Sabitlenmiş Tweet
Aanchal
1.4K posts


Aanchal
@Origichals
Human | Learner | PhD researcher in PTMs involved in DNA repair using AlphaFold and structural biology approach @MSuskiewicz lab @CNRS.
Terra Katılım Şubat 2019
129 Takip Edilen75 Takipçiler
Aanchal retweetledi

Phoolon ki Holi celebration in Vrindavan Mathura , Uttar Pradesh 🌼🌹 🪷 🇮🇳


हिन्दी
Evolution’s cheat code in action:nature.com/articles/s4158…
Niko McCarty.@NikoMcCarty
This paper is wild. After 3 rounds of directed evolution, they converted a DNA polymerase into an enzyme that can do: - RNA synthesis - Reverse transcription - Synthesis of "unnatural" nucleotides - Synthesis of DNA-RNA chimeras One of the best papers I’ve read recently. For context: In nature, it is DNA polymerase that takes a DNA sequence as a template and then copies it. These enzymes are crucial in replicating the genome for cell division, and they are EXTREMELY specific for DNA over RNA. This is key because RNA nucleotides are present in the cell at concentrations ~100x higher than DNA nucleotides, so the enzyme has evolved clever strategies to select one over the other. RNA polymerases, for comparison, are the enzymes that take a DNA sequence as template and then convert it into RNA. They are involved in gene expression, for example. To convert a DNA polymerase into an RNA polymerase (and all the other functions I mentioned earlier), the authors did a fairly straightforward directed evolution experiment. First, they took four DNA polymerase enzymes belonging to various archaea. These DNA polymerases don’t check for DNA vs. RNA as stringently as other types of cells, so they’re a good starting point to evolve RNA polymerases. The authors inserted some targeted mutations into these enzymes, based on known mutations in the literature. For example, they swapped the amino acid at position 409 for a smaller amino acid, thus removing a “gate” that keeps RNA building blocks from entering the enzyme. Next, they took the four genes encoding these DNA polymerases and cut them up into 12 segments each. They randomly stitched these 12 segments together — from the four different genes — to build millions of unique variants. Each shuffled gene was inserted into an E. coli cell. Then, they grew up these cells (each carrying a unique polymerase) and put them into microfluidic droplets. A device isolates each droplet, lyses the cell open, and releases the polymerase. The droplet also contains RNA building blocks and a DNA template, encoding a fluorescent reporter. If the polymerase begins synthesizing RNA, it will produce a detectable signal. They screened about 100 million droplets in 10 hours of work, searching for those with a signal. For each well that yields a fluorescent signal, the researchers isolated the DNA and sequenced it to figure out which polymerase it was. They repeated this 3x times, finally isolating a really excellent RNA polymerase variant which they called "C28." C28 has 39 mutations compared to the wildtype enzymes. It incorporates about 3.3 nucleotides of RNA per second, with 99.8% fidelity. The crazy thing is that this enzyme can also copy DNA or RNA templates back into DNA (reverse transcription), or use chimeric DNA-RNA molecules as a template and amplify them. It is just a super versatile polymerase that can act on DNA, RNA, or modified nucleotides, to build just about anything.
English
Evolution’s cheat code in action: by shuffling parts through homologous recombination, an RNA polymerase rapidly “Frankensteins” itself into a far more efficient enzyme
nature.com/articles/s4158…
Niko McCarty.@NikoMcCarty
This paper is wild. After 3 rounds of directed evolution, they converted a DNA polymerase into an enzyme that can do: - RNA synthesis - Reverse transcription - Synthesis of "unnatural" nucleotides - Synthesis of DNA-RNA chimeras One of the best papers I’ve read recently. For context: In nature, it is DNA polymerase that takes a DNA sequence as a template and then copies it. These enzymes are crucial in replicating the genome for cell division, and they are EXTREMELY specific for DNA over RNA. This is key because RNA nucleotides are present in the cell at concentrations ~100x higher than DNA nucleotides, so the enzyme has evolved clever strategies to select one over the other. RNA polymerases, for comparison, are the enzymes that take a DNA sequence as template and then convert it into RNA. They are involved in gene expression, for example. To convert a DNA polymerase into an RNA polymerase (and all the other functions I mentioned earlier), the authors did a fairly straightforward directed evolution experiment. First, they took four DNA polymerase enzymes belonging to various archaea. These DNA polymerases don’t check for DNA vs. RNA as stringently as other types of cells, so they’re a good starting point to evolve RNA polymerases. The authors inserted some targeted mutations into these enzymes, based on known mutations in the literature. For example, they swapped the amino acid at position 409 for a smaller amino acid, thus removing a “gate” that keeps RNA building blocks from entering the enzyme. Next, they took the four genes encoding these DNA polymerases and cut them up into 12 segments each. They randomly stitched these 12 segments together — from the four different genes — to build millions of unique variants. Each shuffled gene was inserted into an E. coli cell. Then, they grew up these cells (each carrying a unique polymerase) and put them into microfluidic droplets. A device isolates each droplet, lyses the cell open, and releases the polymerase. The droplet also contains RNA building blocks and a DNA template, encoding a fluorescent reporter. If the polymerase begins synthesizing RNA, it will produce a detectable signal. They screened about 100 million droplets in 10 hours of work, searching for those with a signal. For each well that yields a fluorescent signal, the researchers isolated the DNA and sequenced it to figure out which polymerase it was. They repeated this 3x times, finally isolating a really excellent RNA polymerase variant which they called "C28." C28 has 39 mutations compared to the wildtype enzymes. It incorporates about 3.3 nucleotides of RNA per second, with 99.8% fidelity. The crazy thing is that this enzyme can also copy DNA or RNA templates back into DNA (reverse transcription), or use chimeric DNA-RNA molecules as a template and amplify them. It is just a super versatile polymerase that can act on DNA, RNA, or modified nucleotides, to build just about anything.
English
Aanchal retweetledi

