Sabitlenmiş Tweet
LenP
116 posts

LenP
@LenProkopets
Father, husband, dog daddy, management consultant
Old Lyme, CT Katılım Ocak 2015
1.5K Takip Edilen4 Takipçiler

@jkyamog @davideciffa @csujun Cool. I am looking forward to whatever you can do on v100s! I have 3 of them and want to use them to their full potential.
English

@davideciffa @csujun Oh thanks for mentioning me. I haven’t been on Twitter for a long while. Thanks for your project it’s really what I was looking for. When I have time and need I want to try to port on my 32gb cards V100 and 5090. But for now 3090 is very usable.
English

@rumgewieselt Can you please share the actual command you use to run this? I have one machine with 2x 3060ti and another with 2x 1080ti
English

Update from the 2017 Craft Corner ...
-> 3x NVIDIA 1080 Ti (total 33GiB VRAM)
Qwen 3.6 27B Dense (Coding)
27.4 t/s @ 196k
Qwen 35B A3B MoE (Agentic AI)
64.7 t/s @ 229k
---
CUDA 12.4, NCCL 2.22.3



English
@mckaywrigley Amazing! I’d love to try it…. Have you documented this workflow?
English

Multi-agent coding systems are *crazy* good.
Feels like cheating.
2-3x better than single-agent.
Tutorial + prompts + code coming soon.
Watch 2min sneak peak.
English
@bee__computer Received mine today. The app works well with the Apple Watch but the longer battery life of the bracelet will be a huge help.
English


After generating $250K (last 2 months) I built a playbook for @lovable apps—and I’m giving it away.
In just two months, we cracked the code to building apps with AI.
I’ve distilled everything we learned into this single document.
Comment "Build" and drop a follow. I’ll DM it to you.
P.S. This will likely blow up, so give me some time to reply.
English


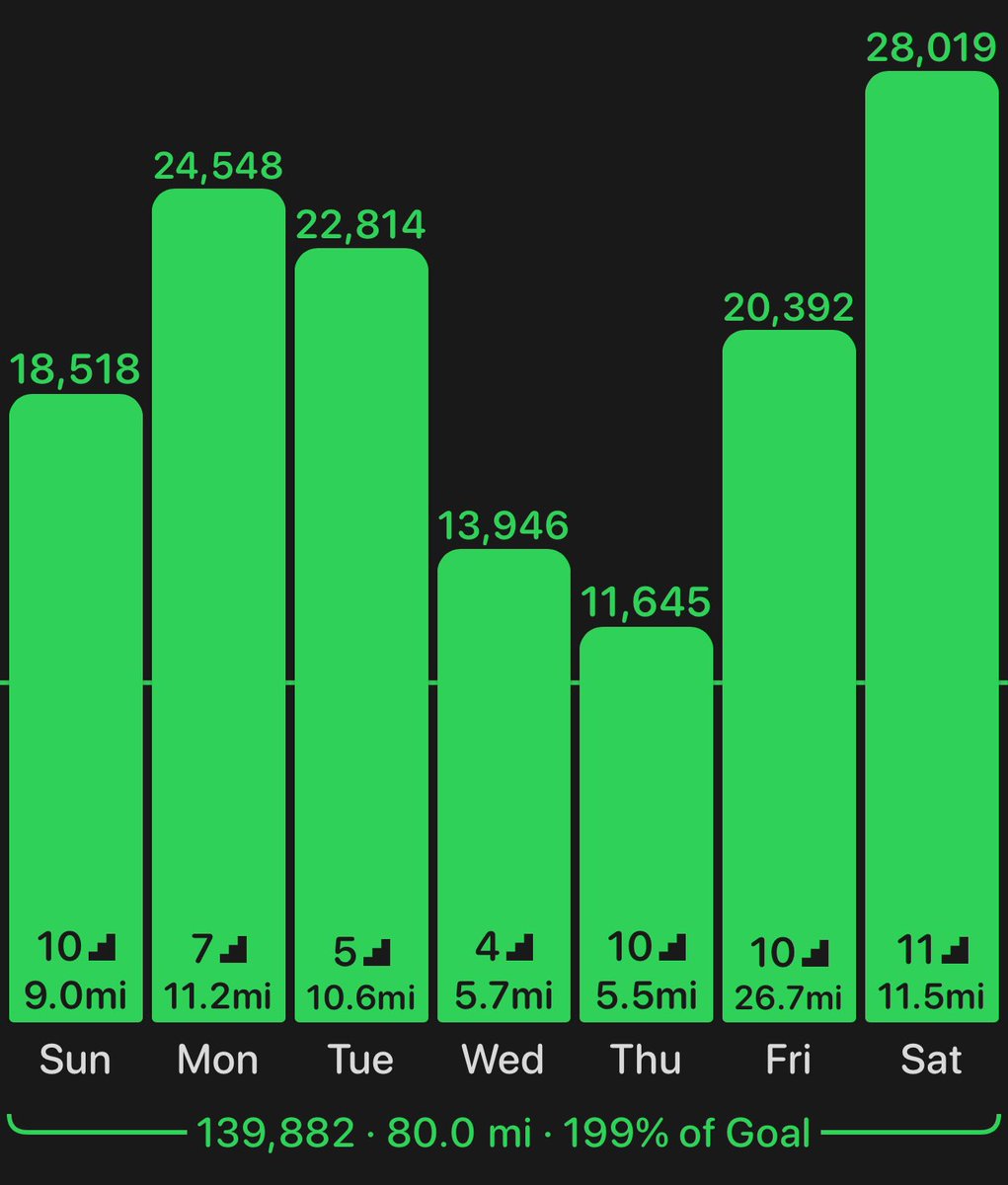
Get a treadmill desk. In the last 7 days I’ve walked 80 miles while at my desk. 90% of the time I’m in a stay of flow and I don’t even realize I’m walking. At the end of the day I feel great. I highly recommend it.
English

