
@GavinSBaker I knew it, they told me four years life on chips my brain say no. I think minimum 6 to 8 years if not longer.
Thank you, Gavin you make my day.
You are such a tremendous person 👏
English
S
2.1K posts


This is my sixth conversation with @GavinSBaker. As always with Gavin, the conversation covers a lot of ground, but we spend the most time on watts and wafers. We discuss: - Why the wafer shortage may prevent an AI bubble - Data centers in space (reframed) - Elon's Terafab and the new chip companies challenging Nvidia - Usage-based pricing - The disaggregation of GPUs - DRAM, frontier tokens, and open source Enjoy! Timestamps: 0:00 Intro 7:55 Anthropic and OpenAI Valuations 12:58 Watts, Wafers, and Infrastructure 14:39 Orbital Compute and Data Centers in Space 22:49 Avoiding the AI Bubble 28:26 Terafab and the Future of US Manufacturing 32:16 Returns to the Frontier 37:23 Continual Learning 42:03 New Chip Companies 48:52 Extending GPU Lifespans and Private Credit 51:22 The Application Layer 57:32 The Token Path and Open-Source Dynamics 1:01:37 Cybersecurity 1:05:46 Diversity Breakdown 1:11:59 Assessing the Big Tech Players in AI 1:19:02 Geopolitics, Personal Safety, and the AI Horizon


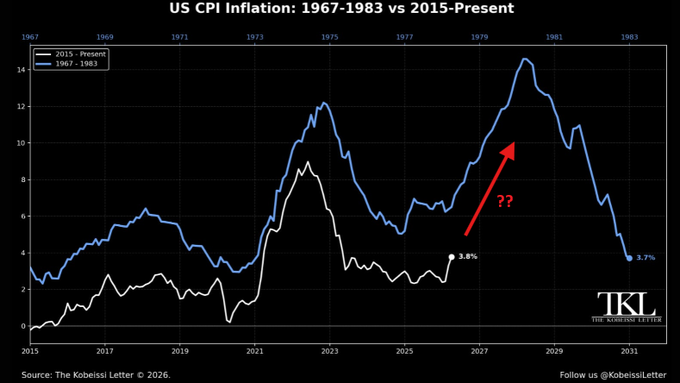
Bond markets are flashing red. Today, the US 30Y Note Yield officially hit its highest level since July 2007, at 5.19%. This will soon become Americans’ biggest problem, yet the vast majority do not even know it is happening. What is happening? Let us explain. (a thread)


