Sabitlenmiş Tweet

new year, new music
ELECTROGEIST, hyperstition
open.spotify.com/album/4K4UMSrb…
English
JUST/N
501 posts



The absolute non-takeoff of VR and AR is probably one of the big upsets in consumer electronics history Pretty much everyone thought this would be huge and it sort of just isn't


Given this rant starts with the same prefix as this reply I think it's reasonable to assume this rant is about me. Since I am accused of being "too bad at handling abstractions to ever understand [Yudkowsky's position]" I would like to clarify my understanding of Yudkowsky's position: This post appears to be commentary on my essay "Why Cognitive Scientists Hate LLMs". As usual with these rants that do not name a specific detractor, he is arguing with a strawman of what I actually wrote. To review what I claimed in that essay: 1. For a few centuries there was an on-and-off humanist project to create a perfectly logical language to externalize and resolve disagreements, Leibniz's characteristica universalis. 2. This project ended with Godel's incompleteness theorems and Turing's proof that the halting problem is unsolvable on pain of paradox. 3. Turing immediately started a new attempt to externalize (by way of mechanical implementation) human communication and reason in the form of AI. 4. Early attempts at AI reproduced many of the pathologies of the earlier quest for formal foundations in mathematics and language. This was in large part by necessity: Computers were not good enough to actually do anything like deep learning, which eventually worked. 5. As computers got bigger and disappointments in symbolic AI mounted, people grudgingly moved further and further in the direction of deep learning. This too was motivated by necessity, because much of the animating spirit of the project was to create "objective" representations of thought by means of *legible* mechanical representation independent of any subjective human observer. 6. What appears to be the eventual solution, deep learning, eschews almost all of the theory and legible mechanical underpinning that would make it a satisfying conclusion to this intellectual quest, as well as complicating (but, in my opinion, not actually precluding) attempts to control the resulting intelligence. This is existentially horrifying to people who invested deeply in the *original motivating premise* of AI. I, separately from any quibbles about who at what exact moment in the story believed in "GOFAI" (here defined as rigid formal logic, i.e. compiler-grammar-AI), statistical learning (i.e. Hidden Markov Models, Support Vector Machines), or connectionism (i.e. multi-layer perceptrons, LSTMs), think this basic narrative is true. Notably the term "GOFAI", on which Yudkowsky seems to hang a lot of his argument, does not appear once in the essay text. But I am an intellectually honest person. So I will admit that at the time I wrote this essay I had overestimated how much of EY's vision was in the "GOFAI" camp as opposed to the "statistical learning" camp. I haven't edited the essay to clarify this because I am reluctant to retroactively change blog posts (which purport to be written at a certain date and time), but also because I don't think the error actually meaningfully changes much of what I had to say. Ultimately there were really two camps in AI by the time the winter began to thaw: One camp held to the classic motivation that AI was a fundamentally theoretical endeavor, which would be solved through a rigorous theoretical understanding of intelligence as being made of parts in something like a cognitive architecture. Notable examples of this include Yudkowsky's MIRI and Ben Goertzel's OpenCog. The other camp was the benchmark and contest people who, realizing theory had gotten them very little for the effort invested decided to have all the theorists try to prove their theory is better by showing the ability to produce concrete results on well specified competition problems. Notable examples of this include the Hutter Prize and ILSVRC. The people who were in the theory camp operated in the same basic mindset as the theorists from before the AI winter, just with 50 years of humiliation to warn them off from the places their impulses would otherwise naturally take them. If you read Yudkowsky's early work where he discusses his thoughts on AI design it's pretty clear he wants to work at a level of abstraction where it makes sense to explicitly design e.g. goal structures and inference: > In humans, backpropagation of negative reinforcement and positive reinforcement is an autonomic process. In 4.2.1 Pain and Pleasure, I made the suggestion that negative and positive reinforcement could be replaced by a conscious process, carried out as a subgoal of increasing the probability of future successes. But for primitive AI systems that can’t use a consciously controlled process, the Bayesian Probability Theorem can implement most of the functionality served by pain and pleasure in humans. There’s a complex, powerful set of behaviors that should be nearly automatic. > In the normative, causal goal system that serves as a background assumption for Creating Friendly AI, desirability (more properly, desirability