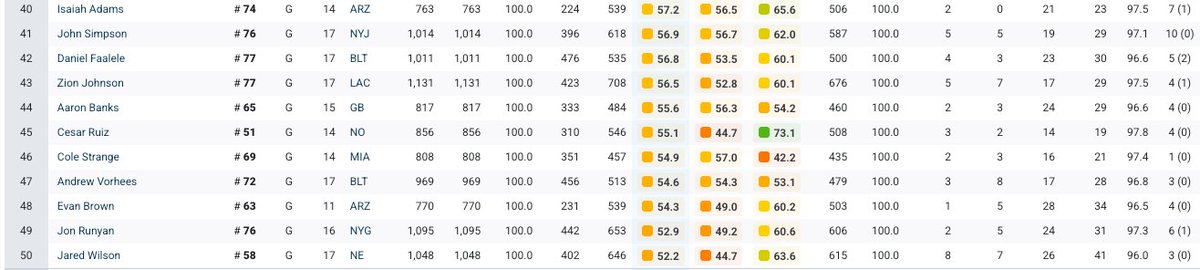
@ColeJacksonFB Look at his pff 2024 though (not 23 my bad) "Simpson had career-high grades across the board, earning a 77.3 overall grade, the 13th highest among guards, and a 79.2 run blocking grade, which also ranked top 10 at the position."
English