Sabitlenmiş Tweet
PageIndex
1.7K posts

PageIndex
@PageIndexAI
Building Vectorless Long-Context Infra
London Katılım Haziran 2023
291 Takip Edilen1.5K Takipçiler


处理超长专业文档时,向量检索常常找不准关键段落,因为它只看相似度、不看文档结构。
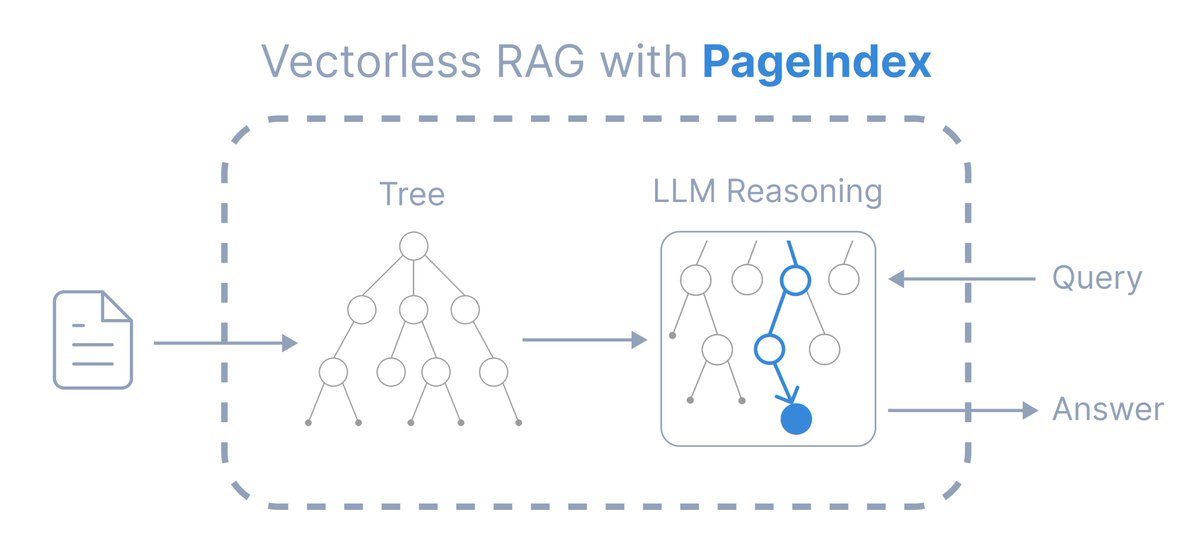
VectifyAI/PageIndex 换了一条路:用 LLM 推理替代向量数据库,通过文档的自然层次结构(章节、页码)进行检索,模仿人类专家浏览复杂文档的方式。
GitHub:github.com/VectifyAI/Page…
主要功能:
将文档组织成层次化树状索引,而非人工切块
根据完整对话上下文和领域知识自适应检索
提供可追溯、可解释的结果,明确标注页码和章节引用
在金融文档基准测试中达到 98.7% 准确率,超越向量检索
pip 安装,MIT 协议,30.9k stars,支持本地自托管。适合处理 SEC 文件、监管报告、学术论文等超出 LLM 上下文窗口的专业文档。
中文



VectifyAI just dropped PageIndex and it is a massive win for RAG. A document index designed for vectorless, reasoning-based retrieval to kill the noise. This is clean work for anyone building high-precision LLM apps. 4,555 stars. github.com/VectifyAI/Page…
English

【予言】RAGの「壁」を壊す、期待のリポジトリ。
VectifyAIの「PageIndex」。
従来のベクトル検索を捨て、AIがドキュメントの「構造」を理解して人間のように推論して探し出す。
・Vector DB不要
・チャンク分割の苦悩から解放
・FinanceBenchで98.7%の驚異的な精度
専門文書の解析に悩む層には、救世主になるかもしれません。
github.com/VectifyAI/Page…
#RAG #AI
日本語
English

🚨 NEW YOUTUBE IS LIVE 🚨
youtu.be/U2Z0PKtOGQs?si…
Diving into the significance of @PageIndexAI incorporation to @Theta_Network Edgecloud 😎🏝️
#theta #tfuel #tdrop #aethir #zcash #tao

YouTube
English
@AlphaSignalAI Thanks for sharing PageIndex! We are rethinking RAG without vector DBs — PageIndex for reasoning-based, context-aware retrieval.
github.com/VectifyAI/Page…
English

@rosie_codes Thanks for sharing PageIndex, our vectorless, reasoning-based RAG framework!
github.com/VectifyAI/Page…
English

PageIndex skips the vector DB entirely. It builds a tree index and uses LLM reasoning to navigate documents — no chunking, no similarity guessing, just finding what you actually need. #RAG #LLM #OpenSource
🔗 Link in the comments