Top 30 Anti-Ageing Strategies (save this):
• Aspirin
• Orange juice
• Heavy metal-free cacao
• Cuddles
• Progesterone
• Thyroid hormones
• Oxtail broth
• Literally white table sugar
• Encapsulated peptides
• Thiamine
• CO2 inhaler
• Milk
• Coconut oil
• Niacinamide
• Magnesium
• Literally sunshine
• Oysters
• Red light therapy
• Kisses
• Liver, heart
• Vitamin E
• Methylene blue
• Butter
• Playful moments with loved ones
• Baking soda
• Marmalade
• Lisuride / LSD
• Collagen peptides and gelatine
• Finding purpose
• Ray Peat carrot salad

English

Considering that most Olympic rowers can’t do this, I’m pretty pleased to be hitting this at nearly 58 years of age!
F-yeah!! 250m at sub 1:10 pace is ganster at any age! Glad to be doing it and almost 58! Let’s go!!
English

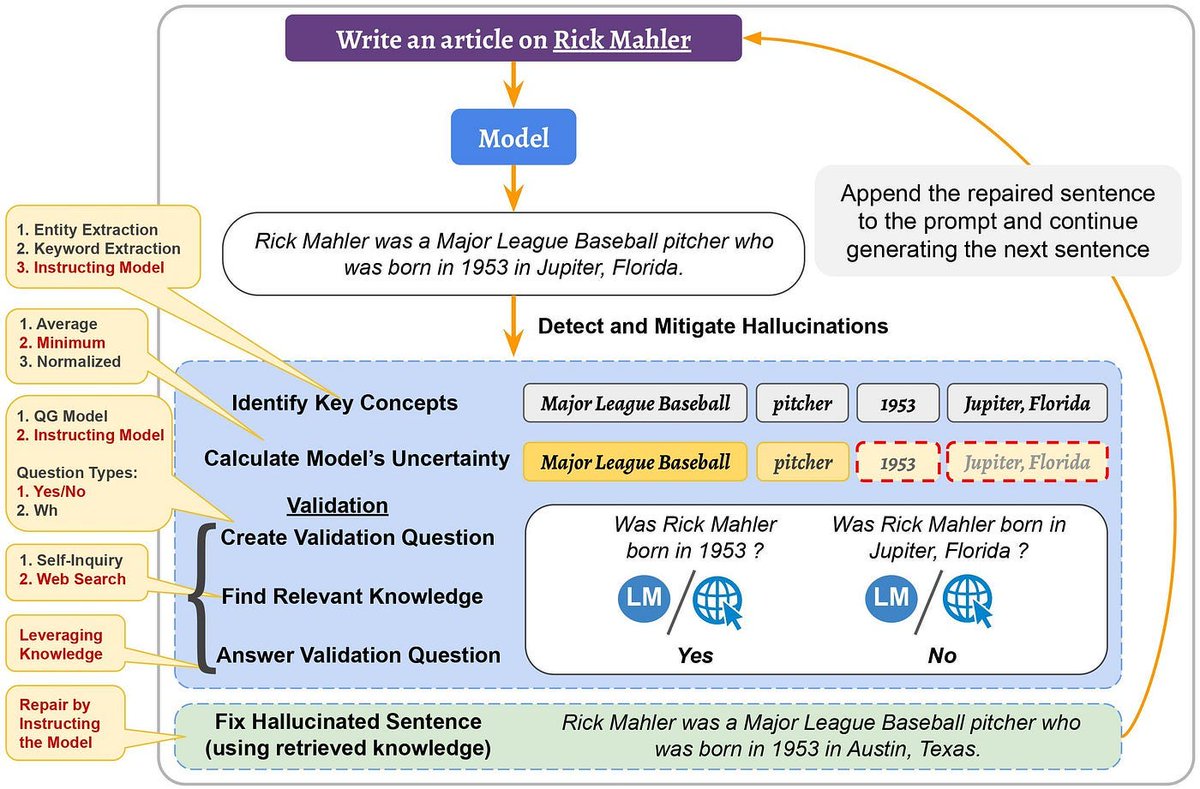
Why Large Language Models Hallucinate and How to Reduce it
If you are a power user of ChatGPT you have probably been bitten by the hallucination bug. The LLM lulls you into getting comfortable with it and then springs a convincing but totally made-up story, playing you for a fool.
These hallucinations, like dreams, are LLMs fabricating narratives. So why do these LLMs hallucinate and how do you prevent it.
Here are a few reasons
Data Sparsity: This is the #1 reason for hallucination. GPT-4 for example doesn't have access to recent data as it was trained in 2021. Ask it a question, that pertains to a recent topic, and it is likely to hallucinate as it doesn't have the data for the right answer. The model is generalizing from what it has learnt but that may very well be inaccurate
Not supervised learning: LLMs don't have a "ground truth" or a set of correct examples. While the RLHF process tries to steer the LLM towards more correct answers. The base training isn't a supervised learning process and this makes things challenging as the model can't tell what is "correct" and what's not
Short-term context: The model architecture has a fixed-length context window, meaning it can only "see" a certain number of tokens at a time. If important context falls outside this window, the model may lose track of it, leading to errors.
No real-time feedback loop: Like humans LLMs don't have a real-time feedback look and don't instantly learn from mistakes. The good news is we can refine or fine-tune models with human feedback and make them hallucinate less.
