Sabitlenmiş Tweet
QwQ-32B.com
68 posts


QwQ-32B.com
@MegaVault_
https://t.co/p3vLokoWwk: Buy this domain & empower your company to reach million people and change their life. DM to purchase or buy securely via Dynadot registrar today
Interested ? | Buy Now 👉👉👉 Katılım Mayıs 2024
17 Takip Edilen10 Takipçiler
@bullishnames I believe the sales is real, but every seller can't control how buyer use the domains.
Probably @ishmilly able to share any story behind the sale.
I check the hyphen version ai-devs.xyz still listed for sale too on GoDaddy
Your domain is good too.
Good luck
English

AiDevs.xyz is said to have been sold for $30.000
meanwhile
Aidevs.co listed for $660
Aidevs.org listed for $545
Aidevs .xyz currently has no source codes related to AI, it is just a simple site. Do you believe this sale is real ?
#Domain
English
@abmakrani @Aladey Agree, most company forget to place strong foundation on the right domain, they spend thoudan - million dollar every month to pay their CEO , director,staff, etc.
But they spend a little $$$ to expand their domination until they should face new stronger competitor.
English

@Aladey If the buyer will have no understanding of the value of domains, even if you'll offer for $2,000, that would be expensive for them to buy.
I don't think the reported sales hurt our industry.
But IMO all automated appraisal tools are worthless and misguiding.
English


Breaking news, Xiamen Dense Technology Co., Ltd., a listed company, announced that it plans to sell its self-owned domain name DNS.com for 14,486,500 yuan (about 2 million US dollars) to Hong Kong Juwang Technology Co., Ltd.!
Congratulations to both parties! The domain name market will rise sharply in 2025!
DN.com wishes everyone a good harvest this year! The picture below is the announcement of the listed company!

English

Stay Ahead with AI Agents, Agentic & Agentive
"Businesses, startups, & individuals need to show they are experts in the full spectrum of AI tech. By investing in #domain names that represent AI Agents, Agentic AI, and Agentive AI" Click link to continue
linkedin.com/pulse/stay-ahe…
English
Another great experience with @lumis_com abdulbasit.com/domaining/anot…
English
The budget is 300K USD to help DN.com's customers acquire a payment domain name. The domain name does not necessarily need to contain the Pay keyword.
The budget is 500K USD to help customers acquire a car-related domain name.
If you have a beautiful payment domain name or a car domain name, please send an email to vivi@DN.com.
Remember, we only accept emails. We don't have time to reply to other methods. Please understand.
Best wishes!

English


Exciting news! Today, we release QwQ-32B, our new reasoning model with only 32 billion parameters, delivering performance comparable to other larger cutting edge models.
Explore it and share your thoughts with us! Let’s drive innovation together! 🚀
#OpenSource #Qwen
Qwen@Alibaba_Qwen
Today, we release QwQ-32B, our new reasoning model with only 32 billion parameters that rivals cutting-edge reasoning model, e.g., DeepSeek-R1. Blog: qwenlm.github.io/blog/qwq-32b HF: huggingface.co/Qwen/QwQ-32B ModelScope: modelscope.cn/models/Qwen/Qw… Demo: huggingface.co/spaces/Qwen/Qw… Qwen Chat: chat.qwen.ai This time, we investigate recipes for scaling RL and have achieved some impressive results based on our Qwen2.5-32B. We find that RL training con continuously improve the performance especially in math and coding, and we observe that the continous scaling of RL can help a medium-size model achieve competitieve performance against gigantic MoE model. Feel free to chat with our new models and provide us feedback!
English

🚀 Recently, I've been focusing on RL for LLM, and I'm excited to introduce QwQ-32B—the best open-source reasoning model under 100B scale. RL indeed holds some fascinating yet unexplored mysteries. You're all welcome to continue building more interesting things based on Qwen!

