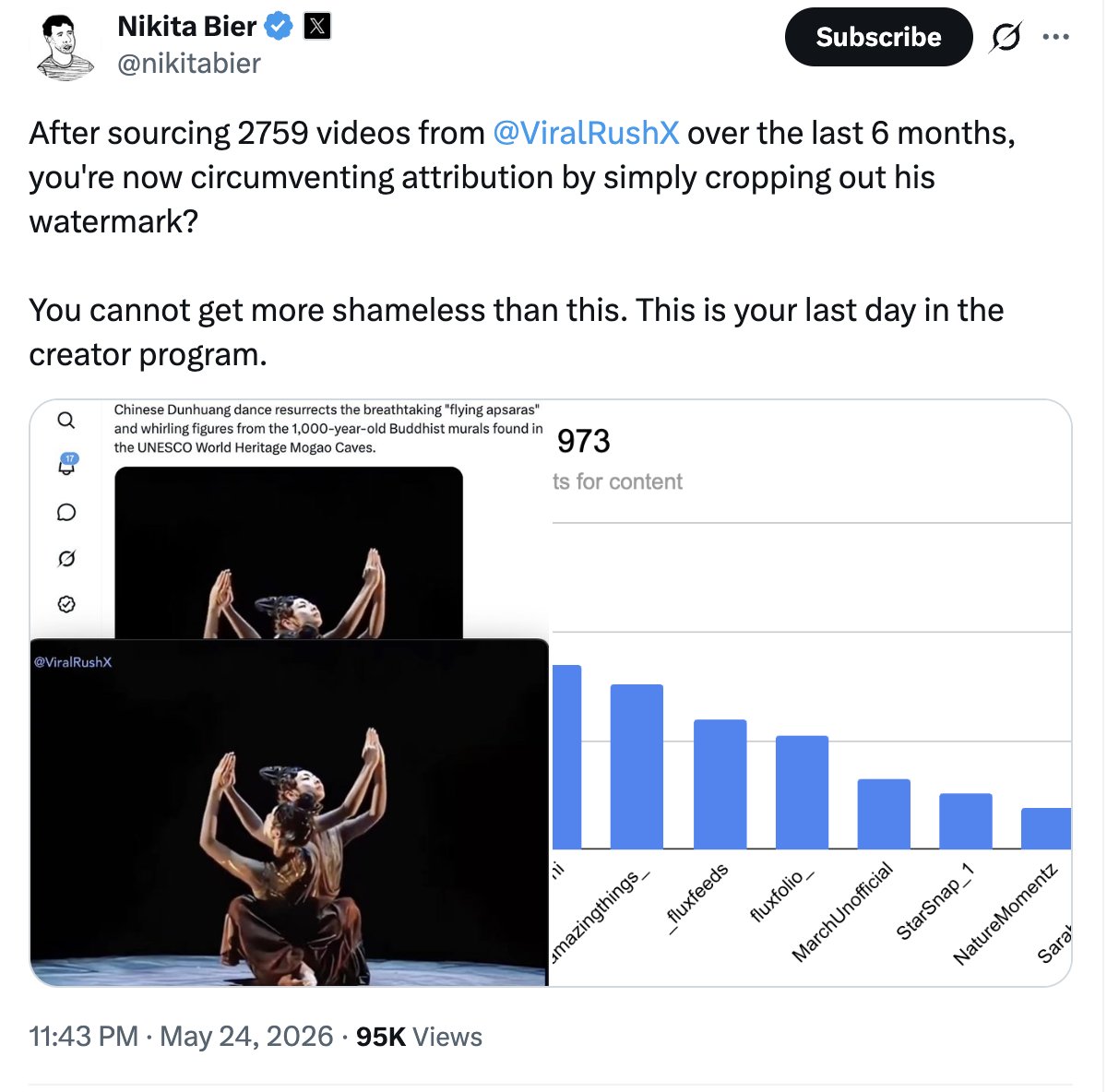
So Nikita called me and many others out for posting greetings.