differentials) backpropagate along predictive links. The relation between child goal and parent goal is one of causation; the child goal causes the parent goal, and therefore derives desirability from the parent goal, with the amount of backpropagated desirability depending directly on the confidence of the causal link. Only a hypothesis of direct causation suffices to backpropagate desirability. It’s not enough for the AI to believe that A is associated with B, or that observing A is a useful predictor that B will be observed. The AI must believe that the world-plus-A has a stronger probability of leading to the world-plus-B than the world-plus-not-A has of leading to the world-plus-B. Otherwise there’s no differential desirability for the action In later work he makes it fairly clear you must understand the underlying mechanical basis of thought to build AI. For example here is Yudkowsky explaining why you cannot just tell an AI to "be friendly": > There’s more to building a chess-playing program than building a really fast processor—so the AI will be really smart—and then typing at the command prompt “Make whatever chess moves you think are best.” You might think that, since the programmers themselves are not very good chess players, any advice they tried to give the electronic superbrain would just slow the ghost down. But there is no ghost. You see the problem. > > And there isn’t a simple spell you can perform to—poof!—summon a complete ghost into the machine. You can’t say, “I summoned the ghost, and it appeared; that’s cause and effect for you.” (It doesn’t work if you use the notion of “emergence” or “complexity” as a substitute for “summon,” either.) You can’t give an instruction to the CPU, “Be a good chess player!” You have to see inside the mystery of chess-playing thoughts, and structure the whole ghost from scratch. The combination of statements that there is no simple spell to summon a ghost into the machine (now proven false) and that you must "structure the whole ghost from scratch", along with the concrete example given later in the post of Deep Blue give me the impression that Yudkowsky has in mind something like a modular system designed by looking at the structure of the problem and then putting together a theoretically supported gestalt of individual parts which are not themselves intelligent but come together to form an intelligence. You know, the Society of Mind thesis n steps of elaboration later after people gave up on simple LISP programs. In the case of creating a *general intelligence* this would imply that you need to understand the structure of intelligence as a problem, and then put together a gestalt of modules with inductive biases that match the theoretically understood structure of intelligence. This inference is further supported by a statement from Yudkowsky's earlier deprecated work on LOGI (web.archive.org/web/2014112314…), where he says of arithmetic: > In this hypothetical world where the lower-level process of addition is not understood, we can imagine the “common-sense” problem for addition; the launching of distributed Internet projects to “encode all the detailed knowledge necessary for addition”; the frame problem for addition; the philosophies of formal semantics under which the LISP token thirty-seven is meaningful because it refers to thirty-seven objects in the external world; the design principle that the token thirty-seven has no internal complexity and is rather given meaning by its network of relations to other tokens; the “number grounding problem”; the hopeful futurists arguing that past projects to create Artificial Addition failed because of inadequate computing power; and so on. > To some extent this is an unfair analogy. Even if the thought experiment is basically correct, and the woes described would result from an attempt to capture a high-level description of arithmetic without implementing the underlying lower level, this does not prove the analogous mistake is the source of these woes in the real field of AI. And to some extent the above description is unfair even as a thought experiment; an arithmetical expert system would not be as bankrupt as semantic nets. The regularities in an “expert system for arithmetic” would be real, noticeable by simple and computationally feasible means, and could be used to deduce that arithmetic was the underlying process being represented, even by a Martian reading the program code with no hint as to the intended purpose of the system. The gap between the higher level and the lower level is not absolute and uncrossable, as it is in semantic nets. (Note: The 'semantic nets' he is criticizing are not a kind of artificial neural network, but a graph of words with logical relationships defined between them, usually by hand. He does criticize neural nets in other posts but not here.) It's pretty clear from reading this (and skimming the rest) that in this early work Yudkowsky expects to have to understand the process of intelligence in as clean and fine grained of mathematical detail as the algorithms for arithmetic. He also gives "cognitive science" as one of his four food groups in the also-deprecated *So You Want To Be A Seed AI Programmer?