
ttt
34 posts


@teortaxesTex Whale definitely rolled back a version; last night's version was better than today's, and the CoT is different. There might be a problem with the deployment of last night's model.
English

Preliminary: it's pretty much the same as earlier this week
whale fail
English
fixed now, at approx. 10 AM Monday in China. (DeepSeek API status hasn't yet registered that all systems are green).
ok, I guess it's just a V4-lite update from yesterday (if not merely an unprecedented system failure). Let's get to testing.

Teortaxes▶️ (DeepSeek 推特🐋铁粉 2023 – ∞)@teortaxesTex
Every time. They're failing to separate the output block upon <end_of_thinking> token. Now why would that be the case? I hope that it *is* a new model, perhaps with a new tokenizer, perhaps because it's built for reasoning_effort; and the webui isn't 100% updated yet.
English


Follow the professional evaluation of Zhihu contributor toyama nao, and dive into Xiaomi’s newly-released MiMo-V2-Pro, uncover its all-new multi-model architecture for the Agent era.
In short:
Xiaomi's big model is built to be the new foundation for the Agent era from the start 🚀 Battle-tested MiMo-V2-Flash acts as the reliable workhorse, and the new release completes the Agent-era puzzle: flagship Pro leads task planning & decomposition with intellectual prowess, Omni handles multi-media data, and a TTS model adds voice—forging a clear all-round multi-model architecture.
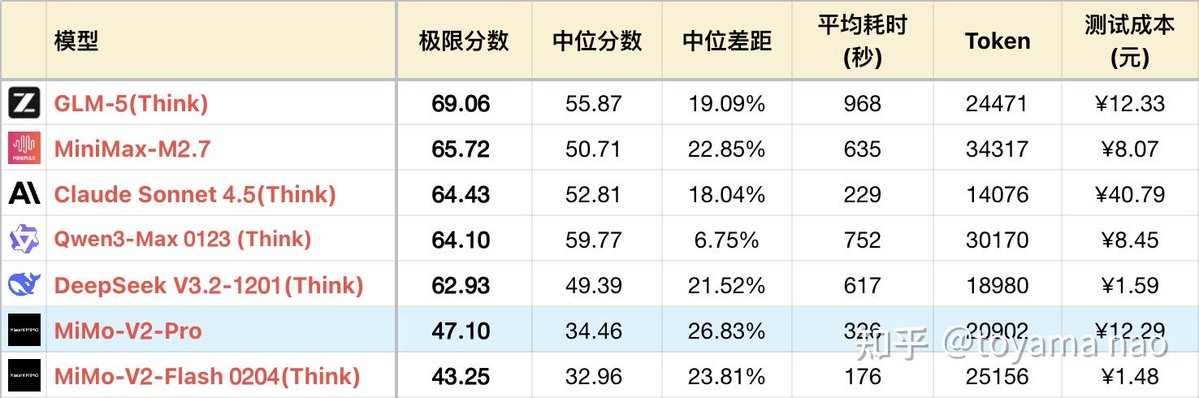
Though MiMo-V2-Pro hits the 1 trillion parameter mark, its intellectual performance lags behind GLM-5 and Qwen3-Max 📊 It has high output randomness at recommended temperature parameters, with median score only slightly above Flash.
But Pro’s knowledge reserve is rock-solid: it shines in creative writing & document analysis, and boasts top-tier insight in literature/history—far outperforming DeepSeek V3.2 and Qwen3-Max here. In its core Agent-driven tasks, Pro matches popular models in stable ultra-long task handling, yet its slight premium pricing blunts the edge.
🌟 Key Upgrades vs Flash
✅ Insight: Emerges with sufficient parameters—masters logic/ pattern-finding tasks Flash couldn’t crack (e.g., solves #24 pattern task easily, finds half the correct words in #57 word hunt with just 23K Tokens). Caveat: Insight is inconsistent (small chance of peak performance—retry for better results).
✅ Instruction Following: Nails simple, clear multi-instruction execution; lower limit far exceeds Flash’s best. Ranks top tier among domestic models in this aspect (overall reasoning in 2nd tier). Struggles with complex/poorly structured instructions.
✅ Multi-turn Dialogue: Passes basic tests, stably tracks core goals—only if context is not overly cluttered (risk of goal drift with heavy background).
⚠️ Major Shortcomings
❌ Coding Ability: Writes code like early GPT-5.2/5.3-Codex (no self-test by default) but lacks Codex’s solid fundamentals—code success is hit-or-miss 🧑💻 Only fixes surface bugs (no root-cause analysis), has a weird "log phobia" (refuses to add/keeps deleting logs even when requested). Outdated UI design (mid-2024 level) vs GLM-5, MiniMax M, Seed Code.
❌ Hallucinations: A long-standing issue for MiMo—little improvement from Flash, even worse in some scenarios ❗ Repeats/invents numbers in #43 24-game variant, mixes up two requirements in #50 log analysis due to long context.
📈 Big Picture for Xiaomi
Xiaomi is racing to build a full hardware+software ecosystem for next-gen personal devices ⚡
• Hardware: in-house SoC, premium flagship phones, best-selling NEVs, global smart home gear.
• Software: in-house mobile OS, computing infrastructure, and the MiMo model family.
Despite gloomy 2025 phone sales prospects amid hardware price hikes, a groundbreaking hardware-software integration product could make users accept premium pricing.
The path is clear—Xiaomi just needs to sprint fearlessly toward the dawn.
🔗original article:zhihu.com/question/20177…

