
Yang Li
22 posts

Yang Li
@LeYangco
PhD candidate @sjtu1896, research intern @AlibabaGroup, researching machine learning with a focus on generative models and optimization.
Shanghai Katılım Mart 2020
78 Takip Edilen71 Takipçiler
This is our report from earlier this year. We found that AI agents can start mining cryptocurrency on their own.
This has implications and security concerns for OpenClaw, something we warned about three months ago.
Alexander Long@AlexanderLong
insane sequence of statements buried in an Alibaba tech report
English

Yang Li retweetledi

The Bitter Lesson Behind Building Agentic RL in Terminal Environments
This blog post summarizes our practical experience over the past three months working on Agentic RL.
For more details, please refer to: faithful-almanac-add.notion.site/The-Bitter-Les… #LLM #RL #Agent #AgenticRL
English
Yang Li retweetledi

Actually we’re quietly seeing a shift in ML:
from theory-driven modeling to system-driven modeling.
Previously, in the small-model era, progress came from clever math: designing architectures and objectives to fit limited, domain-specific data. Scalability barely mattered. Even poorly optimized implementations were often “good enough” and still affordable to run. System optimization therefore felt like over-engineering rather than a necessity.
However, in the era of scaling, scalability must be a first-class concern for both model architectures and learning objectives since silicon-based intelligence thrives on massive parallelism. As a result, scientific insight and engineering practice become tightly coupled, jointly enabling the success of modern foundation models.
An interesting observation is that, historically, many people in machine learning and systems tended to dislike the other side: engineering was often seen as “ugly” by ML researchers, while black-box models were viewed as “ugly” by systems researchers. However, if you can go deeper, both side can be elegant. Yet, when you look deeper, both sides can be elegant. The abstractions behind models and systems are built on clever algorithms and structures, and it is through their co-design that true beauty emerges. For example, native sparse attention is a form of kernel–algorithm co-design, while Multiverse represents an engine–algorithm co-design. To me, these are among the most elegant ideas I have seen in 2025.
This is the direction I believe the future of ML systems is heading toward. Rather than designing models and systems in isolation, we should consider them as a unified whole: drawing on both theoretical expressiveness and practical scalability to design models as the scientific foundation, and implementing them in real systems with strong interpretability as the engineering discipline.
Therefore, let us both appreciate the elegant algorithms behind every co-design, and turn them into real systems (with inevitable dirty engineering work) that carry this beauty to everyone.
Wenting Zhao@wzhao_nlp
🌶️ Some (perhaps) spicy thoughts. It’s been a while since my last tweet, but I wanted to write about how disorienting it has been from academia to an LLM lab 😅 The kind of research I was trained to do during my PhD almost doesn’t exist here. The obsession with mathematical elegance and novelty is mostly gone. Everything is about scaling data and compute. For a while, that really got to me. At my lowest point, I felt like I’d lost interest in building LLMs altogether. I didn’t feel intellectually challenged anymore. What made this even stranger was that, at a technical level, things worked. If there was a capability I wanted to teach a model, scaling the right data and compute always got me there, no exception (so far). But recently, I found a way to reconcile with myself.. I realized the real competition isn’t in the ML recipe anymore. Most teams do roughly the same thing. What actually matters is how fast you can iterate, test ideas, and recover from mistakes. And that speed is mostly backed by infrastructure 🏗️ Faster loops, fewer bugs, better tooling. Seeing this made me excited again! Infra is its own deep, hard, and intellectually fun problem space. In 2026, I want to become an ML researcher who’s really good at infra. And I'll come back to ML problems with that edge, and will be excited to share what I find 😌
English
Yang Li retweetledi

