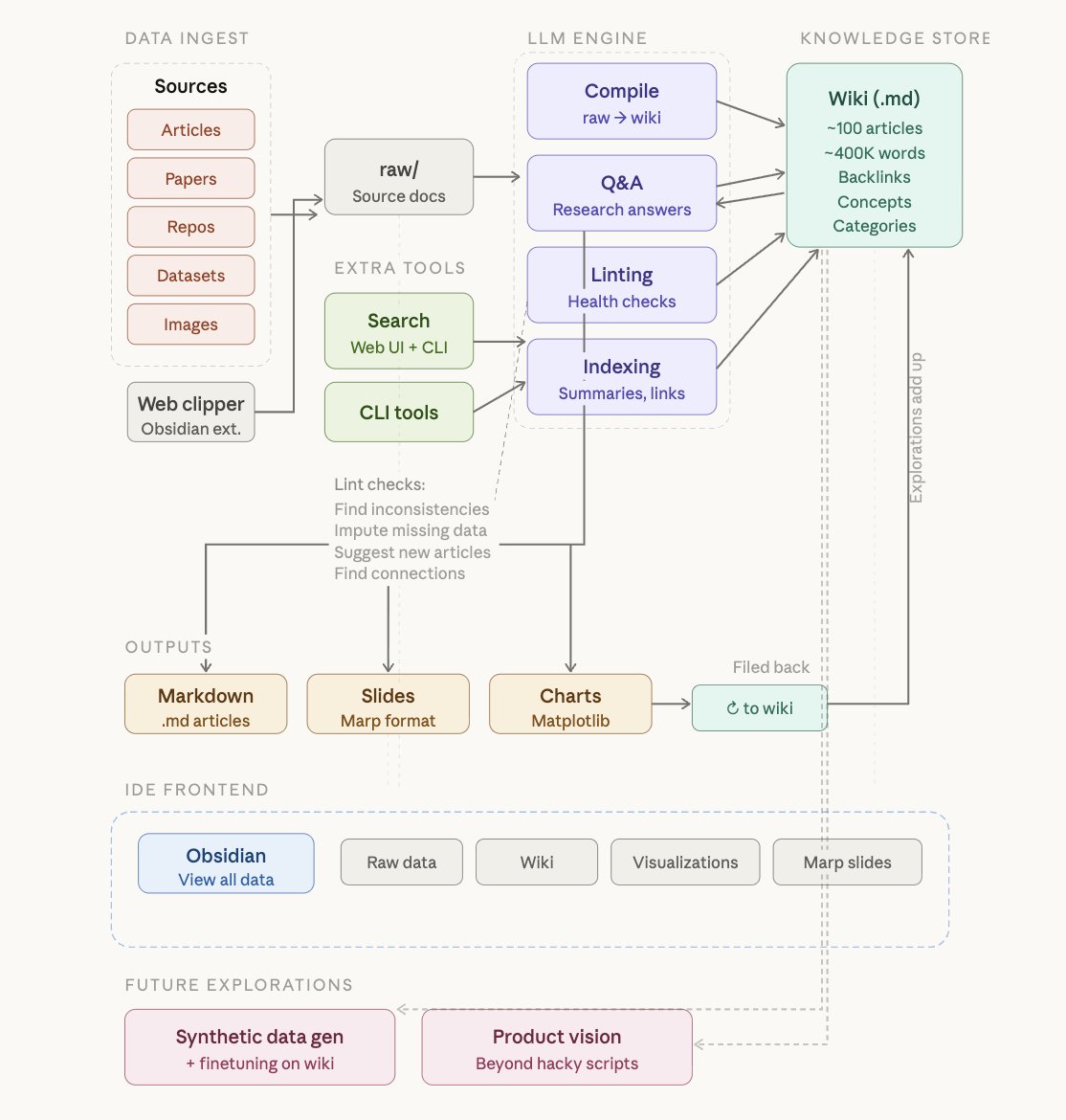
We wrote a blog post about how our own team uses Internode day to day, from turning meeting transcripts into tickets, to weekly change logs drafted in two minutes, to asking the company brain who owns what. Read it here: internode.ai/blog/how-we-us…