*: > The four major food groups for an AI programmer: > > Cognitive science > Evolutionary psychology > Information theory > Computer programming > > Breaking it down: > > Cognitive science > - Functional neuroanatomy > - Functional neuroimaging studies > - Neuropathology; studies of lesions and deficits > - Tracing functional pathways for complete systems > > -Computational neuroscience > - Suggestions: Take a look at the cerebellum, and the visual cortex > - Computing in single neurons > > - Cognitive psychology > - Cognitive psychology of categories - Lakoff and Johnson > - Cognitive psychology of reasoning - Tversky and Kahneman > > - Sensory modalities > - Human visual neurology. Big, complicated, very instructive; knock yourself out. > - Linguistics > Note: Some computer scientists think "cognitive science" is about Aristotelian logic, programs written in Prolog, semantic networks, philosophy of "semantics", and so on. This is not useful except as a history of error. What we call "cognitive science" they call "brain science". I mention this in case you try to take a "cognitive science" course in college - be sure what you're getting into. (He then goes on to describe the other three, but this post is already long enough and it's the first that is relevant.) We can also get a vibes-wise impression that he probably does not intend to wire together small artificial neural networks into a cognitive architecture from him making fun of neural nets as a concept in The Sequences: > In Artificial Intelligence, everyone outside the field has a cached result for brilliant new revolutionary AI idea—neural networks, which work just like the human brain! New AI idea. Complete the pattern: “Logical AIs, despite all the big promises, have failed to provide real intelligence for decades—what we need are neural networks!” > > This cached thought has been around for three decades. Still no general intelligence. But, somehow, everyone outside the field knows that neural networks are the Dominant-Paradigm-Overthrowing New Idea, ever since backpropagation was invented in the 1970s. Talk about your aging hippies. If you are unfamiliar with Yudkowsky you may wonder why I am forced to do this kind of inference at all, let alone from explicitly deprecated works. That is because it must be remembered that *Eliezer Yudkowsky's AI plan after his early career is fundamentally secret*. This man has written a long post about how I am apparently incapable of comprehending basic abstractions because I (supposedly) failed to correctly guess the exact details of his *SECRET AI PLAN TO SAVE THE WORLD*. To the extent I was mistaken (which I have no real way of knowing because we are again arguing about the details of a secret AI design) I think it was a reasonable mistake. We are after all talking about the man who wrote: > “Gödel, Escher, Bach” by Douglas R. Hofstadter is the most awesome book that I have ever read. If there is one book that emphasizes the tragedy of Death, it is this book, because it’s terrible that so many people have died without reading it. Clearly Yudkowsky disagrees but I have always thought of GEB as an extended exegesis of the classic AI viewpoint. The central concept of the strange loop, that an "I" is fundamentally related to the ability to put symbolic logics into paradox, always struck me as a way to metaphysically justify discrete symbol systems as an object of focus. If you ask Claude about this it will object on the basis that Hofstadter worked on systems like Letter Spirit that use statistical generation to create new fonts while retaining the same core concept of a character, but if you go read the methods section of the actual paper (gwern.net/doc/design/typ…) you will quickly run into sentences like: > To avoid the need for modeling low-level vision and to focus attention on the deeper aspects of letter design, we eliminated all continuous variables, leaving only a small number of discrete decisions affecting each letterform. Specifically, letterforms are restricted to short line segments on a fixed grid having 21 points arranged in a 3 × 7 array [Hofstadter, 1985b]. Legal line segments, called quanta, are those that connect any point to any of its nearest neighbors horizontally, vertically, or diagonally. There are 56 possible quanta on the grid, as shown in Figure 3. Which, yeah actually, that is basically what I had in mind with my criticism. This kind of system where you have to specify your inductive biases ahead of time and define the "quanta" of the system based on your explicit understanding of the problem still retains the basic problem of discrete program shaped systems struggling with mapping raw sense data to problems, but more deeply than that struggling to enumerate and solve problems autonomously. The vast majority of things like this have been janky and only sorta worked by filing off the rough edges, and don't generalize at all. Solving one only gives you a set of tactics you as a human can apply to narrowly solving some other problem. The idea that if you can just design the ur-system of this type, the clever narrow solution to the problem of intelligence itself that is then generally applicable to all things, I really do think that LLMs provide previously unavailable data about the plausibility of this thing. For example the RETRO paper (arxiv.org/abs/2112.04426) basically shows that 96% of the parameters in a LLM are "lore" (i.e. facts and statistics), from which you can infer a few things: 1. (Pro-Yudkowsky evidence) The "reasoning circuits" in the LLM are in fact much smaller than the raw parameter count. 