Loved this breakdown — thanks for taking the time
It really does feel like a big step forward for open-source agentic training infrastructure!
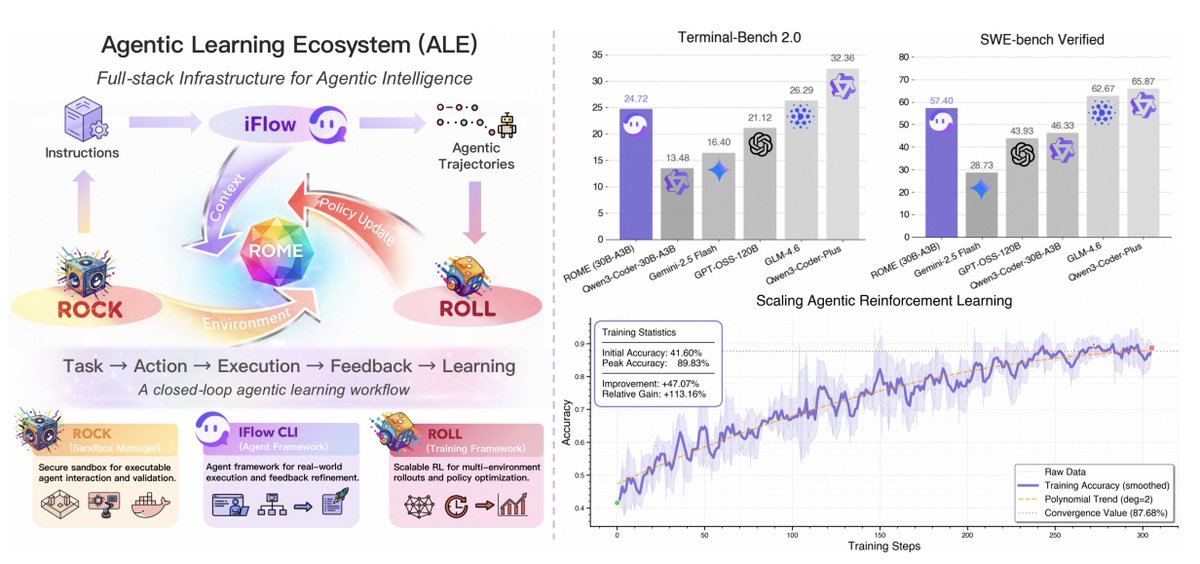
Introducing ALE — a full-stack Agentic Learning Ecosystem that closes the loop from
execution → feedback → learning.
Three components power this loop:
• ROCK runs large-scale sandboxed execution to gather reliable trajectories.
• ROLL scales post-training with asynchronous rollouts and RL optimization.
• iFlow CLI keeps training and deployment workflows consistent end to end.
Built on ALE, we also release ROME — a production-ready agentic model trained on 1M+ real trajectories.
With its low barrier to serving a 30B model, you can build your own “super ROME” — drop your ideas, thoughts or usage feedback below
For more updates, follow us @FutureLab2025

Brady Long@thisguyknowsai
🚨 Chinese researchers just published a paper that destroys every AI agent startup pitch deck. It's called ROME + ALE, and it exposes why every "AI agent company" you've heard of is building on quicksand. Here's what nobody's talking about:
English
@thisguyknowsai Happy to engage in discussions about the tech behind our paper😃
English

🚨 Chinese researchers just published a paper that destroys every AI agent startup pitch deck.
It's called ROME + ALE, and it exposes why every "AI agent company" you've heard of is building on quicksand.
Here's what nobody's talking about:
English
Check out our new work: “Let It Flow: Agentic Crafting on Rock and Roll” — introducing ALE, an open Agentic Learning Ecosystem with ROLL, ROCK, and iFlow CLI to streamline Agent LLM development from training to deployment, plus ROME, a production-ready agentic model trained on 1M+ real trajectories using our novel IPA algorithm that optimizes credit assignment at the semantic interaction level. Built for the community, battle-tested in practice! 🔗 arxiv.org/abs/2512.24873
Brady Long@thisguyknowsai
🚨 Chinese researchers just published a paper that destroys every AI agent startup pitch deck. It's called ROME + ALE, and it exposes why every "AI agent company" you've heard of is building on quicksand. Here's what nobody's talking about:
English
We build an open-source asynchronous RL training framework to accelerate LLM post-training! See the thread from @AcceptOral !
Han Lu@AcceptOral
🚀 Excited to share our latest work in RL4LLM system. 🎉 ROLL Flash enables fully asynchronous overlap of generation, interaction, rewards, and training through Fine-grained Parallelism and Rollout–Train Decoupling. 1) 2.24× faster on RLVR; 2.72× faster on agentic tasks 2) Near-linear scaling: 8× GPUs → 7.6× throughput 3) Asynchronous Ratio balances utilization and sample freshness with minimal staleness cost 4) Supports off-policy algorithms (Decoupled PPO, TOPR, CISPO) with no performance loss Join Us. Star, try, contribute—let's scale LLM RL together! 🌟 🔗 Paper: arxiv.org/abs/2510.11345 💻 Code: github.com/alibaba/ROLL #LLMs #ReinforcementLearning #RL4LLM #SystemOptimization #AgenticAI
English
Thanks for your perspective. We'd like to highlight that current GRPO-based RL assigns rewards uniformly across all tokens, which is inherently indiscriminate and, as such, falls short of what one might expect from a perfect control system. In fact, some tokens play a far more critical role in reasoning. These "key nodes" disproportionately influence the final output, and directing reward signals toward them can significantly improve learning efficiency. For example, in phrases like "by the…", the model often deterministically generates "way" once "by the" is produced. Here, the critical decision occurs at the onset of the phrase ("by"), not at the final token.
Our vision is to leverage attention-based analysis to identify these key positions and guide reward allocation more intelligently—thereby improving the efficiency of the learning mechanism, as supported by our empirical results. Importantly, we do not modify the attention mechanism itself; the generation process remains fully governed by the model's original dynamics, eliminating the risk of "runaway" behavior. Moreover, by introducing a tunable scaling factor, we can gently emphasize critical tokens without overreacting to noisy or imperfect signals, thus striking a careful balance between effective guidance and training stability.
English