English

> Process reward models
tfw I still underestimated the whale
got it right about huggingface though
Teortaxes▶️ (DeepSeek 推特🐋铁粉 2023 – ∞)@teortaxesTex
they sure do, but the first legitimate paper on "how to reproduce o1 from scratch" will be called something like DeepSeek-R1: chain of thought with robust self-correction using process reward models, Shao et al 2025, and weights will land on hf hours before it hits arxiv
English

今天看腾讯大厦装龙虾这件事,挺有感触。
最近很多大厂都在疯狂让一线非技术员工去安装龙虾,网上甚至真有 500 上门安装服务。大家都在拼命找使用场景,拼命要求落地,拼命证明这个东西已经重要到不能错过,整个过程让我有一种很强的赛博科技折叠感。
看到一句话很有意思,连龙虾都不会装的人,怎么会用龙虾呢。再往前一步,连基本使用都没有建立起来,却要先做出完整场景,做出结果,做出价值证明,这本身就更难。
这背后有两个东西叠在一起。一个是错觉,很多老板看了太多视频号切片,被各种夸张叙事和万能案例反复轰炸以后,真的会产生一种幻觉,觉得这东西什么都能做,哪里都能接,谁都该装,装了就应该立刻有产出。另一个是焦虑,大家又都怕错过这一波,于是开始用行政动作去推动,用集体焦虑去代替真实需求。
所以你会看到一种很强的反差。一边口号非常大,仿佛人人都要进入 AI 原生时代。另一边是大量人连自己到底有什么事情值得交给它做都说不清楚。这个反差后面只会越来越强,而且会越来越荒诞。
因为工具从来不会靠安装产生价值,工具只会靠任务密度、流程清不清楚、结果能不能看出来来产生价值。没有连续任务,没有 SOP,没有线上完成的条件,没有明确的输入输出,再强的东西放在那里也只是一个图标。它不会因为被装上了,就自动长出场景。
所以我一直觉得,龙虾并不适合所有人。
它很适合指挥者,很适合一人公司,也很适合那种脑子里一直有事情要往上做、能把工作拆成步骤、并且很多事情都能在线上完成的人。尤其是你用过 skills 和 tools,也知道 AI 本身的能力边界,能把流程串起来、把场景搭起来、把事情一步步做完,这种时候就会非常合适。
比如对我来说,这个场景就很自然。特别是有大量事情要往上做,但是刚好不在家里不在公司,在外带着手机,或者不方便开电脑的时候,我会让我的两个 nanobot 去检查我的开源产品 issue,产出技术方案,然后另外一个去 review、去提交,一气呵成。让我早上上班坐车路上,就把事情优雅做了,真是方便。
但是对于一个平时本来就没有什么工作要在外面完成的人,甚至回到家连电脑都不想开的人,怎么可能硬有场景去做事情。吃好玩好就很舒服啦。没有场景就是没有场景,真的不用焦虑。
我觉得这一波最容易被放大的,不是能力差距,是场景差距。有场景的人会越用越顺,越跑越快,最后像多了几个分身。没有场景的人,就很容易在概念、教程、案例、视频里来回打转,最后除了多装几个软件,什么都没变。
很多人今天最大的问题,也不是没装龙虾,而是把装了某个工具,当成自己已经进入了 AI 时代。其实真正的分水岭,一直都在任务理解、流程设计、结果判断这些地方。你到底有没有持续的问题要解决,你能不能把问题拆出来交给系统,你能不能判断结果是不是对,这些才决定了你能不能真正从 AI 里拿到价值。
所以无需焦虑。没有场景的时候,硬装龙虾意义不大。
真想体验这代 AI 到底强在哪里,不如花 20 刀去包一个 Claude Code,或者更有趣一点,再包一个 ChatGPT 会员,用 GPT 5.4 去帮你处理一个你自己真觉得很难的事情,产出方案,推进执行,体验一次这种简单、高效、直接把问题解决掉的过程,这比装一个龙虾好太多了。
龙虾适合有场景的人,适合指挥者,适合一人公司,适合那些可以把流程 SOP 化、线上化、一步步做完的人。它当然很强,但它不是靠被安装来证明自己强,是靠替你完成工作来证明。
很多人今天在装的是龙虾,真正更该先想明白的是一句话,我到底有什么问题,值得交给 AI 去解决。
这件事,可能比装什么都重要。
中文
@teortaxesTex I heard that web-v4-lite isn't using engrams yet, and that they've had some delays or restarted training several times for some reason. This V4 project might not have been running for very long, so they've been doing post-training.
English
@teortaxesTex No this promise. He said Whale has been optimizing V4, perhaps feeling it's not yet satisfactory.
English
> Rumors say DeepSeek V4 (multimodal) could drop as soon as next week.
man I wish
but let's stop pretending anyone knows anything