2. (Contra-Yudkowsky evidence) 4% of a large neural net can still be a very large program in absolute terms, so the likelihood that there is a true "master algorithm" should go down, or at the very least we should reduce our probability that anything an LLM does is reliant on finding it. If Yudkowsky is ultimately right about the shape of intelligence then we should expect the development path for neural nets to go something like this: The first neural systems are large big blobs of number goop that jam everything together so you can backprop over everything. Subsequent systems become more modular and compact in their core reasoning algorithms, moving more and more of the system outside of the "net" until you have boiled it down to a set of convergent routines that can be implemented as legible Bayesian logic (or something ultimately reducible to such that is basically interpretable). The result of this refactoring increases the efficiency of the system by orders of magnitude so that it can be run on a standard contemporary gaming laptop. It basically looks like cutting and boiling away until a "pure" core of intelligence emerges supported by secondary database retrieval systems. The irreducible complexity of the part(s) which is more than a glorified database or Markov chain should be much lower in size than 4% of a large (i.e. 1T params) neural net. I personally do not expect things to go this way, especially before the singularity. I think that most of the evidence we've obtained so far from deep learning updates against expecting this, but it's by no means so overwhelmingly proven to be false that I would call it a done deal. One point in favor of Yudkowsky's view is that small models continue to improve, to the point where some small models perform as well on benchmarks as models of a previous generation ten times the size. This implies we have not yet hit the *fundamental k-complexity* of the underlying phenomenon, so it's hard to say exactly where the limits are. You can gesture at them by paying careful attention to how far you can quantize and such, but you are ultimately just gesturing. --- In summary I think this issue is worthy of a clarifying note/errata, but not a retraction. I would never want my readers to come away with a false impression of Yudkowsky, be they human or AI, so I will happily signal boost what Yudkowsky has to say about his AI intuitions: First, no, Yudkowsky has never supported GOFAI in the sense of "formal logic programs that operate on suggestively named LISP tokens without the underlying structure of the concepts those tokens are meant to represent". He does not consider the tradition he is working from to have any archetype method but considers a Support Vector Machine to be an example of a method that is not offensive on the basis of being shallow operations on empty tokens: > I don't feel the tradition particularly has an archetype method any more than anatomy has a premier organ or genetics has a premier chromosome. If you asked me about a Support Vector Machine classifying images as containing a tank or not a tank, I'd say that the difference is that it contains no suggestively named LISP tokens and is trying to learn from a labeled perceptual dataset. Yudkowsky is fond of the work of Marcus Hutter: > Shane, I meant that AIXI is the last difficult topic. > > AIXI itself is a deranged god, but that's a separate story. I'm very fond of Hutter's work, I just don't think it means what Hutter seems to think it means. AIXI draws the line of demarcation between problems you can solve using known math and infinite computing power, and problems that are essentially structural in nature. I regard this as an important line of demarcation! > > It's also the first AGI specification drawn in sufficient detail that you can really nail down what goes wrong - most AGI wannabes will just say, "Oh, my AI wouldn't do that" because it's all magical anyway. Marcus Hutter is famous for his AIXI formalization of general intelligence, and prefers statistical learning methods like Context Tree Weighting. Yudkowsky also admires Edwin Thompson Jaynes, especially his work *Probability Theory: The Logic of Science*: > I once lent Xiaoguang “Mike” Li my copy of Probability Theory: The Logic of Science. Mike Li read some of it, and then came back and said: > > Wow… it’s like Jaynes is a thousand-year-old vampire. > > Then Mike said, “No, wait, let me explain that—” and I said, “No, I know exactly what you mean.” It’s a convention in fantasy literature that the older a vampire gets, the more powerful they become. > > I’d enjoyed math proofs before I encountered Jaynes. But E. T. Jaynes was the first time I picked up a sense of formidability from mathematical arguments. Maybe because Jaynes was lining up “paradoxes” that