Umberto Eco, who owned 50,000 books, had this to say about home libraries:
“It is foolish to think that you have to read all the books you buy, as it is foolish to criticize those who buy more books than they will ever be able to read. It would be like saying that you should use all the cutlery or glasses or screwdrivers or drill bits you bought before buying new ones.
“There are things in life that we need to always have plenty of supplies, even if we will only use a small portion.
“If, for example, we consider books as medicine, we understand that it is good to have many at home rather than a few: when you want to feel better, then you go to the ‘medicine closet’ and choose a book. Not a random one, but the right book for that moment. That’s why you should always have a nutrition choice!
“Those who buy only one book, read only that one and then get rid of it. They simply apply the consumer mentality to books, that is, they consider them a consumer product, a good. Those who love books know that a book is anything but a commodity.”

English
Aanchal retweetledi

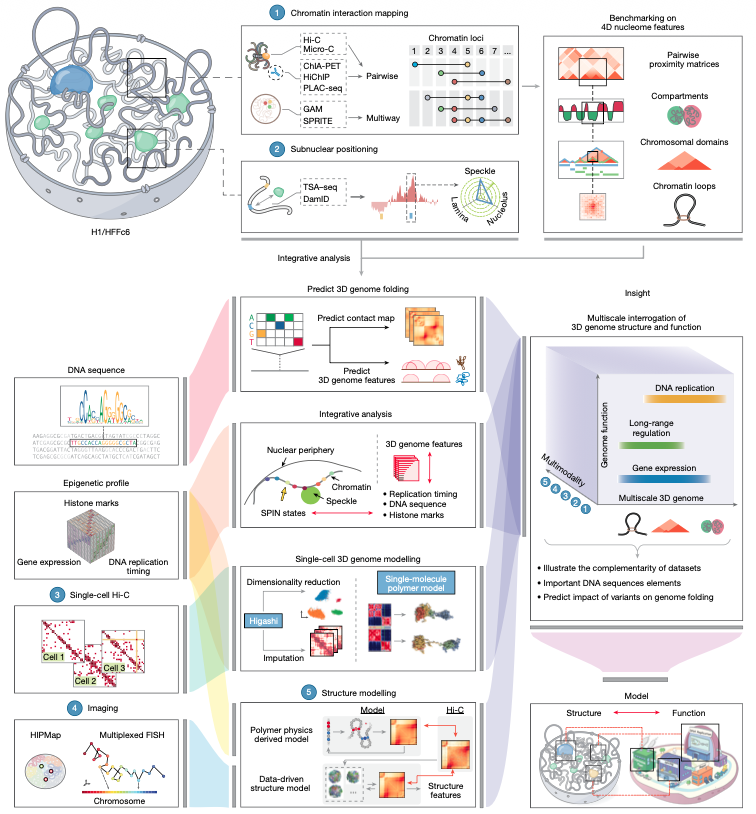
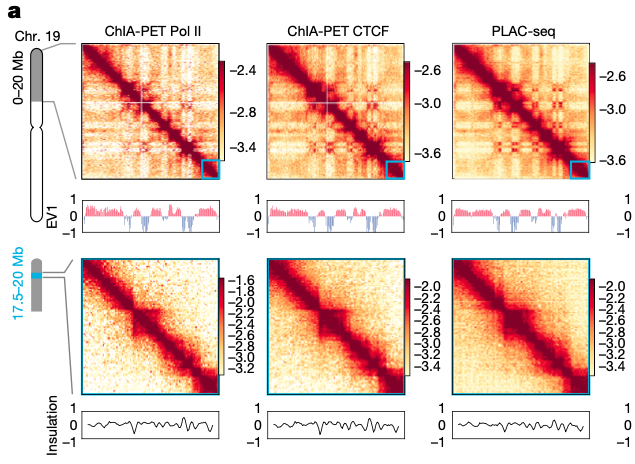
Many people think of the genome as a string of "letters." The human genome, say, has 3.2 billion base pairs of DNA organized across 23 pairs of chromosomes.
But the genome is a 3D object. Genes located on entirely different chromosomes might be clustered together. Mutations in these "distant" genes can lead to disease in surprising ways.
For a new paper in @Nature, researchers released several "maps" of human genomes from two types of cells: embryonic stem cells and fibroblasts. They compared methods to see which ones are least biased, and found many long-range interactions between genes.
The article does a good job explaining how “the genome is organized at different scales”:
> On a single chromosome, histones control which parts of the DNA sequence are accessible and expressed.
> At the scale of hundreds of thousands of bases, “chromatin loops in a dynamic manner,” the authors write, bringing distant genes closer together. > Across chromosomes, sequences "cluster together in space to form subnuclear compartments."
Examples abound. Enhancers, for example, are short DNA sequences that regulate the expression of far away genes. They do this by *physically* touching the genes they control; a protein called cohesin grabs the DNA and tugs it into big loops.