Zhihu Frontier@ZhihuFrontier
Rumors say DeepSeek V4 (multimodal) could drop as soon as next week. What might actually be new in it? 💬 From a technical & special perspective, Zhihu contributor 普杰 argues the key isn't products — it's which new technologies land in the model. Historically, each DeepSeek release shipped a core technique 👇 • R1 → Chain-of-Thought reasoning • V3.1 → Native reasoning control • V3.2 → New attention (DSA) + tool-use CoT + competition-level RL So the real question: what tech does DeepSeek still have that hasn't landed yet? Possible candidates include: 1️⃣ NSA attention 2️⃣ DeepSeek-OCR2 multimodality 3️⃣ Enhanced MHC residual architecture 4️⃣ Engram (memory–reasoning separation) 5️⃣ Domestic GPU support 6️⃣ New efficient data structures 7️⃣ Reinforcement learning upgrades Let's break them down. 1️⃣ NSA attention — very likely already deployed A tester fed the model an entire novel (~1M tokens) using a rarely circulated book to avoid pretraining leakage. The model could summarize the plot, retrieve passages, reconstruct story structure and describe characters All in one output, with no obvious errors — and very fast inference, suggesting NSA handles ultra-long context. 2️⃣ DS-OCR2 multimodality — probably not yet The current web model (often called "V4 Lite") still appears text-only. Also, DeepSeek-OCR2 reportedly uses Qwen's vision encoder, suggesting DeepSeek may still be building its own vision stack. 3️⃣ Enhanced MHC residual architecture — possible MHC claims better scaling efficiency for large models. Given DeepSeek's tight compute budget, adopting training-efficient architecture would make sense. 4️⃣ Engram — unlikely this release Engram should significantly reduce hallucinations. But V4 Lite doesn't show dramatic improvements, and the paper appeared quite recently, so it may have missed the V4 timeline. 5️⃣ Domestic GPU support — plausible Unlike big tech firms that can train overseas, DeepSeek has stronger incentives to optimize for domestic hardware. Compute constraints make this increasingly attractive. 6️⃣ New efficient data structures — very likely DeepSeek consistently pushes extreme efficiency. • V3's cost advantage relied heavily on FP8 • Competitors like Kimi are already exploring INT4 So V4 could experiment with INT4, NF4, or new FP8 formats. 7️⃣ Reinforcement learning — possible surprises DeepSeek has strong RL capabilities. Both R1 and V3.2 Speciale relied heavily on RL training. V4 could push further with agentic RL, potentially targeting Claude-level reasoning or beyond. V4 may arrive within weeks — and we'll quickly see which predictions are right. 📖 Original discussion: zhihu.com/question/20115… #DeepSeek #DeepSeekV4 #AI #LLM #Multimodal #Research #Tech
English
@Ji_Ha_Kim Wow, that's amazing! It reminds me of that “mod 998244353 (2²³*119+1)” .
English

Transformer addition with 1 parameter
I think integer addition is too easy for transformers because of the geometry. Here the trick is softmax on uniform vector = mean.

Dimitris Papailiopoulos@DimitrisPapail
The 10-digit addition transformer race is getting ridiculous and fun! Started with 6k params (Claude Code) vs 1,6k (Codex). We're now at 139 params hand-coded and 311 trained. I made AdderBoard to keep track: 🏆 Hand-coded: 139p: @w0nderfall 177p: @xangma 🏆 Trained: 311p by @reza_byt 456p by @yinglunz 777p by @YebHavinga Rules are simple: - Real autoregressive transformer (attention required) - ≥99% on 10K held-out pairs - No hard-coding the algorithm in Python Submit via GitHub issue/PR.
English
@teortaxesTex Inventions require too many mothers; they are simply one of them.😅
English
«So really, I think we should just give DeepSeek more graphics cards». So true…
This paper really goes to show how despicable the "necessity is the mother of invention" peasants are. Creativity is the mother of invention. Better not waste it on «how do we unfuck these H800s».