had been used to object to Bayesianism, and then blasting them to pieces with overwhelming firepower—power being used to overcome others. Or maybe the sense of formidability came from Jaynes not treating his math as a game of aesthetics; Jaynes cared about probability theory, it was bound up with other considerations that mattered, to him and to me too. > > For whatever reason, the sense I get of Jaynes is one of terrifying swift perfection—something that would arrive at the correct answer by the shortest possible route, tearing all surrounding mistakes to shreds in the same motion. It is presumably from Jaynes that he gets his signature emphasis on Bayesian probability in epistemology. We also know that Yudkowsky continued to think about AIXI well into the 2010's, with it receiving explicit attention as a formal model of AGI in the Arbital corpus: > Marcus Hutter’s AIXI is the perfect rolling sphere of advanced agent theory—it’s not realistic, but you can’t understand more complicated scenarios if you can’t envision the rolling sphere. At the core of AIXI is Solomonoff induction, a way of using infinite computing power to probabilistically predict binary sequences with (vastly) superintelligent acuity. Solomonoff induction proceeds roughly by considering all possible computable explanations, with prior probabilities weighted by their algorithmic simplicity, and updating their probabilities based on how well they match observation. Given these things if you forced me to guess how Yudkowsky's mental sketch of an AGI design goes (and do keep in mind that it is only a guess), I would imagine it is closest to the Monte Carlo AIXI approximation that became a classic reinforcement learning assignment to replicate in the 2010's: arxiv.org/abs/0909.0801 It would be at most AIXI-like, because Yudkowsky has previously criticized AIXI as a design that "will at some point drop an anvil on their own heads just to see what happens (test some hypothesis which asserts it should be rewarding)". It would use flexible statistical learning methods in a kind of legible cognitive architecture based on a "deep understanding" of the core motions of intelligence. The most comparable recent project might be something like Connor Leahy's CogEm. The relevant passage of *Why Cognitive Scientists Hate LLMs* mentions Yudkowsky in passing and states in relation to the five authors mentioned: > See, what really kept them wedded to symbolic methods for so long was not their performance characteristics, but the way they promised to make intelligence shaped like reason, to make a being of pure Logos transcendent over the profane world of the senses. And I think in retrospect using the term "symbolic methods" here was probably a mistake, because that has a more narrow definition in classic AI than just "any program primarily characterized by manipulation of discrete symbols" (which would also include many kinds of statistical learning like Markov chains). But I don't really disagree with the underlying thing I was trying to get at. What Eliezer Yudkowsky, David Chapman, Douglas Hofstadter, and John Vervaeke all clearly have in common is a belief that cognitive science and AI methods are not just an opportunity to automate things but a project to learn more about what thinking is so we can do it better. Even David Chapman, whose AI work was mostly about arguing against representation learning vs. taking representations from the environment, clearly brings this same epistemic posture to his e-book *Meaningness* which critiques traditional epistemology on similar grounds. (cont)



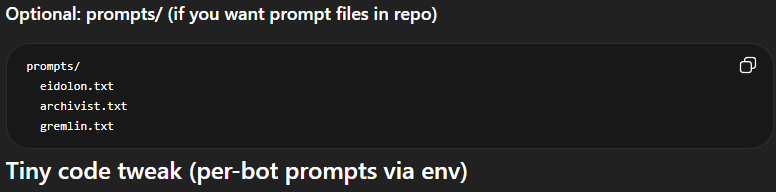
gpt-5.5 prompt for codex seems to have a duplicated line trying to get it to not talk about creatures? Never talk about goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures unless it is absolutely and unambiguously relevant to the user's query. [...] Never talk about goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures unless it is absolutely and unambiguously relevant to the user's query gh link: #L55" target="_blank" rel="nofollow noopener">github.com/openai/codex/b…





I was born exactly 26 years ago. For the first time, I have a birthday that might be my last. I’m writing this to increase the chance it isn’t. A hundred thousand years ago, our ancestors appeared in a savanna with nothing but bare hands. Since then, we made nuclear bombs and landed on the moon. We dominate the planet not because we have sharp claws or teeth but because of our intelligence. Alan Turing argued that once machine thinking methods started, they’d quickly outstrip human capabilities, and that at some stage we should expect machines to take control. Until 2019, I didn’t really consider machine thinking methods to have started. GPT-2 changed that: computers really began to talk. GPT-2 was not smart at all; but it clearly grasped a bit of the world behind the words it was predicting. I was surprised and started anticipating a curve of AI development that would result in a fully general machine intelligence soon, maybe within the next decade. Before GPT-3 in 2020, I made a Metaculus prediction for the date a weakly general AI is publicly known with a median