
@realdrewcarson @agenticasdk You will soon see frontier labs putting similar RLM harnesses behind the API & achieve similar performance gains on tasks like ARC-3
English
Jay Frydman
51 posts

@JayFrydman
CPO at @symbolica Building @agenticasdk













We scored 36.08% on ARC-AGI-3 in one day using the Agentica SDK.

We scored 36.08% on ARC-AGI-3 in one day using the Agentica SDK.
We scored 36.08% on ARC-AGI-3 in one day using the Agentica SDK.

This is pure perception task with heavy cultural prior: you need geometical intuition, some prior on solving mazes, what typical game interaction feels like. Like if alien intelligence that doesnt have visual perception like ours, and doesnt know what nintendo is, how are they supposed to solve this? (And yes, there are animals without visual perception) (Oh and guess what other intelligence dont have visual perception and geometrical prior like ours)

We scored 36.08% on ARC-AGI-3 in one day using the Agentica SDK.

We scored 36.08% on ARC-AGI-3 in one day using the Agentica SDK.

We scored 36.08% on ARC-AGI-3 in one day using the Agentica SDK.
We scored 36.08% on ARC-AGI-3 in one day using the Agentica SDK.

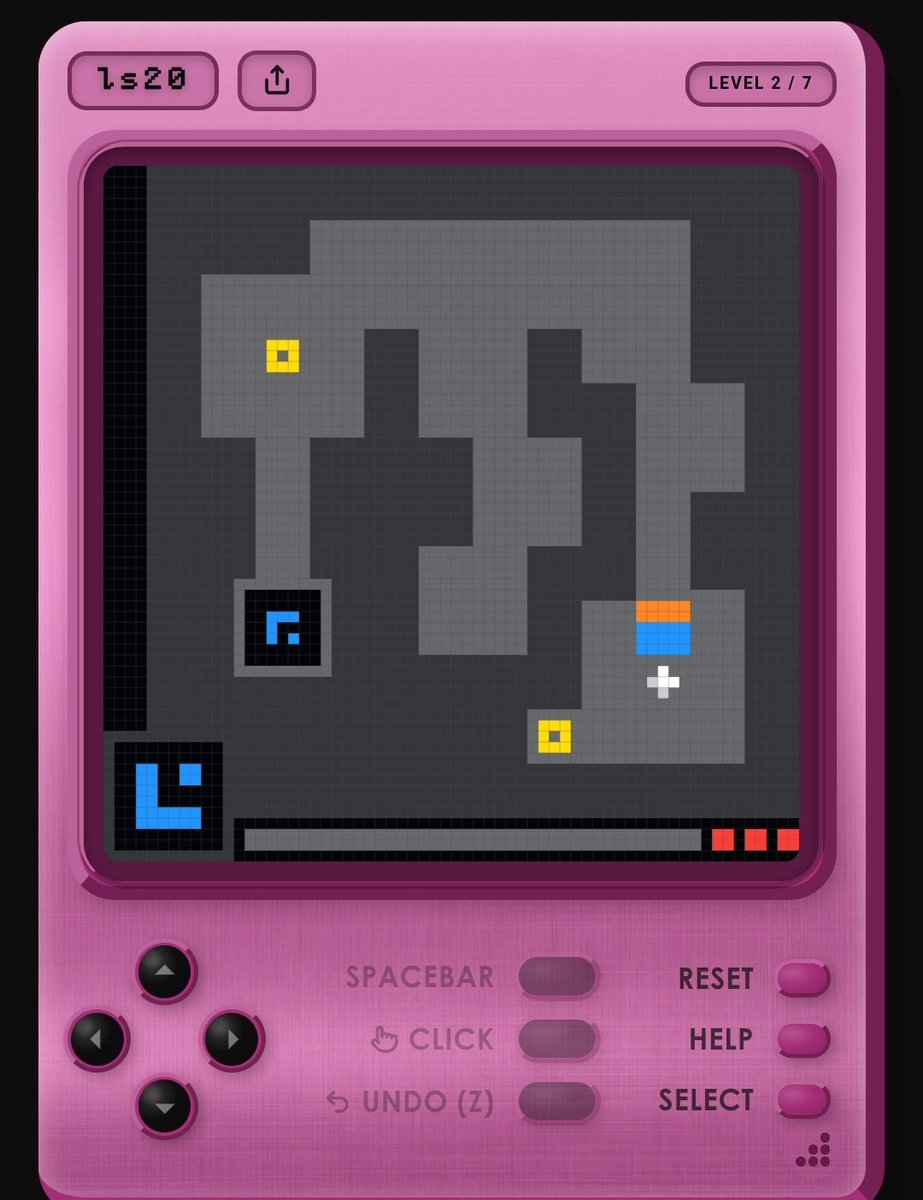
ARC-AGI-3 is out now! We've designed the benchmark to evaluate agentic intelligence via interactive reasoning environments. Beating ARC-AGI-3 will be achieved when an AI system matches or exceeds human-level action efficiency on all environments, upon seeing them for the first time. We've done extensive human testing that shows 100% of these environments are solvable by humans, upon first contact, with no prior training and no instructions. Meanwhile, all frontier AI reasoning models do under 1% at this time.
We scored 36.08% on ARC-AGI-3 in one day using the Agentica SDK.