Even promoters, which are thought of as being associated with one gene or operon, can cluster together across many genes! A protein, Ronin, grabs promoters and pulls them together. This is apparently done mostly for genes that tend to be "on," as it helps enzymes find genes faster/not have to diffuse far away to find targets. (This also happens with genes that tend to be "off;" so-called polycomb proteins grab onto promoters, cluster them up, and silence all of them at once. It's a way for the cell to conserve energy.)
One consequence of this spooky "action-at-a-distance" is that diseases might arise from mutations in unexpected locations. Editing these regulatory sequences, in other words, might in turn affect a gene located on an entirely different chromosome that *is* associated with that disease.
Genetic mutations linked to autism, for example, are known to disrupt the 3D organization of the genome. A single deletion at a gene, TAL1, also affects its ability to form long-range chromatin interactions with other genes, leading to leukemia. There are probably many other, as-yet-undiscovered, instances of this.

English
Aanchal retweetledi

1/3
People often ask why I seem so ‘pro’ India.
Answer is simple: in over 20 years and dozens of trips, I have NEVER once faced disrespect, negativity, backstabbing or bad energy there.
Not once!
Only love, kindness, loyalty, warmth and respect — every single time.
2/3
I’ve made lifelong friendships there that I treasure. Friends who became family. Brothers for life.
I know respect has to be earned — and I like to think I earned mine by producing the goods on the cricket field year after year, giving my everything! Whether it was against India or for an IPL team.
3/3
When a country and its people give you nothing but pure positive energy your entire adult life, that love gets returned tenfold.
India gave me its heart first.
So India will always have mine.
Forever grateful. KP ❤️
English
@MartinPacesa @sokrypton I really thought this was something about SAE1/SAE2, the SUMO E1 ligase 😆
English

I can very well see how E1 embeddings use will replace ESM2 soon! Also amazing performance of MSA pairformer! @sokrypton
Profluent@ProfluentBio
Protein language models just got an upgrade. Meet Profluent-E1: a free, flexible, frontier protein sequence encoder. E1 is built with retrieval augmentation to learn from multiple sequences. Models trained over 4T tokens with only 150M-600M params, E1 is SOTA for zero-shot functional and unsupervised structural tasks. It raises the bar for protein representation learning and is freely available today.
English
Aanchal retweetledi