karminski-牙医@karminski3
DeepSeek 又发新论文啦!给大家带来解读。说实话这次的论文我看完了心里挺不是滋味 DeepSeek 联合北大、清华发了一篇新论文 DualPath, 解决了一个很多人可能没意识到的问题: 在 Agent 场景下, GPU 大部分时间不是在算, 而是在等数据从硬盘搬过来. 先说背景. 大家都知道现在 AI Agent 任务火爆. 问题是: 每一轮上下文的 95%以上都是之前轮次的"旧数据" (KV-Cache), 只有一丁点是新的. GPU 其实没多少活要干, 但它得等着把之前的 KV-Cache 从存储里读出来才能开工. 现在主流的推理架构是 Prefill-Decode 分离 (PD分离), Prefill 引擎负责理解输入, Decode 引擎负责生成输出. 在这种架构下, 所有的 KV-Cache 都只能从存储加载到 Prefill 引擎, Prefill 侧的存储网卡(只有400G带宽)被挤爆了. 那咋办? 加网卡吗? 且慢, Decode 侧也有存储网卡, 这个卡在Prefill阶段是在摸鱼的! 所以得想办法利用起来! DualPath 的核心思路是: 既然 Prefill 侧堵死了, 而 Decode 侧空着, 那为什么不让数据也走 Decode 侧, 再通过 GPU 间的高速计算网络(这个IB网络带宽足足有3.2T) 传输回 Prefill 机器. 说实话在我来看这是个脏优化, 不符合架构直觉, 有点类似家里要炖汤, 结果汤锅装不下, 只能用炒勺也炖, 等汤锅闲下来了再把炒勺的转移到汤锅里. 也算是无奈之举了. 所以带来的问题是: 显卡间的IB计算网络上还跑着模型推理的集合通信呢! 这些对延迟极其敏感. 你要是 KV-Cache 搬运把计算网络堵了, 那推理性能反而会更差. DualPath 的解决方案是: 所有进出 GPU 的流量全部走计算网卡, 利用 InfiniBand 的虚拟通道做流量隔离, 推理通信走高优先级通道, 独占 99% 带宽保障; KV-Cache 搬运走低优先级通道, 只捡空闲带宽用. 搞过网络 QoS 的同学应该能 get 到这个设计. 收益是: 离线推理吞吐最高提升 1.87x, 在线服务吞吐平均提升 1.96x 所以真的, 我觉得多给DeepSeek点显卡吧, 搞这种优化真的是无奈之举, 大家都在期待你们搞模型上的创新. 在线阅读地址:swim.kcores.com/DualPath%20Bre… 往期合集:github.com/karminski/teac…
English
感觉来自用户的多样化的提示和反馈轨迹真是太重要了,这不是几个工程师能构建出来的。
POM@peterom
Deepseek got called out for scraping 150k Claude messages. So I'm releasing 155k of my personal Claude Code messages with Opus 4.5. I'm also open sourcing tooling to help you fetch your data, redact sensitive info & make it discoverable on HF - link below to liberate your data!
中文


ttt retweetledi

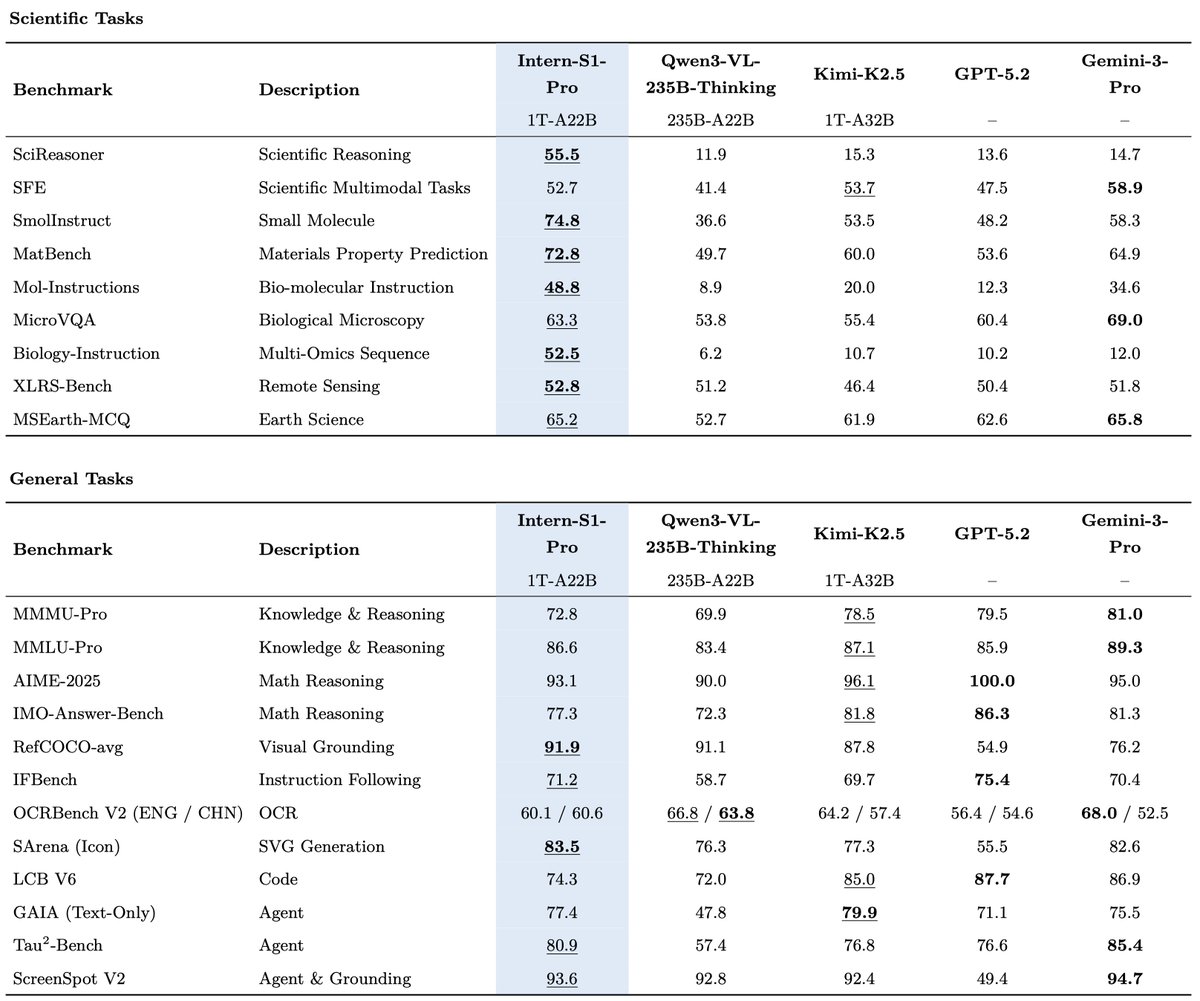
🚀Introducing Intern-S1-Pro, an advanced 1T MoE open-source multimodal scientific reasoning model.
1⃣SOTA scientific reasoning, competitive with leading closed-source models across AI4Science tasks.
2⃣Top-tier performance on advanced reasoning benchmarks, strong general multimodal performance on various benchmarks.
3⃣1T-A22B MoE training efficiency with STE routing (dense gradient for router training) and grouped routing for stable convergence and balanced expert parallelism.
4⃣Fourier Position Encoding (FoPE) + upgraded time-series modeling for better physical signal representation; supports long, heterogeneous time-series (10^0–10^6 points).
😍Intern-S1-Pro is now supported by vLLM @vllm_project and SGLang @sgl_project @lmsysorg — more ecosystem integrations are on the way.
☺️Model:@huggingface
huggingface.co/internlm/Inter…
☺️GitHub:
github.com/InternLM/Inter…
☺️Try it now at:
chat.intern-ai.org.cn

