Sabitlenmiş Tweet
Kyle🤖🚀🦭
37K posts


Kyle🤖🚀🦭
@KyleMorgenstein
Full of childlike wonder. Teaching robots manners. RL @ Apptronik. UT Austin PhD candidate. Past: Boston Dynamics AI Institute, NASA JPL, MIT ‘20.
he/him Katılım Eylül 2018
5.3K Takip Edilen16.4K Takipçiler

Kyle🤖🚀🦭 retweetledi

Attention @arxiv authors: Our Code of Conduct states that by signing your name as an author of a paper, each author takes full responsibility for all its contents, irrespective of how the contents were generated. 1/
English
Kyle🤖🚀🦭 retweetledi

The community didn't wait for us.
Before we even released code for fine-tuning, training, and inference, builders were already deploying MolmoAct2 in the wild. So we're shipping faster.
Today: official LeRobot integration for MolmoAct2.
Train, evaluate, and deploy with standard LeRobot datasets and workflows — bring your own task, bring your own embodiment.
→ github.com/allenai/molmoa…
Can't wait to see what you build.
Jiafei Duan@DJiafei
Most capable generalist robotics models today are closed or at best, open weights. But robotics won’t reach its ChatGPT moment without real openness. That GPT moment was built on years of open tools and datasets such as Python, PyTorch, ImageNet and more, that let researchers inspect, reproduce, and build. Today, we’re introducing MolmoAct 2: a fully open-source action reasoning model for real-world robotics. We rethought and reshaped everything! 🧵👇
English
do I have any Japanese moots that would be willing to let me pay to ship this to the US from their address? quag is my favorite, I’ll do anything 😭
ポケモン公式@Pokemon_cojp
本日5月14日(木)から、ポケモンセンターオンラインで「ミニテーブル ヌオー」が注文受け付け中! ヌオーといっしょなら、おやつタイムがもっと楽しくなるかも……!? くわしくはこちらをチェックしてね! pokemoncenter-online.com/4521329467573.… #ポケモンセンターオンライン
English
Kyle🤖🚀🦭 retweetledi

Atrocious take, and I understand now why some of the old school RL people refuse to interact with LLM people.
"Who cares about the theory and the entire underlying body of work, just do the one simple instantiation that I use, nothing else is important."
Eric Zhang@ekzhang1
I feel it’s really unhelpful that searching for “deep RL” sends you to Q learning, MDPs, Bellman’s equation etc, when it’s literally just Run LLM agent on data -> was it good? -> policy gradient +/- reward Like that’s actually it! And LLMs are just stacks of attn+MLP
English
Kyle🤖🚀🦭 retweetledi
If Caffe, TensorFlow, or PyTorch had been closed to only a few; if the Transformer was never published; if ResNet had stayed inside MSR; or if ImageNet and Common Crawl had never been made available, we would not have the ChatGPT moment we see today.
Openness is not just a choice. It is a responsibility.
We are excited that MolmoAct 2 from @allen_ai can contribute, even in a small way, toward bringing the robotics community closer to its own ChatGPT moment.
Thanks @stepjamUK for featuring!
Stephen James@stepjamUK
Most open VLA models are not really open. They release weights and call it reproducibility. The training data is withheld. The training code is withheld. The deployment pipeline is withheld. You get a checkpoint file and a paper. You cannot verify the data quality. You cannot reproduce the training run. You cannot adapt it to your robot without starting from scratch. Researchers from Allen AI released MolmoAct2, the first VLA that is open. Weights, training code, complete datasets. • MolmoAct2-BimanualYAM Dataset: 720 hours of teleoperated trajectories across 28 real-world tasks, the largest open bimanual dataset available. • MolmoAct2-SO100/101 Dataset: 38,059 episodes curated from 1,222 public datasets. • MolmoAct2-DROID Dataset: Quality-filtered Franka trajectories with re-annotated instructions. The system deploys out-of-the-box on three platforms spanning the low-to-medium cost range. Bimanual YAM, SO-100/101, DROID Franka. No additional fine-tuning required. The backbone is Molmo2-ER, trained on a 3.3M sample corpus for embodied reasoning: metric distance estimation, free space detection, cross-view object tracking, scene geometry reconstruction. The skills general-purpose VLMs do not test. Results Look Promissing 63.8% average across 13 embodied reasoning benchmarks. Outperforms GPT-5 and Gemini Robot ER-1.5 on 9 of 13 tasks. Outperforms π0.5 across 7 simulation and real-world benchmarks. The architecture uses per-layer KV conditioning between the VLM and a flow-matching action expert trained with DiT-style transformers. This bridges discrete reasoning tokens to continuous control trajectories while exposing the attention state the VLM itself uses. This is the deployment model NeuraCore advocates for: standardized ecosystems with reproducible training data. Custom infrastructure for every embodiment is technical debt that prevents fleet scaling. Nice work from @hq_fang, @DJiafei, and the team at @allen_ai
English
@ChongZitaZhang for this kind of extremen behavior for sure, but I would be very surprised if there was any easier platform to do this very hard thing on!
English