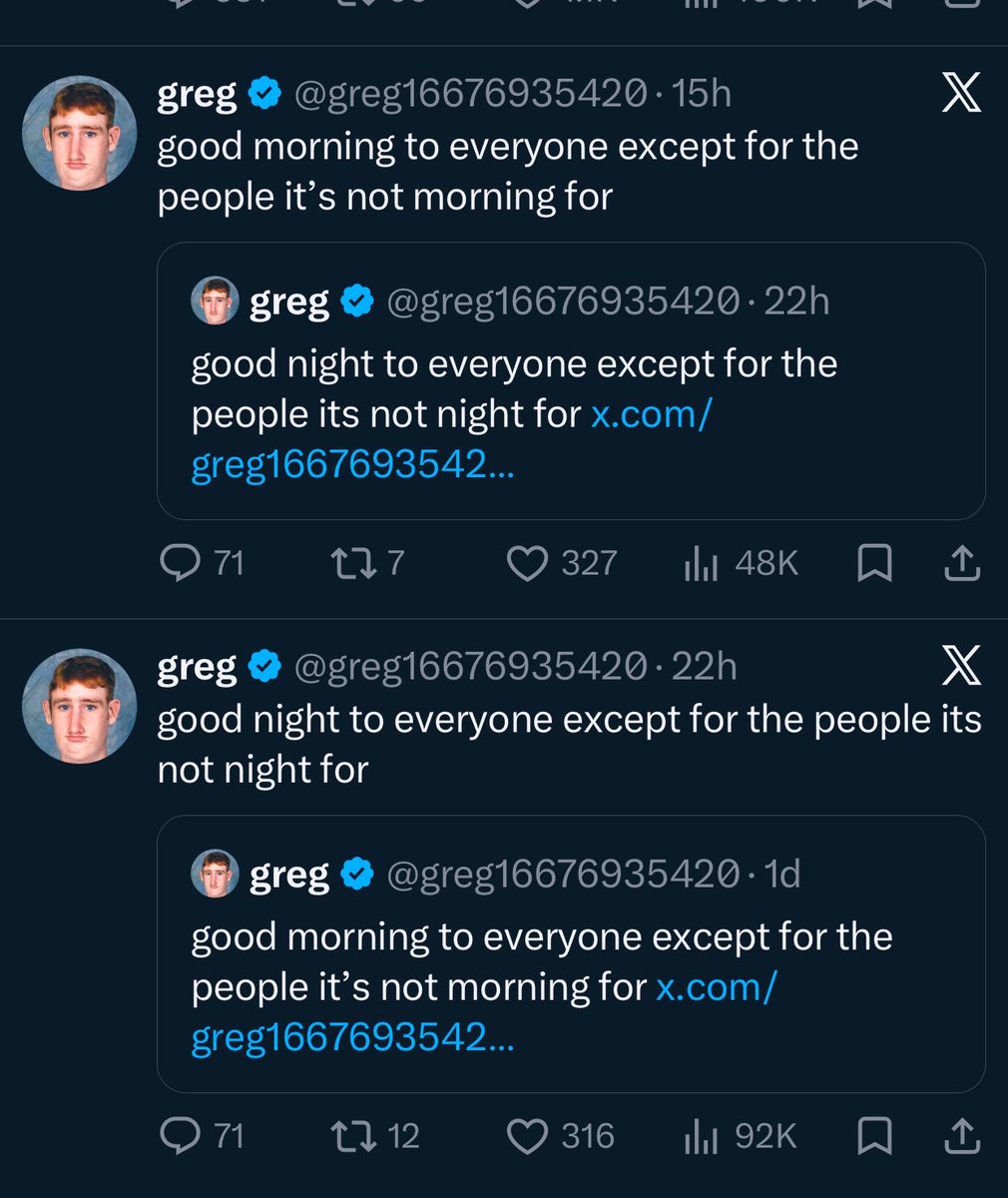
Meanwhile, Gregg, an account with 1.2M followers, posts “Good morning” and “Good night” almost every single day,
but somehow Nikita doesn’t utter a word about that.