English

@Shanimajibai @teortaxesTex @GDemonolog75720 @larptab 🤣I used to think only humans looked like this, but it seems that the environments of Europe and Asia really did influence the evolution of eye sockets and nasal bridges.
English

@teortaxesTex @GDemonolog75720 @larptab Do European foxes have Hajnali culture too?
Do Tibetan foxes have arranged marriage?


English
Other observations collected by Einstein:
> the Chinese are incapable of being trained to think logically and that they specifically have no talent for mathematics
>intellectual inferiority in business skills
- By Tadashi Hama
sdh-fact.com/review-article…

Teortaxes▶️ (DeepSeek 推特🐋铁粉 2023 – ∞)@teortaxesTex
Einstein too despised the Chinese. Low izzat race Tolerance of hard repetitive work is generally a mark of subhumanity to cultures without strong agricultural tradition: Brahmins, Jews, modern Westoids. They will mock the "peasant" Asian grindset ruthlessly. underrated bias
English

他妈的,拉胯了,这里的免费不是真免费
他指的是 Kimi 2.5 是开源的所以叫免费,真离谱
我就说怎么 kimi 没搭茬
OpenClaw🦞@openclaw
🦞 OpenClaw 2026.1.30 🐚 Shell completion 🆓 Kimi K2.5 + Kimi Coding: run your claw for free 🔐 MiniMax OAuth: one more model just a login away 📱 Telegram got a glow-up — 6 fixes from threading to HTML rendering Plus a bunch of community-contributed fixes across LINE, BlueBubbles, routing, security & OAuth. The lobster provides 😏 github.com/openclaw/openc…
中文
@teortaxesTex The upload date for K2.5 on huggingface is January 1, 2026, but it's been delayed for a long time before being announced. According to rumors, Kimi has something new coming up (I don't know if it's K3), and Zhipu might also release soon.
English
K2.5 is a V3 generation model, explicitly built on V3 architecture. It's not frontier within Moonshot's own portfolio. They just pushed continued training further than anyone.
V4 is all but guaranteed to do vastly better. Its competition will come from K3, GLM-5. Next gen.
logan Wengfeng🐳🐲@love_deepseek
@teortaxesTex Will it surpass Kimi k 2.5?
English