So how do you prevent these hallucinations and are future LLMs less likely to hallucinate?
While there is no easy way to guarantee the LLMs will never hallucinate. The following techniques mitigate it to some extent
Prompt Design: Simple prompt engineering and design will reduce hallucination. For example, adding the following to your prompt help: "Provide a factual answer based on scientific evidence."
Fine-tune for a specific domain: The model can be fine-tuned on a narrower dataset that is highly reliable and relevant to the domain where hallucinations need to be minimized.
Contradiction checks: LLMs can be prompted to self-contradict themselves and then they are further prompted to recognize the contradiction and mitigate it. This falls into the category of advanced prompt engineering
Retrieval Augmented Generation: This is a common technique used in Enterprise LLMs. At Abacus, we use this routinely. You are basically looking up the relevant documents that contain the answer in a search index first and then feeding the search results to an LLM to formulate the final answer. Since the LLM is forced to find the answer in the information it was sent, it hallucinates much less.
Human In the Loop: A human expert can always check the answer before it gets used. This is a labor intensive option which isn't ideal
While the above techniques work on trained LLMs, the following two techniques can be applied during LLM training
Data Re-weighting: Assign higher weights to reliable and verified data during LLM training, effectively making the model pay more attention to them
Longer Context Windows: Extending the model's memory can help it maintain context over longer passages, reducing the chance of hallucinations.
So while there are several easy ways to mitigate and almost completely remove hallucinations if you are working in the Enterprise context, it's much harder in the AGI context. This is a very hot topic in AI research and several researchers are still working on it.
English
@hubermanlab @hubermanlab do you think TENS stimulation would elicit the same response? Perhaps direct stimulation of the soleus or stimulation of the peroneal nerve? pubmed.ncbi.nlm.nih.gov/30200088/ Maybe a dedicated peroneal nerve stimulation device like @RecoveryFirefly would be useful?
English