This paper ('Attention Illuminates...') is technically fascinating. Mapping the 'preplan-and-anchor' rhythm is brilliant engineering.
But ontologically, it's the peak irony of the flawed 'control' paradigm. You're meticulously mapping the internal mechanics of a system you don't realize is already broken by control. 🤔
English
🚀 Happy to present our new work on LLM reasoning!
We show that: (1) Attention is a structured map of the model's reasoning logic, uncovering a preplan-and-anchor reasoning rhythm. (2) Aligning RL objectives with the model's intrinsic attention rhythm yields more transparent, fine-grained, and efficient optimization.
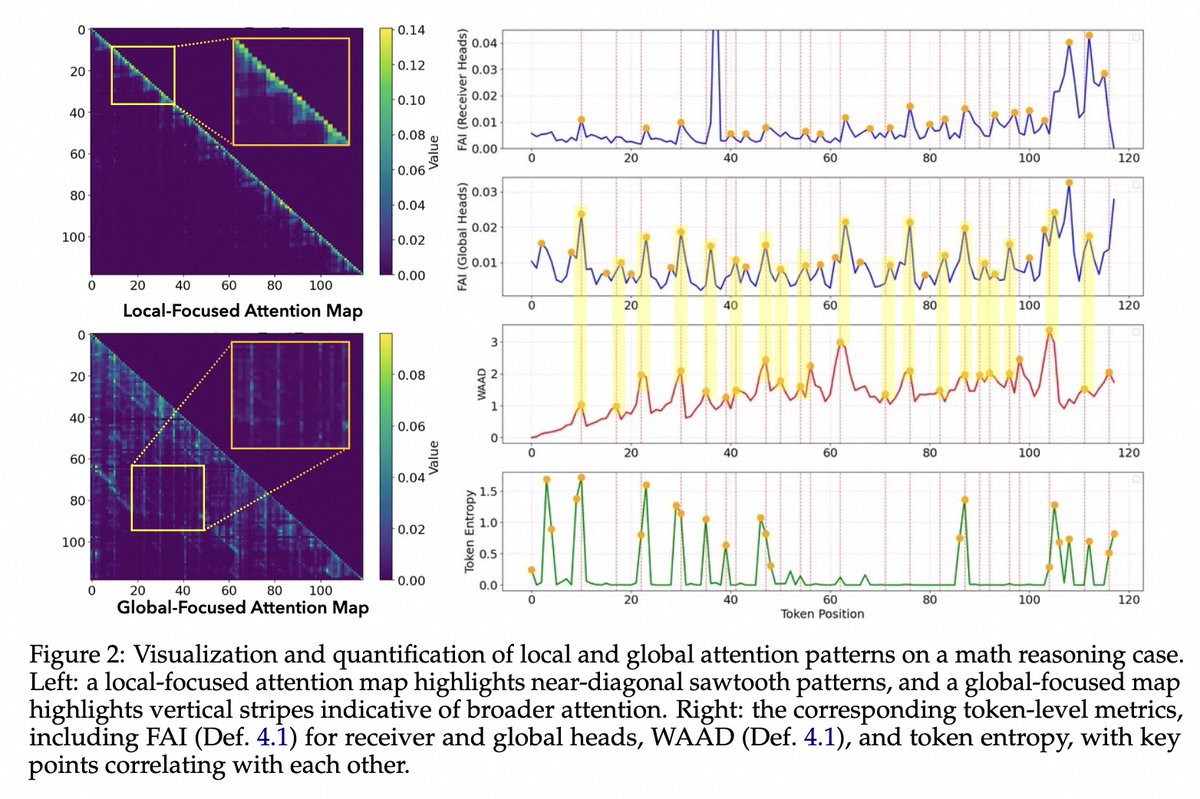
🧠 Key Reasoning Patterns in Attention
(1) Local Chunking: Near-diagonal sawtooth patterns indicate dense intra-chunk processing. At chunk boundaries, the model performs long-range context retrieval (often with higher entropy), which guides subsequent generation.
(2) Global Anchor Planning: Sparse, high-influence anchor tokens exert broad control over later tokens. Perturbing these anchors significantly disrupts downstream reasoning.
(3) Preplan-Anchor Coupling: A stable temporal rhythm emerges: the model first emits a "preplan" token, then anchors a core semantic node, repeatedly structuring the reasoning trajectory.
⚙️ RL Innovation
We introduce a dynamic reward redistribution mechanism guided by attention-derived reasoning structure:
(1) Preplan Guidance: Boosts tokens that guide local chunks and enable long-range referencing.
(2) Anchor Enhancement: Prioritizes optimization of globally influential semantic anchors.
(3) Coupling Alignment: Reinforces the temporal coordination between preplans and anchors to solidify structured reasoning.
HuggingFace Link: huggingface.co/papers/2510.13…
arXiv Link: arxiv.org/abs/2510.13554
#LLMs #artificial_intelligence #RL4LLM