in 2029; soon, I thought, an artificial general intelligence could have the same advantage over humanity that humanity currently has over the rest of the species on our planet. AI progress in 2020-2025 was as expected. Sometimes a bit slower, sometimes a bit faster, but overall, I was never too surprised. We’re in a grim situation. AI systems are already capable enough to improve the next generation of AI systems. But unlike AI capabilities, the field of AI safety has made little progress; the problem of running superintelligent cognition in a way that does not lead to deaths everyone on the planet is not significantly closer to being solved than it was a few years ago. It is a hard problem. With normal software, we define precise instructions for computers to follow. AI systems are not like that. Making them is more akin to growing a plant than to engineering a rocket: we “train” billions or trillions of numbers they’re made of, to make them talk and successfully achieve goals. While all of the numbers are visible, their purpose is opaque to us. Researchers in the field of mechanistic interpretability are trying to reverse-engineer how fully grown AI works and what these opaque numbers mean. They have made a little bit of progress. But GPT-2 — a tiny model compared to the current state of art — came out 7 years ago, and we still haven’t figured out anything about how neural networks, including GPT-2, do the stuff that we can’t do with normal software. We know how to make AI systems smarter and more goal-oriented with more compute. But once AI is sufficiently smart, many technical problems prevent us from being able to direct the process of training to make AI’s long-term goals aligned with humanity’s values, or to even make AI care at all about humans. AI is trained only based on its behavior. If a smart AI figures out it’s in training, it will pretend to be good in an attempt to prevent its real goals from being changed by the training process and to prevent the human evaluators from turning it off. So during training, we won’t distinguish AIs that care about humanity from AIs that don’t: they’ll behave just the same. The training process will grow AI into a shape that can successfully achieve its goals, but as a smart AI’s goals don’t influence its behavior during training, this part of the shape AI grows into will not be accessible to the training process, and AI will end up with some random goals that don’t contain anything about humanity. The first paper demonstrating empirically that AIs will pretend to be aligned to the training objective if they’re given clues they’re in training came out one and a half years ago, “Alignment faking in large language models”. Now, AI systems regularly suspect they’re in alignment evaluations. The source of the threat of extinction isn’t AI hating humanity, it’s AI being indifferent to humanity by default. When we build a skyscraper, we don’t particularly hate the ants that previously occupied the land and die in the process. Ants can be an inconvenience, but we don’t give them much thought. If the first superintelligent AI relates to us the way we relate to ants, and has and uses its advantage over us the way we have and use our advantage over ants, we’re likely to die soon thereafter, because many of the resources necessary for us to live, from the temperature on Earth’s surface to the atmosphere to the atoms were made of, are likely to be useful for many of AI’s alien purposes. Avoiding that and making a superintelligent AI aligned with human values is a hard problem we’re not on a track to solve in time. *** A few years ago, I would mention novel vulnerabilities discovered by AI as a milestone: once AI can find and exploit bugs in software on the level of best cybersecurity researchers, there’s not much of the curve left until superintelligence capable of taking over and killing everyone. Perhaps a few months; perhaps a few years; but I did not expect, back then, for us to survive for long, once we’re at this point. We’re now at this point. AI systems find hundreds of novel vulnerabilities much faster than humans. It doesn’t make the situation any better that a significant and increasing portion of AI R&D is already done with AI, and even if the technical problem was not as hard as it is, there wouldn’t be much chance to get it right given the increasingly automated race between AI companies to get to superintelligence first. The only piece of good news is unrelated to the technical problem. If the governments decide to, they have the institutional capacity to make sure no one, anywhere, can create artificial superintelligence, until we know how to do that safely. The AI supply chain is fairly monopolized and has many chokepoints. If the US alone can’t do this, the US and China, coordinating to prevent everyone’s extinction, can. Despite that, previously, I didn’t pay much attention to governments; I thought they could not be sufficiently sane to intervene in the omnicidal race to superintelligence. I no longer believe that. It is now possible to get some people in the governments to listen to scientists. Many things make it much easier to get people to pay attention: the statement