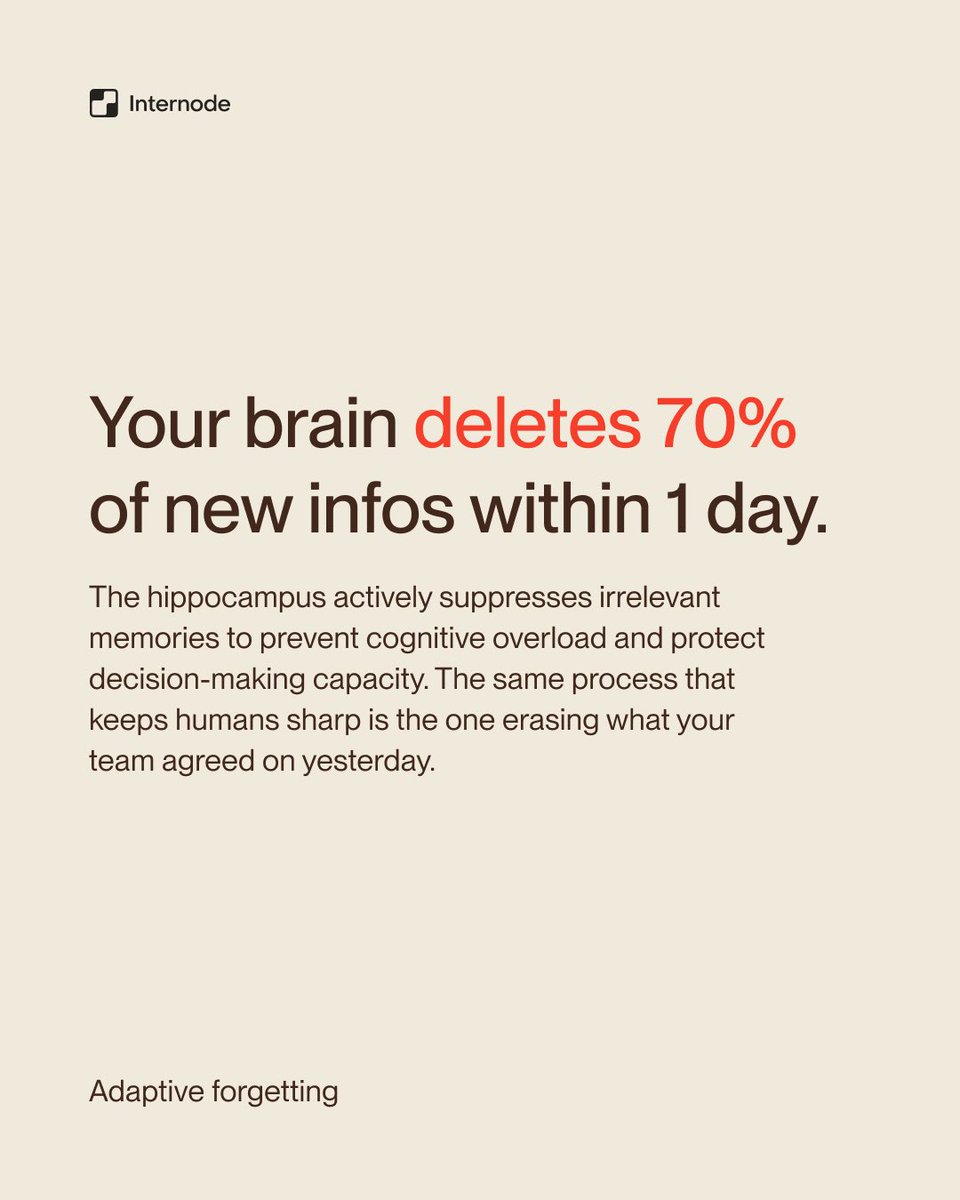


Happy Labor Day! 🎉 Humans forget 70% of new information within a day. The future of work separates memory from humans. That's what Internode is built for - and we just launched for free. 👉 internode.ai

Company Brain @t_blom Every company has critical know-how scattered across people's heads, old Slack threads, support tickets, and databases, and AI agents can't operate like that. We think every company in the world is going to need a new primitive: a living map of how the company works that turns its own artifacts into an executable skills file for AI.