anymal parkour spot version. pretty impressive this "old" robot can do similar things.
RAI Institute@rai_inst
Watch Spot crouch, jump, climb boxes and leap across gaps, controlled by a neural network trained with reinforcement learning (RL) and multi-expert distillation. Multiple expert policies were trained and distilled together into a single policy that was fine tuned to improve performance over diverse terrains. This work was inspired by ANYmal’s parkour capabilities. The neural network processes depth data from Spot's sensors to construct an understanding of the environment.
English
Kyle🤖🚀🦭 retweetledi

when my phd advisor asks me for a weekly update on my experiments
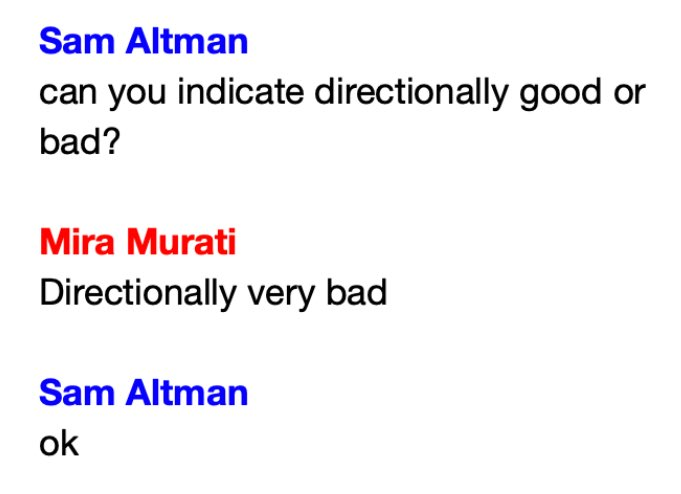
English
@macjshiggins Currently using it with my lerobot arms, mostly just pick and place stuff but it’s been v fun
English

@KyleMorgenstein I totally forgot. Did you do anything cool with it?
English
LinkedIn gorilla marketing tactics for the first equation they teach you in undergrad robotics courses.
/tau = K * I
What are we doing man.
Antonio Li@AntonioSitongLi
My robot can now feel how hard it's gripping something. I didn't add any sensors. Comment "tactile" and I'll DM how it works.
English
@macjshiggins Also it’s been about a year do you want your zed mini back or can I pay you for it
English
@macjshiggins I was thinking of you and that “I just discovered slam” guy from f dot lol
English

@KyleMorgenstein The word you're looking for is "guerrilla"
English

🎉 Life update: I joined @GoogleDeepMind as a Student Researcher.
Last week I started my internship at the Gemini Robotics team in London, building the new generation of physical AI with the group of talents I had been only hearing from papers 🧠
Excited about this new journey!

English
@AntonioSitongLi Nice! It’s very cool work and I’ve seen many of your other great engineering projects. I just have to rag on the engagement style 😭
English

@KyleMorgenstein Ahahah, sorry for the engagement bait. To add one thing to your comment, the main insight is actually utilizing the soft gripper so that you can calibrate the current used over the gripper deformation curve. This gives you a progressive force response.
English

Excited to share @tutorintel's Data Factory 1, a 100 robot semi-humanoid research farm and the largest robot data factory in the United States.
Our first embodiment “Cassie” is deployed at industrial scale across the supply chain. We built DF1 to bootstrap fleet-scale learning for our "Sonny" industrial semi-humanoid embodiment, powered by our first end-to-end robot foundation model Ti0.
English