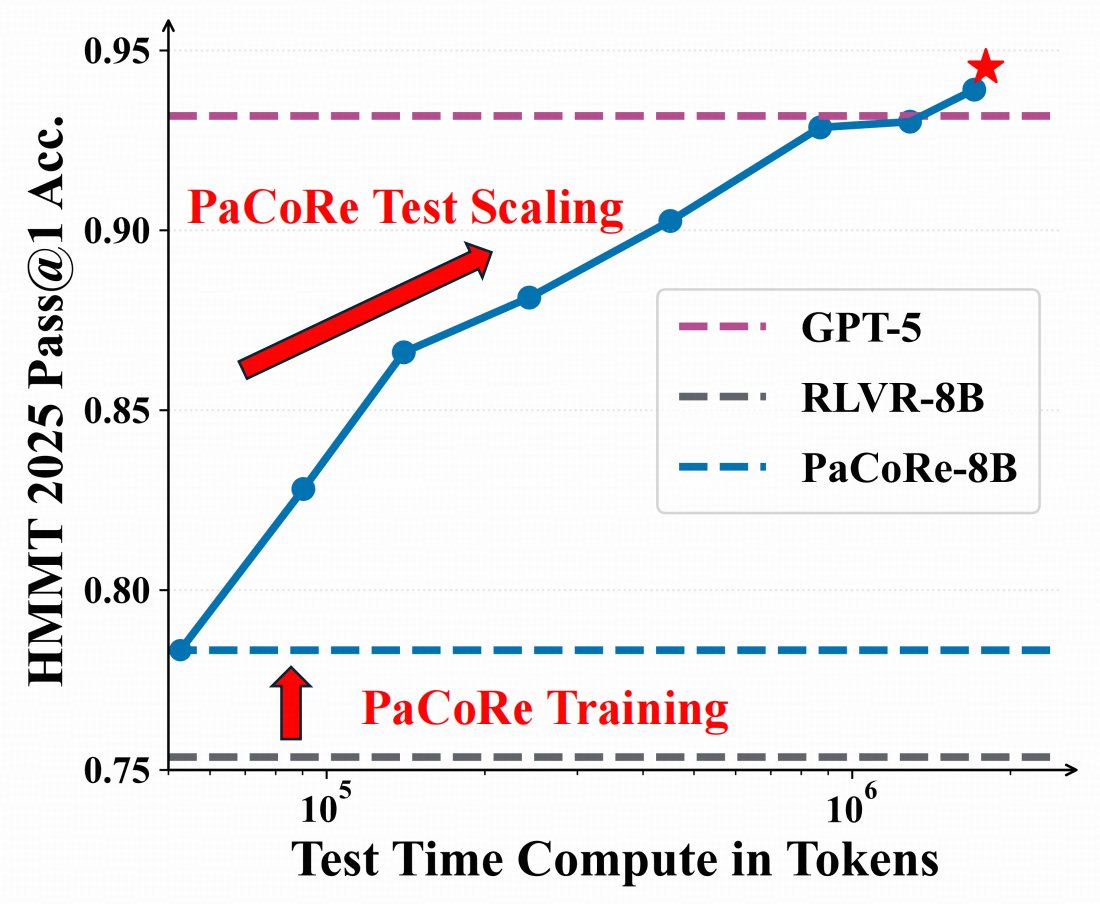
🤯 8B model > GPT-5 on math ?
🌠Introducing Parallel Coordinated Reasoning (PaCoRe)——open source deep think.
📚Decouple reasoning from context limits → multi-million-token TTC.
🤩With this new paradigm, even an 8B model can push the effective per-problem TTC context to multi-million tokens, surpassing proprietary systems like GPT-5 Thinking.
🔢 Math (HMMT25): 94.5%,beating GPT-5's 93.2%, powered by ~2M-token TTC