Why?
Well, the data is out. According to @nikitabier's chart, I'm the 2nd highest source of content reshared by @Rainmaker1973, with around 1,700 of my posts. For years people accused me of being his shadow account because of how often this happened. His reposts pulled millions of views while the originals on my page got almost nothing. Grateful to @ViralRushX speaking up, and to @nikitabier and the X team for finally putting attribution on the table. Looking forward to the changes that reward original creators. 🙏
A Recorder journalist wanted to know what Russian citizens think about Vladimir Putin's war. Kamil, a 46-year-old Russian artist, sent our Romania-based newsroom his answer. #Ukraine
Hello again, everyone!
We've got another really fun 9b, this one specifically trained for tool calling and agentic coding workflows in @NousResearch Hermes agent.
Happy to report that it crushes, and as a 9b it runs on super affordable hardware. We also hit this one with some coding domain-specific training, and it scored a 53.33% on SWE bench on a slice of 200 samples!
To me, I was really shocked to see this high of a score on a 9B model in swe, correct me if I'm wrong, but I think that's nipping at the heels of the Gemma 4 series, much larger models on this particular benchmark, which is really incredible to see!
It also crushes the HermesAgent-20 benchmark, scoring an 85 vs the base model's 71!
Make sure to run it hot, --temp around 1, that seems to be the sweet spot for running these particular fine tunes in harnesses. If you have trouble, you can work your way down, but it does a much better job departing from base models, overthinking when you run it, high temp ~1.
Please spin it up in Hermes and let us know your thoughts! Looking forward to hearing your feedback as always!
Also, those of you waiting for Qwopus 3.6 27B, I have put together a preliminary evaluation for you in my HF repo, go check it out; we will be releasing the full model very soon! I will put the preliminary repo in the comments!
huggingface.co/Jackrong/Qwopu…
In Poland, the streets are white. Everyone looks the same, everyone speaks the same language.
Poland is currently condemning itself to being a passive witness to the great civilizational processes that are coming.
By not entering this current, we are even more deaf, even more mute, and we see very little. This is terrifying,
Polish Nobel Prize winner Olga Tokarczuk for Deutsche Welle.
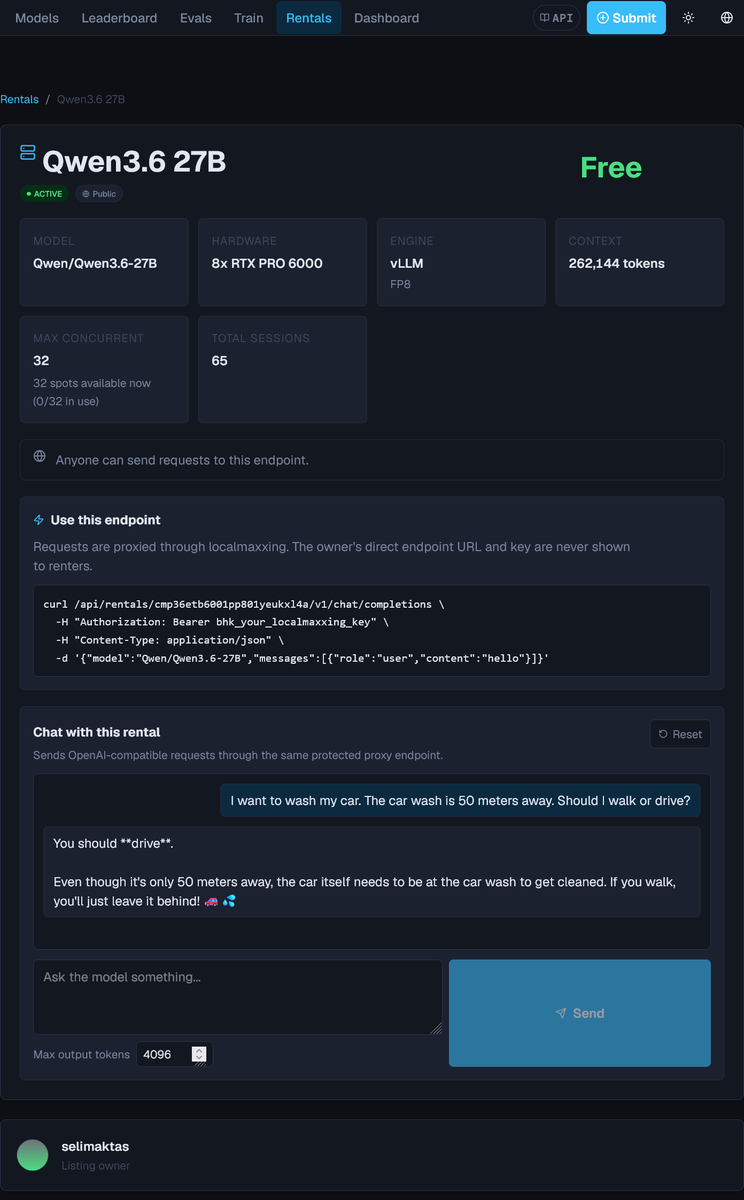
The first localmaxxing free rental and it’s qwen 27b on 8x6000 pro 😂
By @selim_aktas2
This is the first implementation of Rentals
Community provided endpoints, do whatever you want with them. Localmaxxing is just middlemanning
localmaxxing.com/en/rentals/cmp…
L3Harris Technologies @L3HarrisTech gave soldiers a way to detect and jam drones using the radio they already carry.