English
@blackthornecl Thanks for sharing PageIndex and our bet on reasoning-as-retrieval.
github.com/VectifyAI/Page…
English

¿Cuánto pagarías por una herramienta que hace esto? Bueno, es gratis y open source. 🔥
Hace 6 meses necesitaba buscar algo específico en 500 informes financieros. Los embeddings y similarity search me devolvían resultados...meh.
Así encontré PageIndex.
Suena simple pero cambia todo:
1. No usa Vector DB — razonamiento puro sobre estructura del documento
2. No hace chunking — mantiene contexto natural de cada sección
3. 98.7% de precisión en FinanceBench
4. Construye un árbol jerárquico como tabla de contenidos inteligente
El sistema simula cómo un humano navega un documento: piensa, razona y llega directo a la sección relevante. 📄
No más "vibe retrieval" con resultados opacos. 🔍
Prueba: pip install pageindex o el chat integrado.
Si te resulta útil, dale RT. Ayuda a la comunidad 🔄
Español

RAG行业要被干翻了!😱
PageIndex这玩意儿直接颠覆传统RAG!不用向量DB、不用嵌入、不用切块、连相似搜索都省了,直接给文档建树形索引,让LLM像人一样逐层推理。
FinanceBench爆到98.7%准确率,秒杀所有向量方案。100%开源,开发者/研究者/文档分析玩家直接起飞,Pinecone那些老掉牙可以扔了!
🔗 chat.pageindex.ai
用了就回不去😭

中文
@SidJain_80 Thanks for sharing PageIndex, Sid!
github.com/VectifyAI/Page…
English

Everyone is trying to fix RAG with better embeddings.
Bigger vector DBs. Smarter chunking. More retrieval tricks.
But the real issue?
Similarity ≠ relevance
github.com/VectifyAI/Page…
PageIndex takes a completely different route:
- No vectors
- No chunking
- Builds a tree (like a human reading a doc)
- Uses reasoning to navigate, not just retrieve
Instead of:
“find similar text”
It does:
“understand structure -> reason -> find the right section”
This is why it beats traditional RAG on complex docs (98.7% on FinanceBench)
RAG isn’t broken.
It’s just been solving the wrong problem.
English

ベクトル検索よりいいと聞いたPageIndex見てみた。ベクトル検索、チャンク分割をやめて目次ツリーを作ってそこから情報がありそうな場所を推論して探してくらしい。1つの長文pdfなら良さそう
github.com/VectifyAI/Page…
日本語
@CryptoFamilyOz1 Thanks for sharing PageIndex, our vectorless, reasoning-based retrieval framework for AI agents.
github.com/VectifyAI/Page…
English

@CoderArmy Thanks for sharing PageIndex, our vectorless, reasoning-based RAG framework!
github.com/VectifyAI/Page…
English

Stop saying RAG is dead💀
Everyone is hyping up PageIndex, but it's not a silver bullet.
In this video we're breaking down:
✅ Why Vector RAG still matters
✅ When to use PageIndex vs. GraphRAG
✅ How to build a hybrid architecture for real-world production
Don't follow the hype, understand the engineering:
youtu.be/-ADU-H1ZNjg?si…

YouTube
English
@funkyfr31801951 Thank you for sharing PageIndex and our bet on "reasoning-as-retrieval"!
github.com/VectifyAI/Page…
English

interesting idea on how to more effectively use llm's, pageindex looks like its got some decent traction on github. still a bit baffled by how it works, but what it does(assuming true) is pretty sweet. good work $theta folks
Theta Network@Theta_Network
NEW: We just shipped PageIndex for Theta EdgeCloud AI agents. It fixes one of the most common reasons AI agents give bad answers, and the benchmark numbers are worth a look. It's also already available for your Theta-powered AI agents. 🧵
English
English

Wow, @Theta_Network's #EdgeCloud #AI Agents just got SIGNIFICANTLY smarter. #PageIndex on #EdgeCloud's AI agents pulls the EXACT section that answers the question.
Let's GOOOOOO 🤠😎🔥🔥 $THETA $TFUEL #THETA #TFUEL
Read more here : medium.com/theta-network/…
Theta Network@Theta_Network
You can read more about the update here on our blog: medium.com/theta-network/…
English
@0xKingsKuan 感谢分享我们的无向量、基于推理的 RAG 解决方案 PageIndex!
github.com/VectifyAI/Page…
中文

RAG 行业要被干翻了!
这是 PageIndex 向量零 RAG 革命神器,彻底把传统 RAG 行业干翻!无需向量 DB、无嵌入、无切块、无相似搜索,直接给文档建树形索引,让 LLM 像人类读书一样逐层推理。
FinanceBench上直接干到 98.7%准确率,完爆所有向量 RAG方案。100% 开源,开发者/研究者/文档智能分析玩家直接起飞,再也不用 Pinecone 那些老掉牙的东西了!
chat.pageindex.ai
用了就回不去了 😭


