Sabitlenmiş Tweet
Q²Ubik
1.5K posts


@NewsReputation A mí me aparecen como anuncios, señalado en gris, en la esquina superior derecha.
Español

Patético.
Ahora Twitter me muestra los tuits patrocinados sin marcar que son publicidad, haciéndolod pasar por cuentas que sigo.
Cuando el nuevo propietario dio como una de las razones de compra el mejorar la experiencia de los usuarios con la publi. Ya.
Español


Vamos a lo digital. Sus dedos sirven como rastrillos.
Ministerio Transformación Digital Función Pública@mintradigital
La IA también transforma el campo. Proyectos como Agro4Data optimizan el riego, ayudan a ahorrar agua y mejoran la producción con datos útiles para agricultores. Puedes unirte a un espacio de datos y pedir el Kit Espacios de Datos. 📅 Hasta el 31/03 cred.digital.gob.es/kit-de-espacio…
Español
@mintradigital @SEDIAgob Vamos a lo digital. Sus dedos sirven como rastrillos.
Español

La IA también transforma el campo.
Proyectos como Agro4Data optimizan el riego, ayudan a ahorrar agua y mejoran la producción con datos útiles para agricultores.
Puedes unirte a un espacio de datos y pedir el Kit Espacios de Datos.
📅 Hasta el 31/03
cred.digital.gob.es/kit-de-espacio…
Español
@NewsReputation 'Forty' es el primer número en inglés que tiene las letras en orden.
Español
Ningún número antes de 4 contiene la letra A.
Encyclopaedia Britannica@Britannica
No number before 1,000 contains the letter A.
Español

Es cierto que en tiempos de IA el periodismo tiene una función fundamental que desempeñar.
La pregunta es si unos periodistas que con frecuencia dejan que el activismo se imponga al rigor tienen la autoridad para ejercer dicha función.
Algo de autocrítica vendría bien.
Español

Qué pasada es construir software supervisando e interactuado con agentes! El problema es ese complejo de cangrejo en el agua calentándose poco a poco que te entra...
Español

Devastadora soledad
Borrachito 🥃@borrachito
¿Cuál es tu primer pensamiento cuando ves este refrigerador?
Español
“Las afirmaciones extraordinarias requieren pruebas extraordinarias”.
MIT Technology Review@techreview
This company claims a battery breakthrough. Now they need to prove it. trib.al/ZKNlTkY
Español
Q²Ubik retweetledi

"ChatGPT solo es un predictor de palabras".
¿Has oído eso? Es una crítica habitual contra los LLM como ChatGPT o Claude. Suena inteligente; es perezosa.
Primero: es una crítica *anticuada*.
Predecir el siguiente token describe el pretraining: el modelo ve milmillones de textos y aprende a predecir qué palabra viene después. Pero hace un año que los modelos pasan una segunda fase distinta: reinforcement learning con tareas verificables (RL).
Ahí el modelo recibe un problema con solución conocida. Genera intentos ("razona"), recibe señal de acierto/error y ajusta sus parámetros. ¿El resultado? Aprende a resolver problemas por sí solo. DeepSeek lo documentó: sin ejemplos que imitar, adquirió espontáneamente trucos como razonar paso a paso, autocorregirse o explorar alternativas. Todo eso emergió de la presión por obtener la máxima recompensa durante el RL.
Segundo: nunca me convenció en general.
Decir que "solo predicen" confunde cómo se entrena algo con lo que ese algo es o hace.
El símil es Karate Kid 🥋. Se entrena dando cera y puliendo cera… pero de ahí emerge un karateca, no un pulidor de vallas.
¿Otro ejemplo extremo? Los humanos fuimos moldeados por la evolución. ¿Alguien nos definiría como "meros maximizadores de genes"? No. Escribimos poesía, nos sacrificamos por desconocidos. El proceso que nos dio forma no nos define.
Los LLM no son omnipotentes. Tienen limitaciones que serán algunas provisionales y otras intrínsecas. Pero es un error —imho— definirlos como "meros predictores".
Un entrenamiento simple puede hacer emerger algo distinto y sorprendente. Y eso empuja una pregunta incómoda: ¿qué otras capacidades podrían emerger sin que lo planeemos?