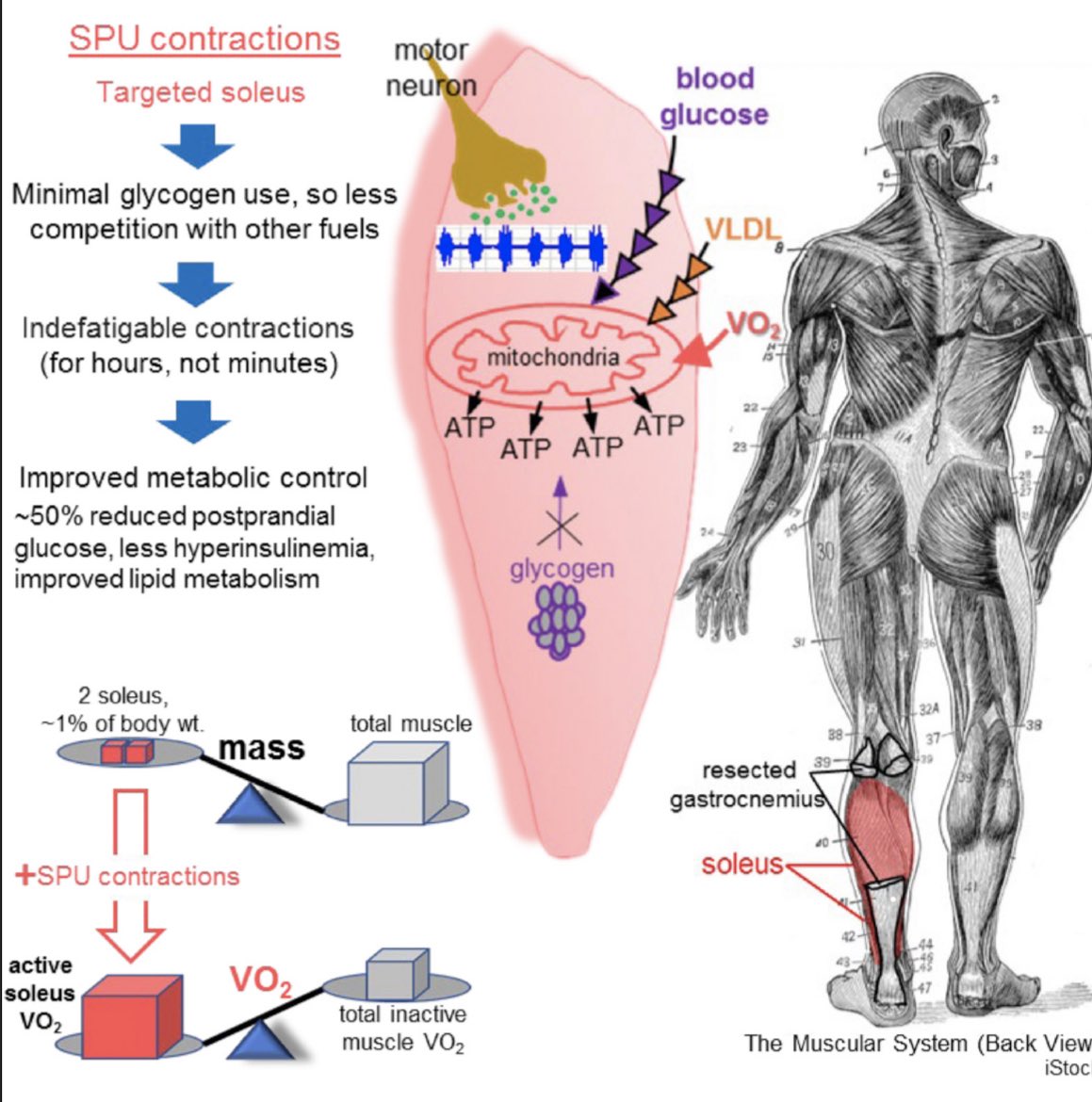
Soleus Pushups (a name the authors gave to non-weighted seated calf raises); “A potent physiological method to magnify & sustain soleus oxidative metabolism improves glucose & lipid regulation” = some pretty remarkable & outsized positive effects on glucose & lipid utilization.
English
@PeterDiamandis The basis for answers is not clear (e.g., what was it trained on, what “fact base” is it referencing, what feedback and constraints applied, etc). It’s a black box
English

do you have any concerns about generative AI? what are they?
English

Gonna beef up the tutorials for how to create your own Chat-GPT over specific documents with @langchain
What types of documents/knowledge bases would people want to have examples for? Eg Notion, Obsidian, webpages, etc
English

mackinstitute.wharton.upenn.edu/wp-content/upl…
That’s not surprising. Human work will need to quickly adjust to focus on prompt engineering and getting the best out of OpenAI, not competing with it.
#OpenAI #OpenAIChatGPT #GenerativeAI #chatGPT
English

I have signed in to WSJ.com approximately 14,000 times on every computer, phone, and tablet I’ve owned since 1994. And yet.
English
LenP retweetledi

Today is the last day to vote #WPMOYChallenge + @MikeEvans13_!
1 RT = 1 Vote
#WPMOYChallenge + Evans
#WPMOYChallenge + Evans
#WPMOYChallenge + Evans

English