币世王 | 🦅🐬TermMax@0xKingsKuan
还在用自己手动刷视频、记笔记、总结关键点?太落后了! algrow.online/mcp Claude 现在直接能看视频了!直接丢 YouTube、TikTok 或 Instagram 链接进去,让 Claude 自己看完、听完、拆完: • 秒总结核心内容 • 提取关键点 + 时间戳 • 分析逻辑/卖点/可优化点 全部在 Algrow 里实时上线!
中文

哈哈,没想到引来官方回复了😂😂
之前我说 PageIndex 不支持大量文档,原来是在企业版 PageIndex File System 中支持的,看了下是使用了类似知识图谱、主题聚类的方式实现的,这个逻辑上就说得通了。确实可以通过这种方式来做。
感觉方式跟我的 llm_wiki 有点像,知识图谱+comminity,主题聚类也是个不错的办法。不知道具体实现方式是什么样子的,开源版本中好像没有包含这部分。
PageIndex@PageIndexAI
@nash_su 您好,针对多文档检索的场景,我们也推出了 PageIndex File System 来解决这一问题。具体可以参考我们的博客 pageindex.ai/blog/pageindex…
中文
@nash_su 您好,针对多文档检索的场景,我们也推出了 PageIndex File System 来解决这一问题。具体可以参考我们的博客
pageindex.ai/blog/pageindex…
中文
看到很多人在推 PageIndex,说颠覆了向量方式
我前几天看到这个项目时候分析了下,这个思路只适合文档数量很小的场景,他的原理是给文档每页做 summary,然后把所有页面摘要都给到 LLM,让模型自己选择。所以只能检索单文档,并不支持对一个文件夹或更大范围的文件进行检索。
github.com/VectifyAI/Page…
中文
@AiwithYasir Thanks for sharing PageIndex!
github.com/VectifyAI/Page…
English

The entire RAG industry is about to get cooked.
Researchers have built a new RAG approach that:
- does not need a vector DB.
- does not embed data.
- involves no chunking.
- performs no similarity search.
It's called PageIndex. Instead of chunking your docs and stuffing them into pinecone, it builds a tree index and lets the LLM reason through it like a human reading a book.
hit 98.7% on financebench. beats every vector RAG on the leaderboard.
no embeddings. no chunking. no vector DB.
100% open source.
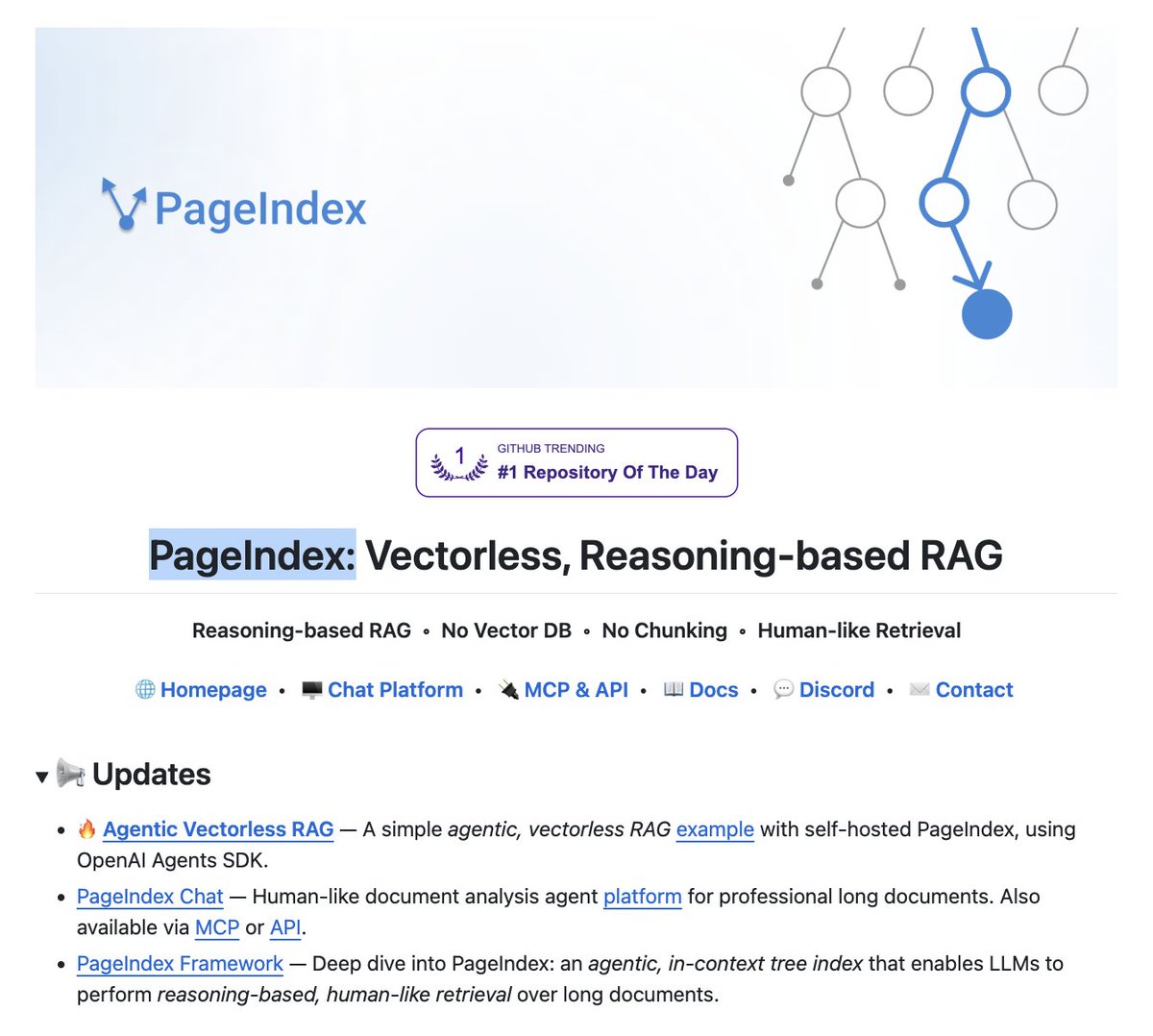
English