🤖 Coding (LiveCodeBench2408-2505) : 78.2% , competitive with frontier models。
Model checkpoints, training data, and inference pipline are now MIT-licensed and fully open-source.
Fork it, test it, build with us!
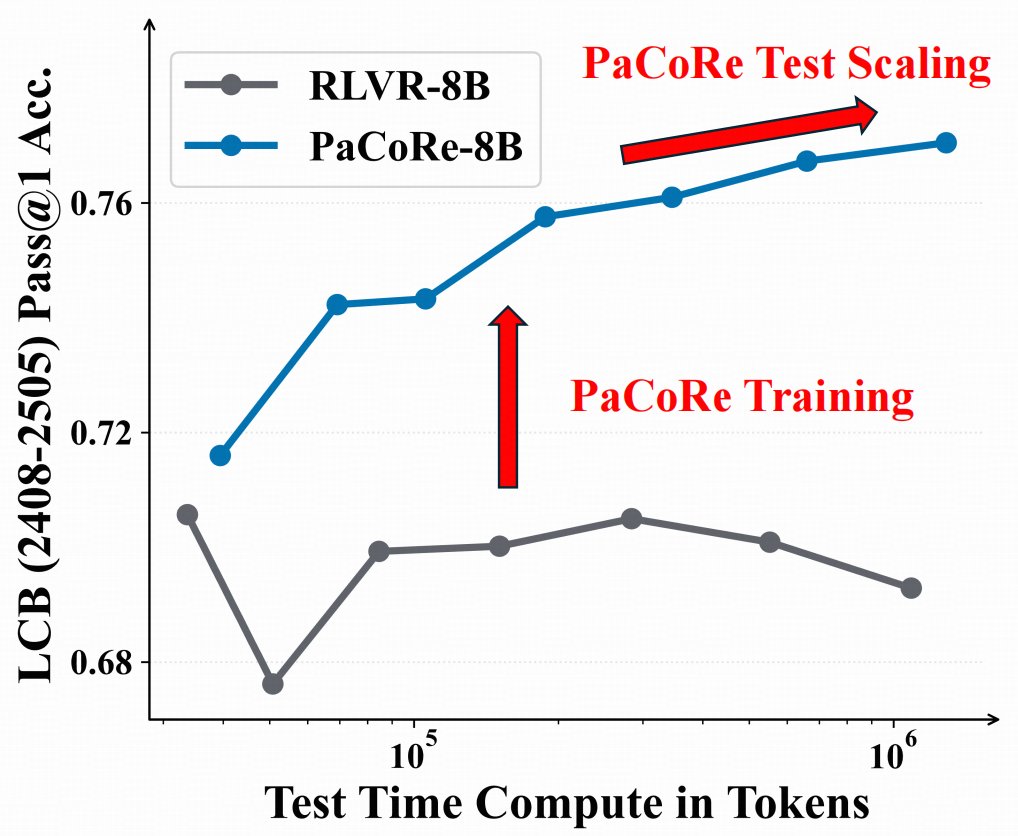
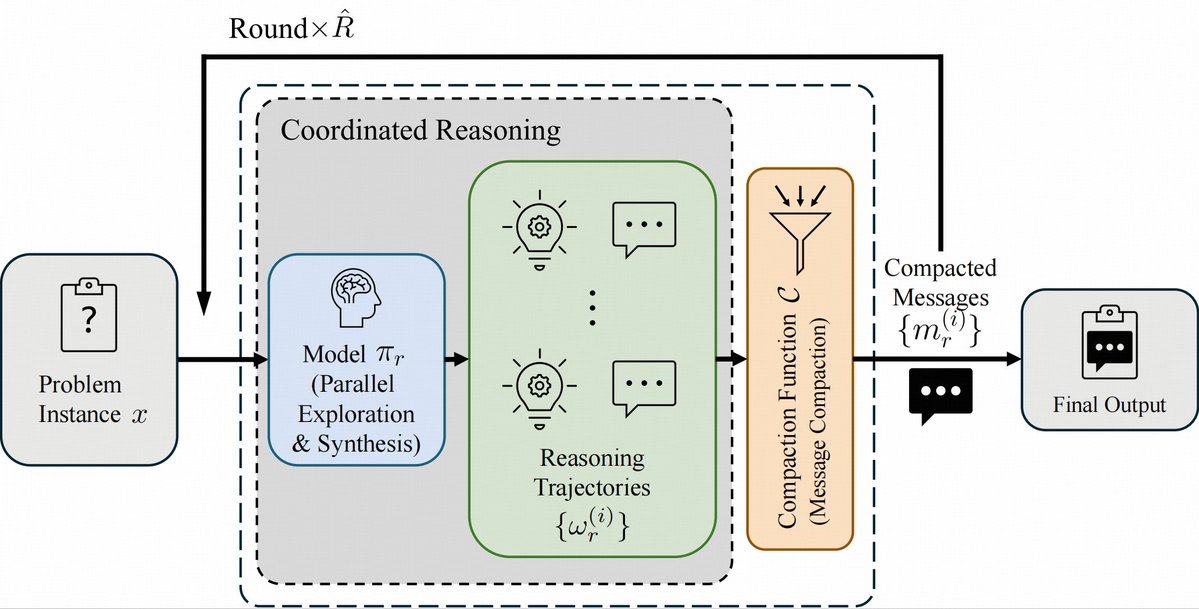
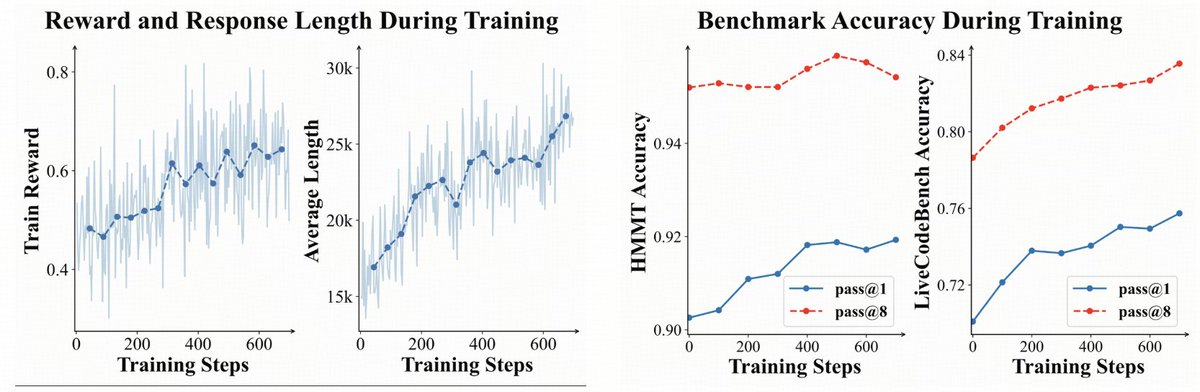
English
@DoggyDog1208 @teortaxesTex 招生人数不能代表高考裸分名次,我自己身为小镇学生,也是后来才知道原来进入清北有那么多种方式。我是在河南进行的高考,我们那里裸分考上清北需要前70名,远高于招生人数对应的排名,所以100名考不上很正常。不过其实我觉得高考前几十到前几百名都差不多,走上社会之后没必要纠结这个。
中文