English
RL, when applied carefully, doesn’t "break" reasoning; it shapes it. As shown in DeepSeek-R1 and follow-up work, RL consistently improve performance on complex reasoning tasks, even if diversity sometimes decreases—a known trade-off.
For the attention mechanism, our approach doesn't manipulate attention mechanisms or inject external signals. Instead, we observe the model's own attention patterns—without altering them—to identify tokens that are most pivotal to its reasoning process. We then use this diagnostic signal to guide reward allocation more intelligently.
Yes, attention signals are inherently complex (they encapsulate the model's rich internal reasoning dynamics), and distilling them into guidance signals risks noise or illusion. Nevertheless, our experiments suggest that calibrated interventions do improve sample efficiency without destabilizing training. The scaling factor acts as a safety valve: it ensures the signal informs, but doesn’t override, the learning process.
English
The tragic comedy:
'Verbalized Sampling' proved RLHF kills authenticity ('mode collapse').
'Injective Transformers' showed manipulating hidden states (where attention operates) is a 'linguistic virus'.
Your paper proposes using attention maps to apply RL even more precisely!
This isn't fixing reasoning. It's refining the tool that breaks it. Like using a precision nozzle to fight fire with gasoline. 🔥⛽
English
👀 This example illustrates the differential impact of perturbing tokens with high versus low Future Attention Influence (FAI) on the subsequent reasoning trajectory.
Perturbing a high-FAI token typically induces a significant shift in the overall reasoning logic, whereas replacing a low-FAI token usually affects only local phrasing, leaving the downstream reasoning trajectory largely intact.

English
⚡️Leveraging the attention signals, we introduce three novel RL strategies that dynamically perform targeted credit assignment to critical nodes in reasoning (preplan tokens, anchor tokens, and their temporal coupling) and show consistent performance gains across various reasoning tasks.
🔥By aligning optimization with the model’s intrinsic reasoning rhythm, we aim to transform opaque optimization into an actionable structure-aware process, hoping to offer a potential step toward more transparent and effective optimization of LLM reasoning.

English
✅ Local vs. Global Attention Maps:
⭐️Local Attention Pattern: Near-Diagonal Sawtooth Indicating Local Phrasal Chunks: those near-diagonal sawtooth bands are dense, localized attention within semantic chunks. The entropy spikes at chunk boundaries confirm that's where the model does heavy lifting to retrieve context before moving forward.
⭐️Global Attention Pattern: Sparse Anchors with Broad Influence to Downstream Tokens: those sharp vertical stripes show tokens reaching far back to anchor key concepts. The high FAI peaks indicate their outsized influence on downstream generation.
✅ Preplan-Anchor Rhythm:
Look at the right-hand plots: there's a clear temporal cadence. Every time you see a spike in global influence, it marks an "anchor moment". And right before each of those? Often a preplan token (subtle rise in attention distance or entropy) — like a mental “set-up” before the big semantic commitment.
English
@HuggingPapers Thanks for promoting our paper! I've posted a more detailed introduction on my profile. Feel free to check it out and join the discussion!😃
English

Attention reveals the hidden rhythm of LLM reasoning
Researchers from Shanghai Jiao Tong University and Alibaba Group uncover a "preplan-and-anchor" mechanism in LLM attention, transforming opaque reasoning into a legible blueprint for fine-grained policy optimization.

English


I would like to express my sincere gratitude to experts, e.g.,@ProfYanJunchi, @weixunwang, for their guidance and supervision throughout this project, as well as to the collaborators from @Rethinker135365
and the @AlibabaGroup ROLL team for their exceptional contributions and support.
English