Qwen@Alibaba_Qwen
Today, we release QwQ-32B, our new reasoning model with only 32 billion parameters that rivals cutting-edge reasoning model, e.g., DeepSeek-R1. Blog: qwenlm.github.io/blog/qwq-32b HF: huggingface.co/Qwen/QwQ-32B ModelScope: modelscope.cn/models/Qwen/Qw… Demo: huggingface.co/spaces/Qwen/Qw… Qwen Chat: chat.qwen.ai This time, we investigate recipes for scaling RL and have achieved some impressive results based on our Qwen2.5-32B. We find that RL training con continuously improve the performance especially in math and coding, and we observe that the continous scaling of RL can help a medium-size model achieve competitieve performance against gigantic MoE model. Feel free to chat with our new models and provide us feedback!
English


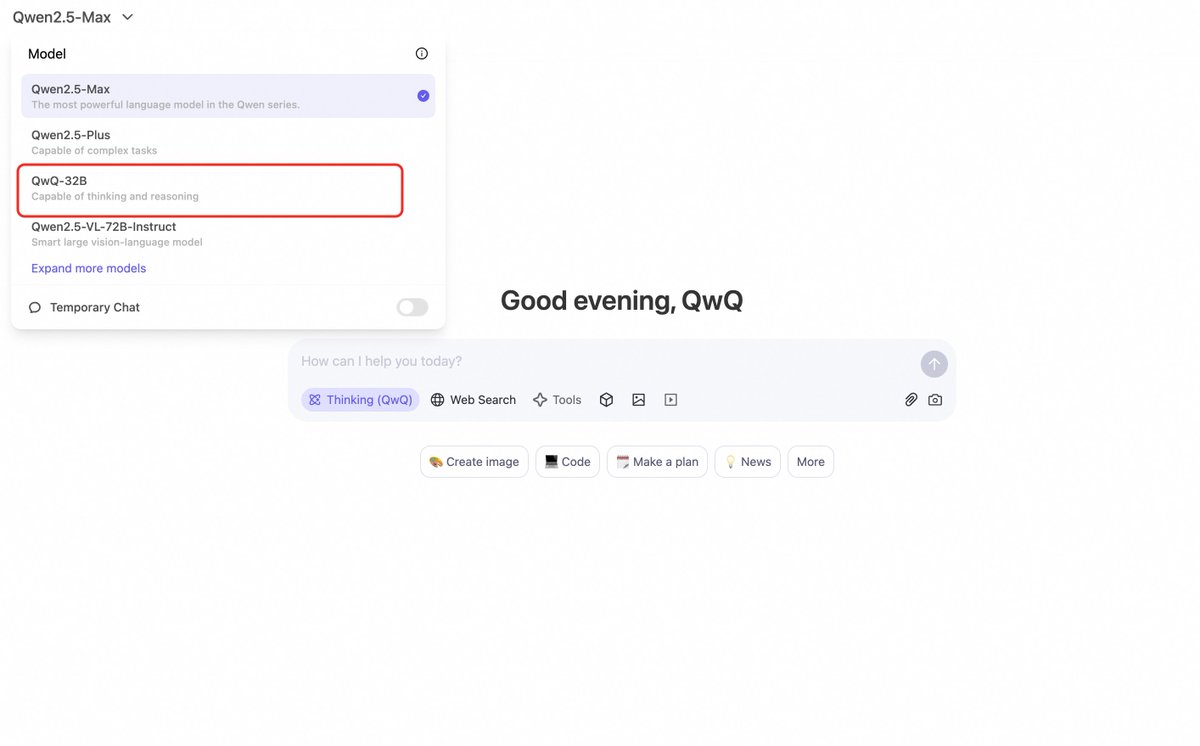
🥝 Yesterday we opensourced QwQ-32B, and we put the model on Qwen2.5-Plus + Thinking in Qwen Chat. Based on your feedback, we make a change and put QwQ-32B on the model list of Qwen Chat, and thus you can directly access it by choosing this model. Enjoy and feel free to give us more feedback about the model as well as the product! 💗
Qwen@Alibaba_Qwen
Today, we release QwQ-32B, our new reasoning model with only 32 billion parameters that rivals cutting-edge reasoning model, e.g., DeepSeek-R1. Blog: qwenlm.github.io/blog/qwq-32b HF: huggingface.co/Qwen/QwQ-32B ModelScope: modelscope.cn/models/Qwen/Qw… Demo: huggingface.co/spaces/Qwen/Qw… Qwen Chat: chat.qwen.ai This time, we investigate recipes for scaling RL and have achieved some impressive results based on our Qwen2.5-32B. We find that RL training con continuously improve the performance especially in math and coding, and we observe that the continous scaling of RL can help a medium-size model achieve competitieve performance against gigantic MoE model. Feel free to chat with our new models and provide us feedback!
English
Today, we release QwQ-32B, our new reasoning model with only 32 billion parameters that rivals cutting-edge reasoning model, e.g., DeepSeek-R1.
Blog: qwenlm.github.io/blog/qwq-32b
HF: huggingface.co/Qwen/QwQ-32B
ModelScope: modelscope.cn/models/Qwen/Qw…
Demo: huggingface.co/spaces/Qwen/Qw…
Qwen Chat: chat.qwen.ai
This time, we investigate recipes for scaling RL and have achieved some impressive results based on our Qwen2.5-32B. We find that RL training con continuously improve the performance especially in math and coding, and we observe that the continous scaling of RL can help a medium-size model achieve competitieve performance against gigantic MoE model. Feel free to chat with our new models and provide us feedback!