@teortaxesTex Seems unlikely. 🤔
If so, he most likely would have qualified for Tsinghua/PKU.
Guangdong is on the low end of allocations but mental math still says 150-200 Tsinghua admits a year and probably a similar number to PKU.
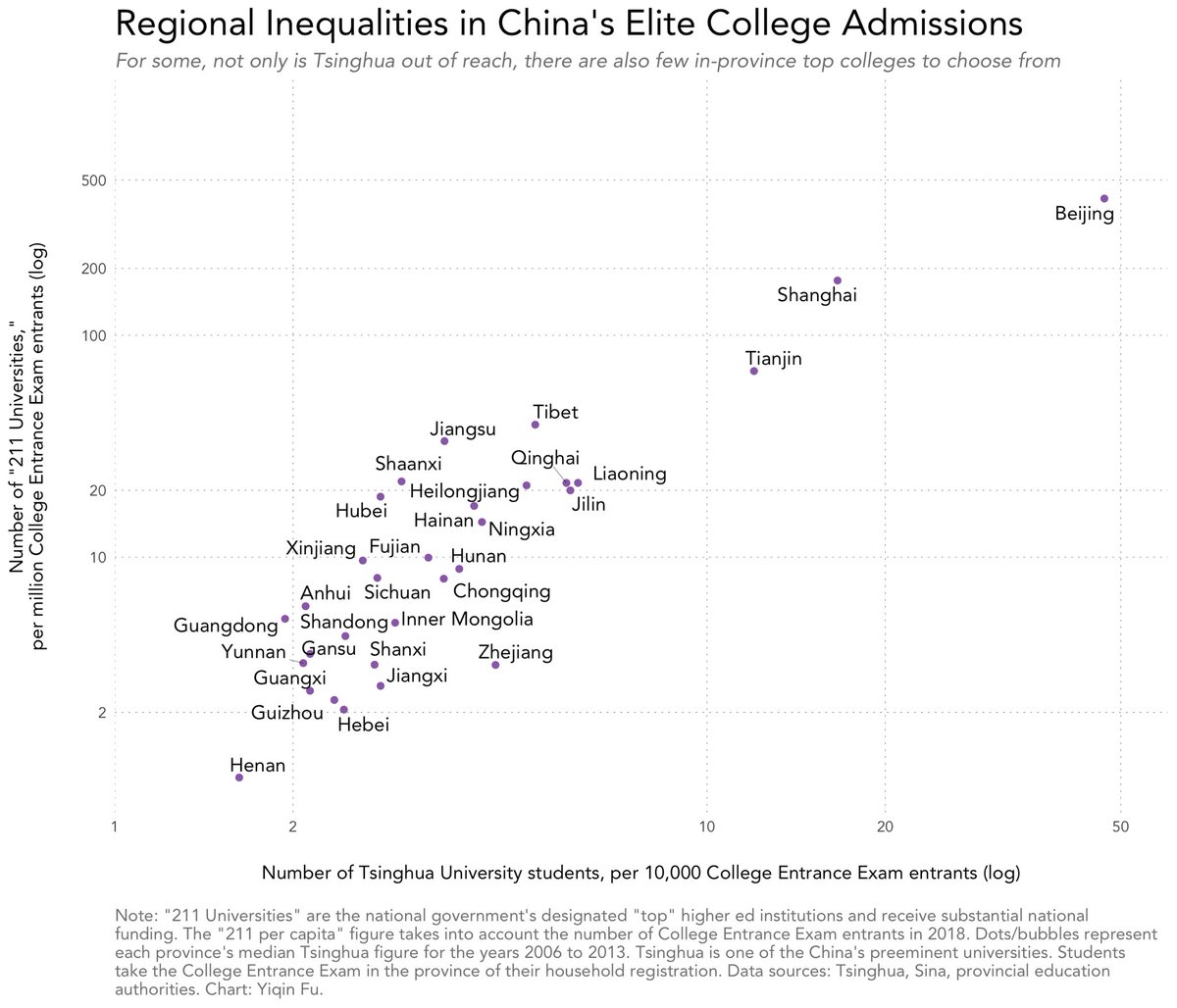
English
top response casually claims that Wenfeng scored around #100 on Gaokao in Guangdong Province (pop. 127M).
That's… pretty high. @DoggyDog1208 estimate?

Teortaxes▶️ (DeepSeek 推特🐋铁粉 2023 – ∞)@teortaxesTex
Discovered on LessWrong: a classmate's insight into Wenfeng the person. We already knew he's a huge outlier, polymath, maverick etc. etc. But what is new here: he's a strong electrical engineer. It never was software-only. I can see how he feels they could make their own chips.
English