Thanks Eric We almost met once. Roger Penrose tried to introduce us but you looked away dismissively. You haven’t changed. You didn’t respond to my criticisms of your positions which I conclude to mean you have no viable responses. Without consciousness you have a theory of nothing. Meanwhile the 30 year old Penrose-Hameroff Orch OR theory of consciousness has more explanatory power, biological connection and experimental validation than all other theories combined. academic.oup.com/nc/article/202…
Agents getting the right context to do their work will be the dominant IT challenge over the next decade. Every agent strategy is at the mercy of how effectively agents can access the right data and systems to make decisions. Huge opportunity for those that get this right.

.@Levie shared with @CNBC why the rapid rise of AI agents is good news for enterprises that have the right foundation in place. "If you want to be able to include them in your workflow, have them augment your work, they need access to your critical enterprise data. And they need to access it in a secure way, in a way that's governed."

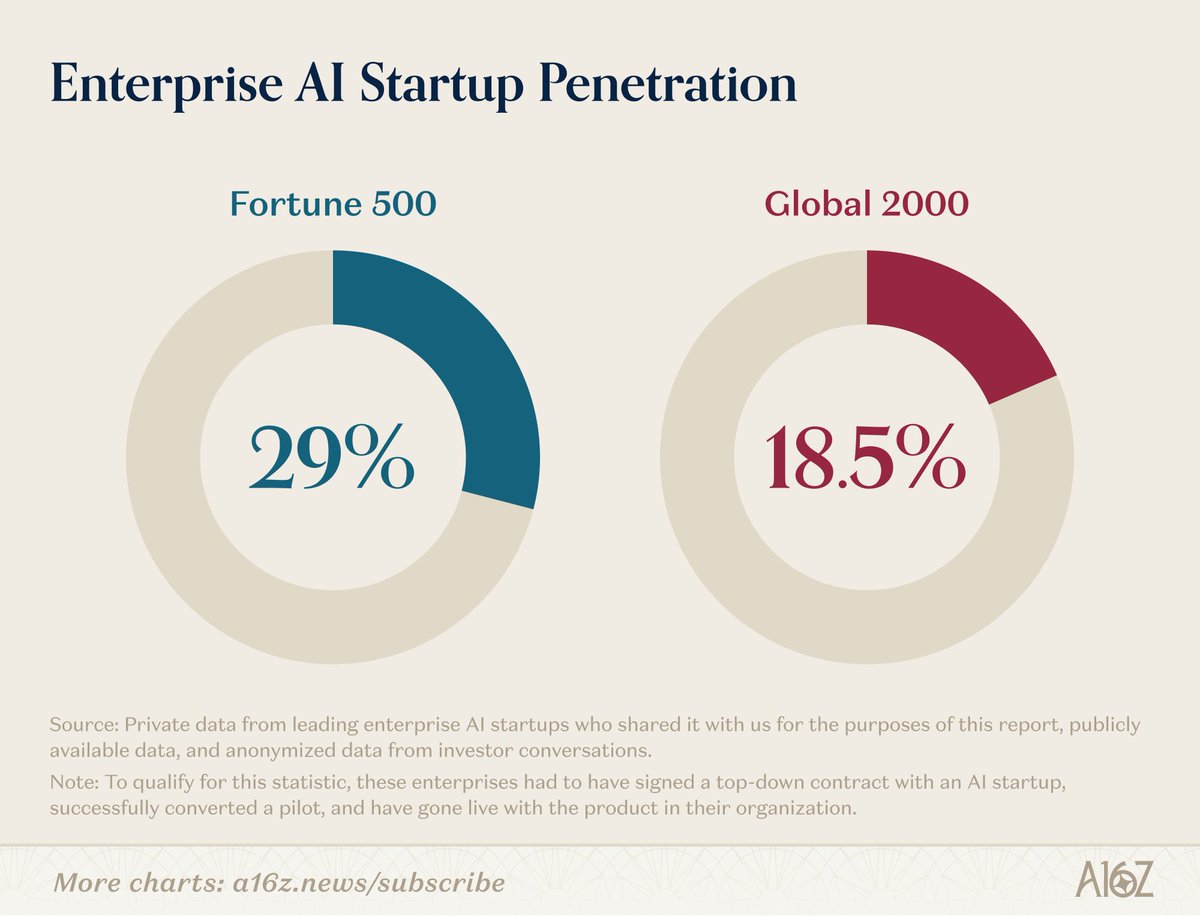
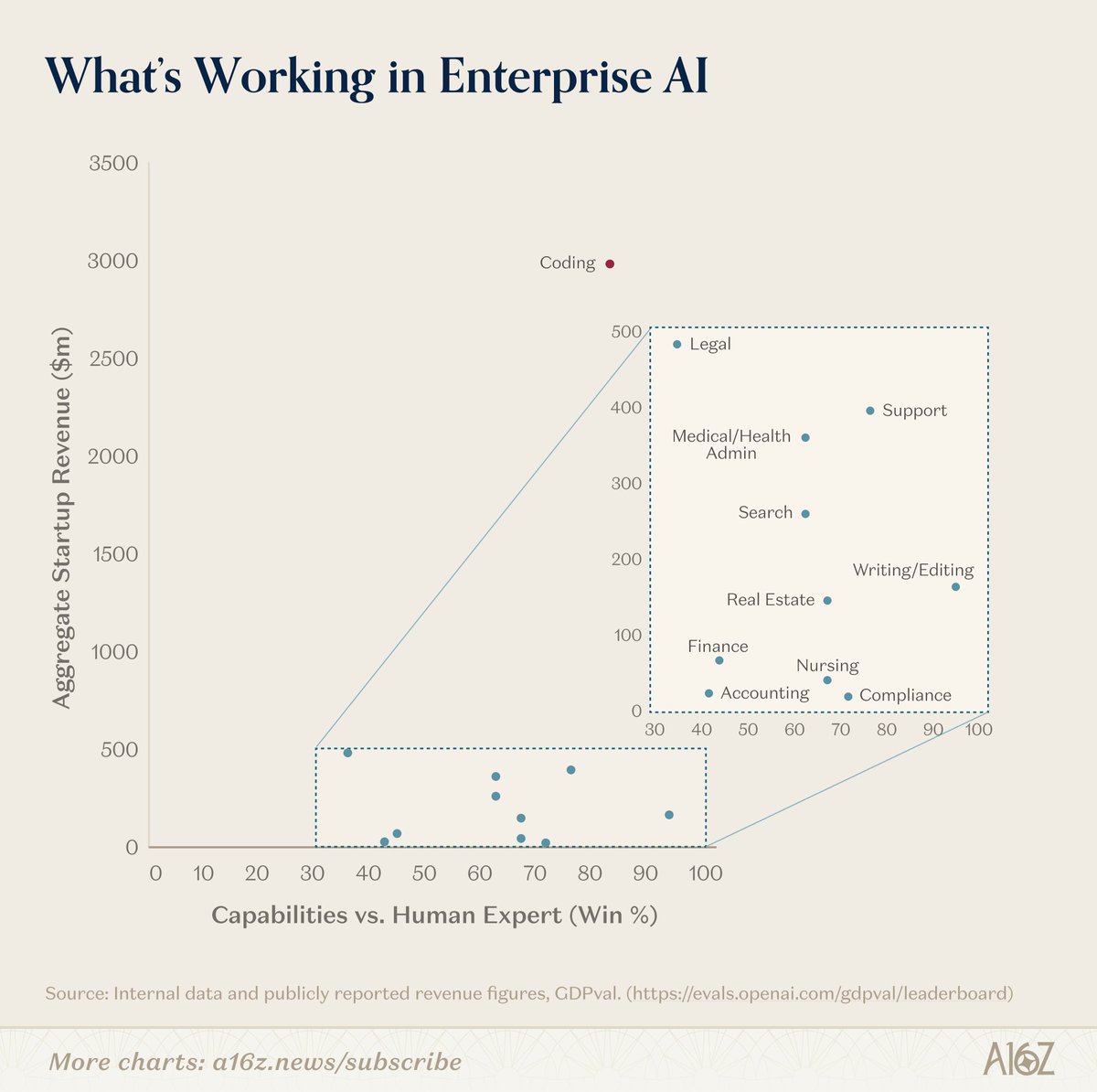

Magical OpenClaw experiences that use frontier models cost $300-1,000/day today, heading to $10,000/day and more. The future shape of the entire technology industry will be how to drive that to $20/month.
It’s very unclear to me what the upper bound on daily token use per person is going to. Orders of magnitude beyond this for sure.