Recently, we were courting an extraordinary candidate, who was deciding between joining FutureHouse or taking a job at one of the frontier AI labs. He was looking for somewhere to do his life’s work, where he would be able to bet on himself. He recognized that he would have more agency and impact at FutureHouse, and found the mission more compelling. He spent a week with us, and had a huge grin on his face the whole time. But, at the same time, he was wondering whether he just wanted the greater stability associated with a more established company. In our last call, he described the decision to me as “the difference between a rocket ship and a luxury yacht in harbor.”
In the end, he chose the yacht. I find it difficult to understand the frame of mind of someone who, in his late 20s, at the height of his power, would choose something that in his own words essentially amounted to a kind of retirement. I also have the feeling that, with the frontier lab in question, I am watching in real time how fast-moving startups turn into big corporations and die, by failing to select for rocket ship people and selecting for yacht people instead. His choice, though disappointing, is probably net good for FutureHouse. I have long ago learned that people who want to spend their time on yachts should do so, and that putting such people on rocket ships inevitably leads to disaster.
More importantly, though, the entire experience has made me appreciate much more deeply the extraordinary gumption of my team, who have chosen to join me on this particular rocket ship rather than taking their own jobs at OpenAI, Anthropic, Google, or the like. They sacrifice pay, stability, comfort, and the like in order to pursue a dream for the future of humanity. They choose to bet on themselves, and on us as a team, rather than on someone else. They choose to build a new ladder rather than climb an existing one. To quote a great essay, civilization is one long, anxious wait for such individuals. I owe them all a great debt.
In order of appearance:
Andrew White, my cofounder.
Samantha Cox
Jon Laurent
Mike Skarlinski
Sid Narayanan
Lauren Jaeger
James Braza
Ryan Rhys-Griffiths
Michaela Hinks
Tyler Nadolski
Kiki Szostkiewicz
Geemi Wellawatti
Mayk Caldas
Jasmine Dhaliwal
Ludo Mitchener
Remo Storni
Albert Bou
Mo Razzak
Ali Ghareeb
Ben Chang
Anna Shive
And, of course, Eric Schmidt, who provides the fuel; who, at age 40, decided to join a spunky startup rather than take a more stable job; and who now, nearly 70, builds actual rocket ships. He is a great inspiration.

English
Aanchal retweetledi

Measuring glucose repeatedly via small needle pricks is inconvenient and carries risk of infection. New approach by IISc team exploits photoacoustics to accurately measure concentration of chiral molecules like glucose.
iisc.ac.in/events/detecti…
#IIScresearch
@pnjayaprakash88

English
Aanchal retweetledi


Aanchal retweetledi

This may be a mere coincidence or may be a well contrived effort to encrypt it. In either case, I find both the scenarios equally bizzare!
MathMatize Memes@MathMatize
Favourite examples where pi appears unexpectedly?
English
Aanchal retweetledi

I want to tell you a story about computers, creativity and awe! (1/N)🧵
Sydney Brenner once said in 2012 that “nobody has actually read the human genome. I mean, computers have processed the human genome, but we all know computers are stupid.”
(This is a talk I gave last week..)

English
Aanchal retweetledi

I’m European.
Last year, I moved to India.
What I experienced shattered my Western mindset.
Here are 10 life-changing lessons I learned in India that reshaped how I see the world:

English
Another filament story from our team, this time on Ub E3 ligase, SIAH1. The entire analysis is hardwork of Franck, our cool collaborator Sebastien and Lucija's and mine PI, Marcin. The contribution of our team continues towards the realms of Science less traversed. Proud!
Marcin J. Suskiewicz@MSuskiewicz
Happy to share our study showing that the Ub E3 ligase SIAH1, known to dimerise via its C-term SBD, also dimerises via its N-term RING. When these tendencies combine, fl SIAH1 forms multimers, which might explain its clustering in cells & preference for multimeric substrates.
English
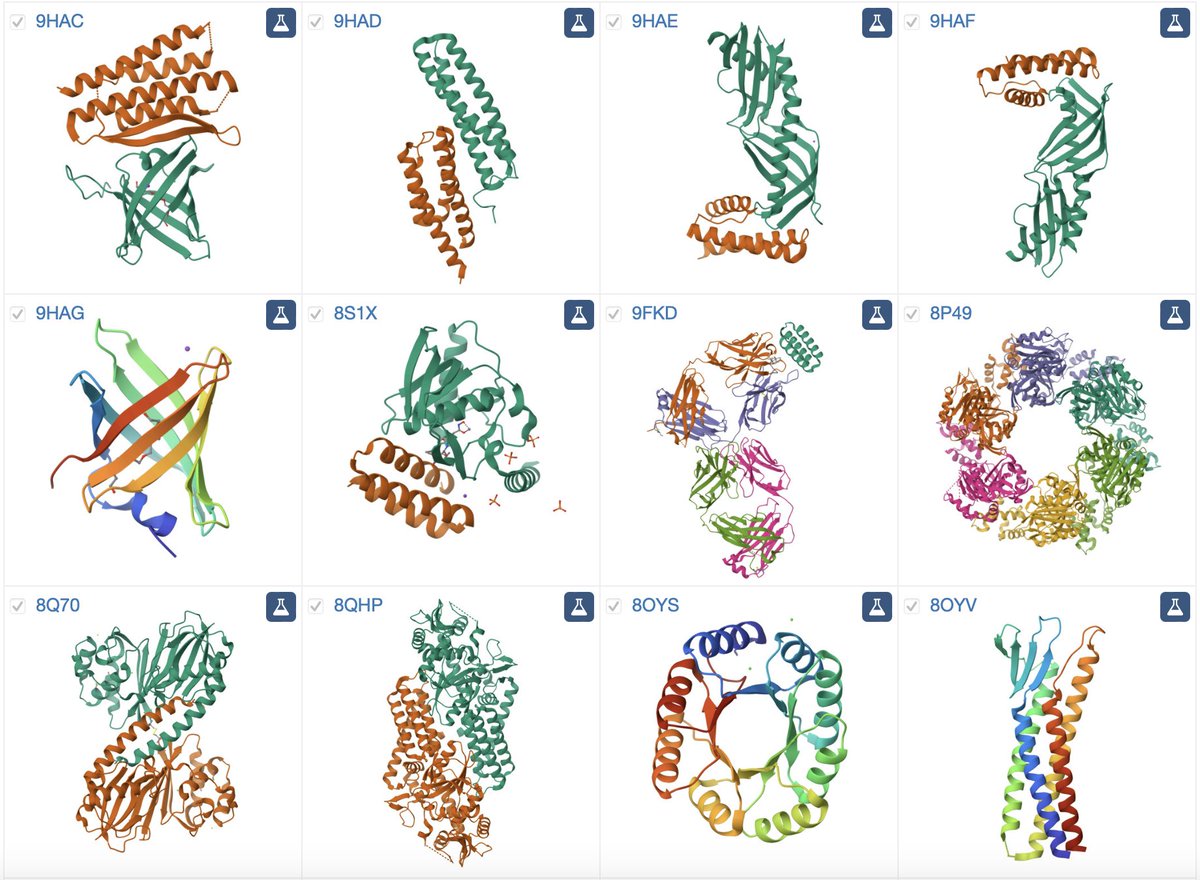
Few more new PDBs released from us before the end of the year :)
English

Aanchal retweetledi

Molecular dynamics data will be essential for the next generation of ML protein models
owlposting.com/p/an-argument-…
old article from the summer, but i kinda increasingly view it as missing the forest for the trees
MD feels way, way more important in the long term than anything that will ever happen with proteomics models, especially as neural network potentials get going. my characterization of MD as a useful synthetic data generation process still feels directionally accurate, but i feel so strongly that it will be fundamentally more useful than that. feels like the final frontier in a way
English
@sokrypton I didn't knew about this :'( Are there more such events?
English


This insightful paper by @PauliGroup , which was the subject of interest in our lab's first journal club (in Biorxiv then), is now published!
x.com/Origichals/sta…
Victoria Deneke@deneke_v
The life of each one of us began when a sperm and an egg came together. But what actually happens at a molecular level? Our latest work @PauliGroup @CellPress reveals a conserved fertilization complex that bridges sperm and egg in vertebrates! (1/8) cell.com/cell/fulltext/…
English