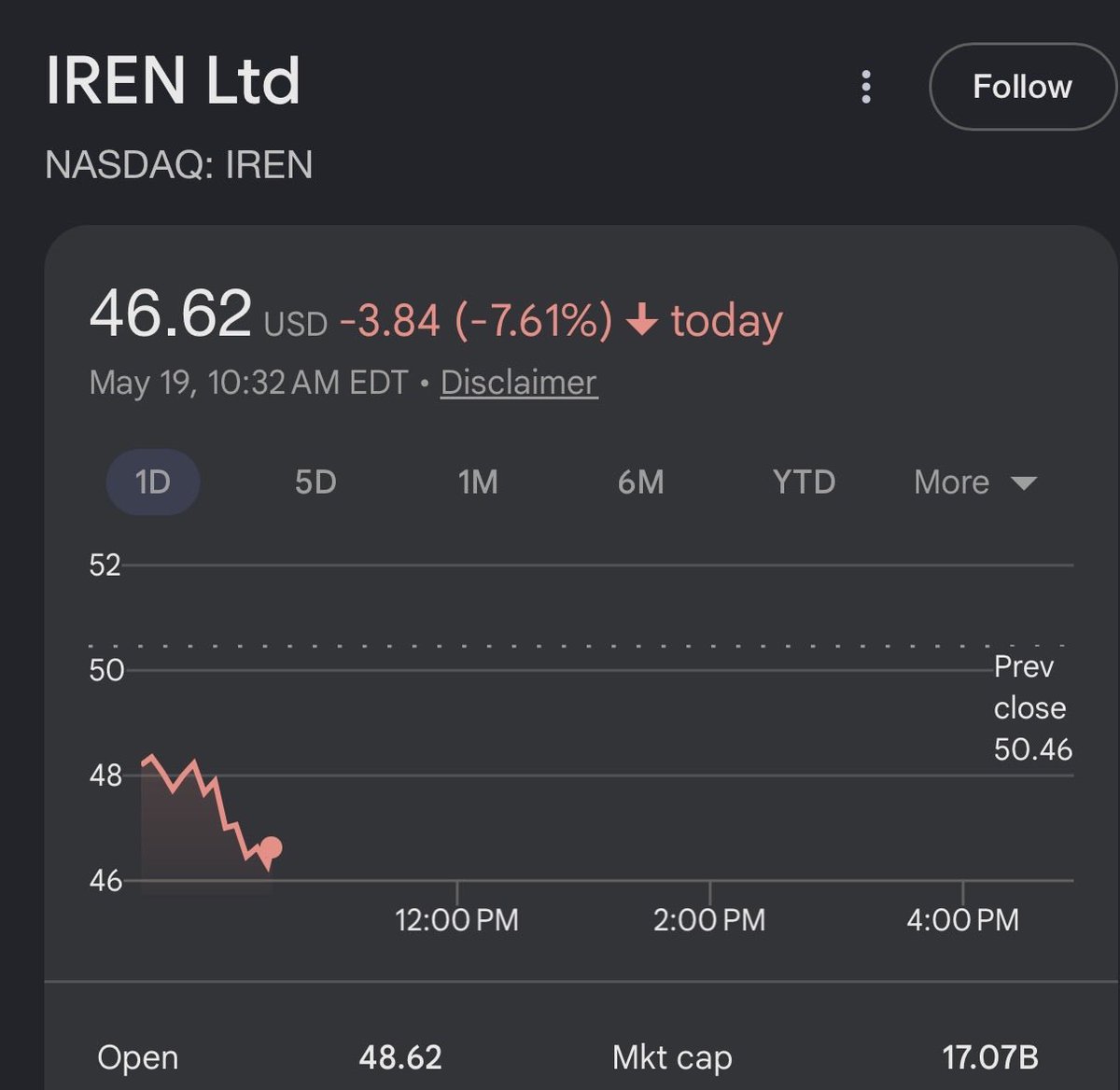

I still am bearish on $IREN. Algorithms/retail probably read $NVDA + $IREN partnership and bought it up. However, if you look at the realtity, it's just looks like brand agreement giving $NVDA risk-free convertible notes. So $IREN can continue selling their $6,000,000,000 ATM into retail investors. It's the equivalent of a startup using AWS and saying they have an Amazon partnership so give them $6B. This wasn't Nvidia directly funding $IREN yet, just a risk free option to. There's a "5 GW deployment" but I'd rather not be the one buying into the dilution to fund it.

Chamath: Taiwan Loses Its Strategic Importance in 18 Months @chamath: “ We're 18 months from Taiwan not being an important moment of conversation the way it is today. Why 18 months? Because we are at a point where we're probably 1-2 nanometers away from being able to do what we need Taiwan to strategically do for us. And so as we scale up our chip fabs, as we get more capacity, and interestingly, there are these orthogonal technologies being developed. I don't know if you guys saw, but Neuralink was showcasing a machine that is literally operating at the almost nanometer scale to do the brain operations for the implantation, all automatically. When you have the dexterity and the capability mechanically to make these things, the real reason then is a very different one than what it is today. Today, it's economic. And if you take that off the table, I think we'll have a very different attitude to Taiwan.”




$EOSE and Cerberus are launching Frontier Power USA to deploy American-made long-duration energy storage projects using Eos’ Z3 zinc batteries. Cerberus is committing $100M of equity, with a 2 GWh capacity reservation and projects targeting 4-16+ hour grid storage.


Back-of-envelope numbers for 1 gigawatt data center: All-in Capex: ~$50 bn Enterprise revenue generated: ~$25-30 bn/year Electricity cost: $1-2 bn/year ~2 year payback. The boom is real.