English
QwQ-32B.com retweetledi

@ICADomains @unstoppableweb Dynadot Team
Kyriakos (Kay): Broker
Hallie: VP of Aftermarket
Todd: President
Caleb: Head of Account Management

English
QwQ-32B.com retweetledi

QwQ-32B.com retweetledi
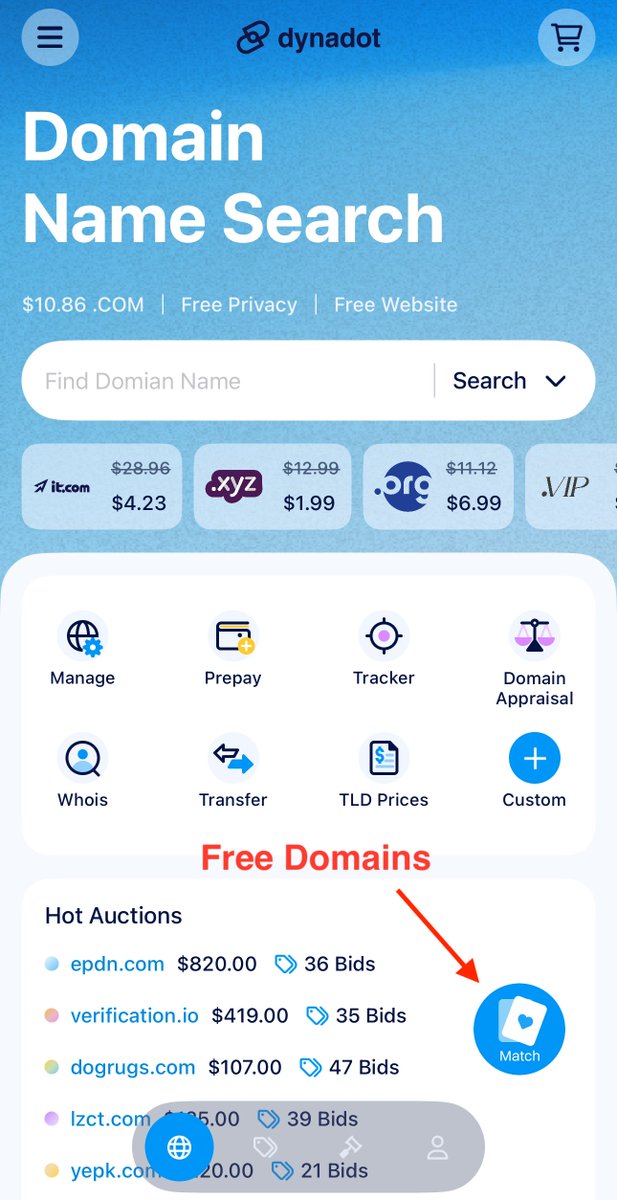
A new version of our app just dropped! The UI and navigation should be much more intuitive now. Also check out the Domain Match game. It is a swiping game, kind of like a dating app. You can win free domains that are similar to domains already in your account.
Just search for "Dynadot" in your app store.
English
QwQ-32B.com retweetledi

Dynadot has been named Best Registrar for International Business TWICE by USA Today! 🌍 We’re always expanding, and now you can too with our newest ccTLDs: .AD (Andorra), .MW (Malawi), and .ML (Mali).
Register and grow globally today: dyna.me/41wZWxT

English