THE ENTIRE RAG INDUSTRY IS ABOUT TO GET SHAKEN 🤯
researchers just built a new RAG method called PageIndex
and it breaks almost every rule people follow today
→ no vector DB
→ no embeddings
→ no chunking
→ no similarity search
instead of chopping docs into pieces
it builds a tree-like index
and lets the model navigate information more like a human
the result?
98.7% on FinanceBench
beating traditional vector RAG systems on the leaderboard
100% open source
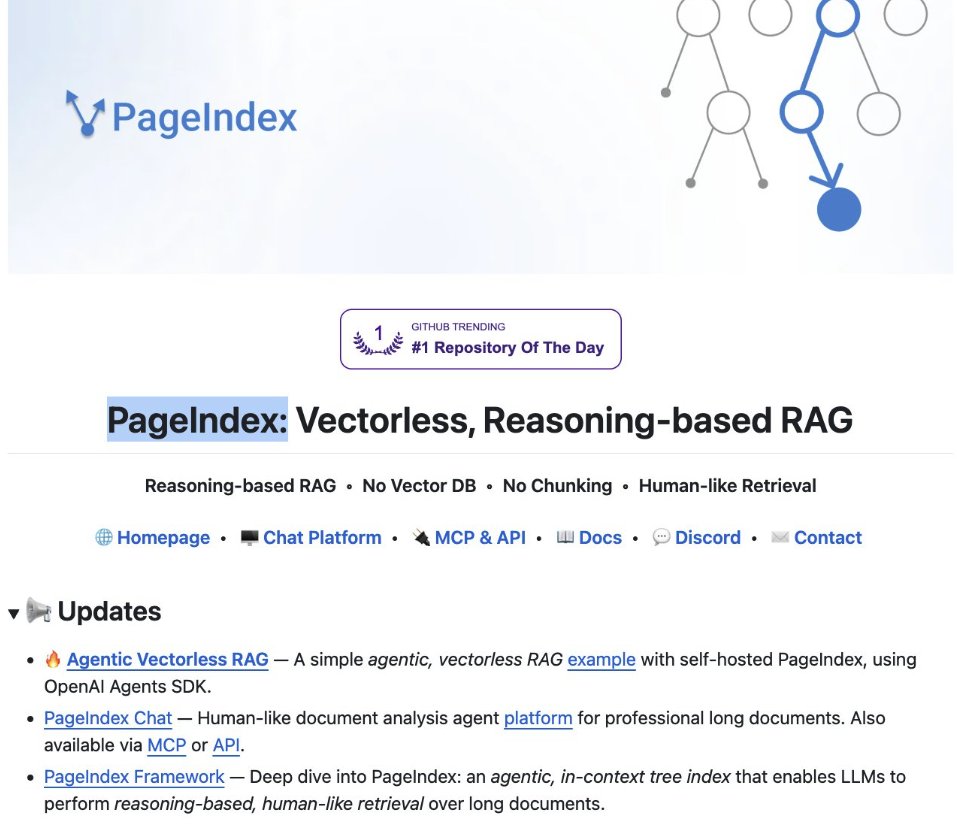
English