@jt_kerwin Haha they must have trained on Futurama scripts.
Lucy Liu: "I'll never forget you, Fry. MEMORY DELETED."
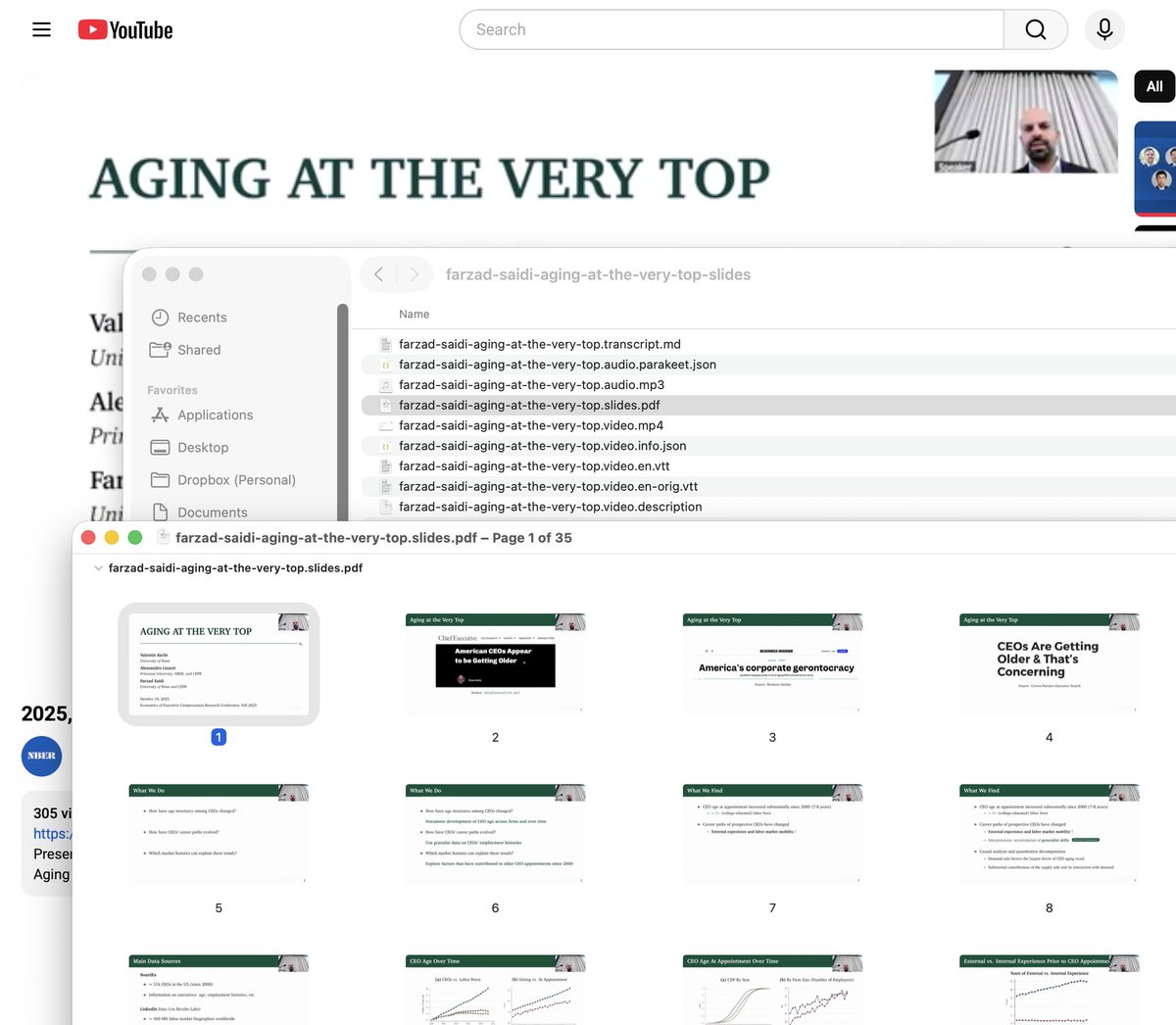
English
Joe Golden
633 posts
@JoeGoJoeGo
Current: https://t.co/C4lxGFEvou: Listen to your documents. Prev: https://t.co/swqBbwZmHL Co-founder/CEO. UMich PhD econ. Google / Microsoft / Upwork.




@MeganTStevenson Will be curious to see your and others' experiences. I just tried (using `--hybrid docling-fast --hybrid-mode full` and `--enrich-formula` and though super fast it was not good for the stuff other than text Attached is how gemini rated the conversions I got from the same paper

We had a fantastic conference discussion today (from Felipe Severino) so I had a chance to use a favorite LLM prompt to get a “improved” transcription to send to my coauthors May be useful; copyable version here: gist.githubusercontent.com/lukestein/6a4d…