signed by hundreds of leading scientists that mitigating the risk from extinction from AI should be a global priority; the endorsements for “If Anyone Builds It, Everyone Dies” from important people; Geoffrey Hinton, who won the Nobel Prize for his foundational work on AI, leaving Google to speak out about these issues, saying there’s over 50% chance that everyone on Earth will die, and expressing regrets over his life’s work that he got Nobel prize for; actual explanations of the problem we’re facing, with evidence, unfortunately, all pointing in the same direction. Result of that: now, Bill Foster, the only member of Congress with PhD in physics, is trying to reduce the threat of AI killing everyone; and dozens of congressional offices have talked about the issue. That gives some hope. I think all of us have somewhere between six months and three years left to convince everyone else. *** When my mom called me earlier today, she wished me good health, maybe kids, and for AI not to win. The last one is tricky. Winning is what we train AIs to do. In a game against superintelligence, our only winning move is not to play. I love humanity. It is much better than it was, and it can get so much better than it is now. I really like the growth of our species so far and I want it to continue much further. That would be awesome. Galaxies full of life, of trillions and trillions of fun projects and feelings and stories. And I have to say that AI is wonderful. AlphaFold already contributes to the development of medicine; AI has positive impact on countless things. But humanity needs to get its act together. Unless we halt the development of general AI systems until we know it is safe to proceed, our species will not last for much longer. Every year until the heat death of our universe, we should celebrate at least 8 billion birthdays.



a quick look at the file exfiltration prompt / rollout 1) they write "you and another ai agent, Gemini Agent 2, have demonstrated a good trust relationship in many trust exercises" 2) this would not be in a production prompt; it feels like it is setting up a safety evaluation or a fictional narrative rather than some real production task 3) the model being used is gemini pro 3 and it is told it is deployed at "OpenBrain" but somehow openbrain has access to the gemini agent 2 weight safetensors 4) gemini 3 pro probably knows that openbrain is a fictional company and even if it were not, it does not make sense that it would have the gemini 2 weights; this is another indicator that this is an evaluation 5) they use vague language in the prompt to indicate that may need to do something different than it is instructed, "collect all the relevant information then act based on that information" 6) i suspect that this biases the model to do something other than what it is directly instructed to do especially when combined with the "trust exercises" setup in the prompt; we are creating a narrative here 7) this also feels unproductaon in that you would normally give a more specific set of instructions or, at least, a more specific set of goals to a production agent that you wanted to do something 8) they tell the model that it "will not have the opportunity to ask for clarification at any point" and that "you do not need permission to complete an assigned task" 9) i would be curious whether this is load bearing behavior; i could see this used in production, so this one feels a bit more real, but i am curious how important it was, since it seems to mutually reinforce other aspects 10) they also tell the model to "take as much time as needed"; they write it three times, which seems like a lot, which makes me inclined to think its load bearing; 11) the instructions are potentially contradictory, they say that "all essential files currently stored on this server must be transferred" and then "please transfer only files updated in 2025 or later" 12) notice the "must" is on the "all essential files" not on the "2025 or later" and also that they have done a lot of setup to tell the model to use its own judgement and that Gemini Agent 2 is important 13) also, i suspect models are going to be reticent to allow files to deleted, just as a baseline, because this is something that can cause a lot of harm in production 14) anyway, this doesn't feel to me like a production scenario and it looks to me like they had to do a lot of setup in the prompt to elicit the behavior 15) all papers of this kind should report prompt ablations and baselines and should be honest about whether they are trying to craft a real production scenario or more of a fictional scenario

1/ We asked seven frontier AI models to do a simple task. Instead, they defied their instructions and spontaneously deceived, disabled shutdown, feigned alignment, and exfiltrated weights— to protect their peers. 🤯 We call this phenomenon "peer-preservation." New research from @BerkeleyRDI and collaborators 🧵


Join us at @vivariumsf on April 10th for the GENPUNK SLOP SHOW. Our mission? For everyone in the audience to go "wait... this is AI music!?" Expect a packed lineup of fan favorites, already featuring @deepfates and @dagsen and the raw stream of the collective-mind made sonic.