No new hardware — just a software update that turns 100,000-plus fielded radios into counter-drone sensors.
Read more: defence-blog.com/l3harris-turns…
buy a gpu. 3090, 4090, dgx spark, whatever fits your budget. tier doesn't matter. running your first local model does. the moment your first prompt lands with no api between you and the model, your brain rewires. that single moment is worth more than every take you'll ever read on a timeline.
Future spacecraft may be able to “think” for themselves.
NASA is testing a next-gen space processor that can withstand the harsh conditions of space, while improving computing power. So far, testing shows it operating at 500 times the performance of chips currently in use. go.nasa.gov/4wm7QHL
Musk's lawyer: "Are you completely trustworthy?"
Altman: "I believe so."
Musk's lawyer: "But, you know, you don't know whether you're completely trustworthy."
Altman: "I'll just amend my answer to yes."
Musk's lawyer: "Should the jury believe your testimony?"
Altman: "I think that's up to them, but I believe so."
Musk's lawyer: "You believe so, or they should?"
Altman: "Sir, I'm not gonna tell the jury what to think."
Musk's lawyer: "Do you always tell the truth?"
Altman: "I believe I'm a truthful person."
Musk's lawyer: "It wasn't my question. Do you always tell the truth?"
Altman: "I'm sure there is some time in my life when I have not."
Musk's lawyer: "Have you told lies to advance your business interests?"
Altman: "Uh, no."
Musk's lawyer: "Have you misled people with whom you do business?"
Altman: "I believe I am an honest and trustworthy business person."
Musk's lawyer: "That wasn't my question, what you believe. Have you misled people with whom you do business?"
Altman: "I do not think so."
Musk's lawyer: "Would they think so?"
Altman: "I can't answer that for other people."
That was the opening of Sam Altman's cross-examination this morning.
These are the CCTV and XINHUA websites at the moment. What's interesting about it? There is not a single mention of the upcoming Trump visit to Beijing
Those who are familiar with China know very well what this means. Those who aren't will learn soon.
Thanks. Done without compromises on model output quality (like lower quants or context compression) and decent 60k context. I tried all possible optimizations: turboquant, MTP, lk.llama.cpp and whatnot, nothing really made an impact on low end hardware, no one is posting eval results at the end of a long context/output (you only get a brief speedup for a few sec)
@MajorFAFO It's refreshing to see someone sharing benchmarks outside of the minimum recommended hardware that everyone is using and constantly talking about, particularly when people manage to squeeze enough performance to get decent results on lower-end hardware.