Español

Cuando Twitter/X te recomienda que sigas a tu ex-director que sigue tan "singer morning" y vende-humo como antaño.
Efectivamente, el algoritmo de X no es para mi
Español
Q²Ubik retweetledi

Glimpse the past.
Electric vehicle.
Krieger "Landaulette" automobile, circa 1906. tinyurl.com/43c2hf37

English
Q²Ubik retweetledi

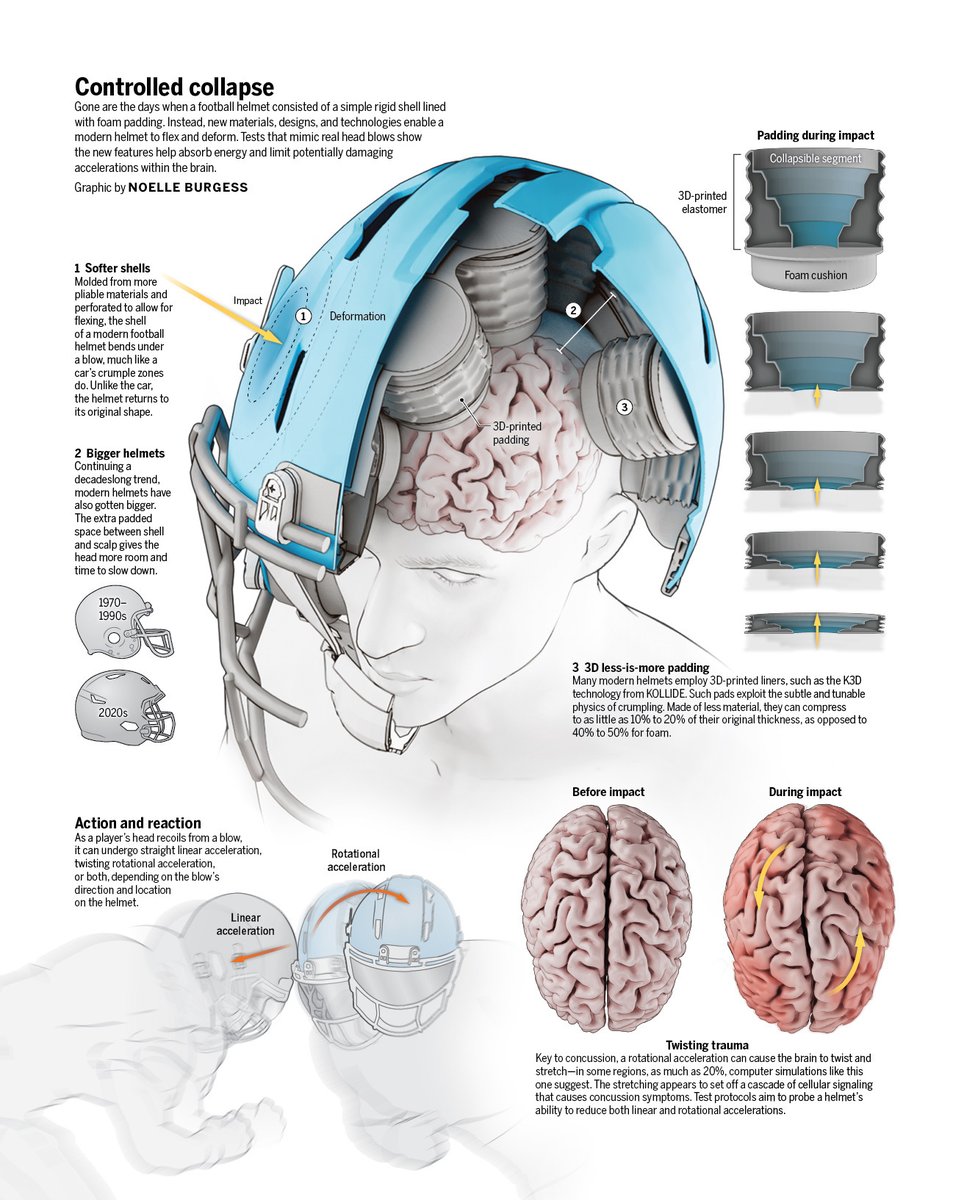
Gone are the days when a football helmet consisted of a simple rigid shell lined with foam padding.
Instead, new materials, designs, and technologies enable a modern helmet to flex and deform. Learn more: scim.ag/4a5XMcK @NewsfromScience
English
Esto merece la pena oírlo:
x.com/maria_caballer…
María Caballero@maria_caballero
Susana Sumelzo, Sª de Estado de Sánchez, no ha querido responder: ¿Por qué Montearagón SL, empresa de su familia, estaba domiciliada en el mismo piso que Servinabar? ¿Por qué Sumelzo SA está domiciliada donde Soluciones de Gestión? Casualidades de las empresas de la trama...🤔
Español
Ostras tú, qué vergüenza lo del Ministerio de Vivienda, cambiando de mes de referencia, nada menos que de agosto a noviembre, para pretender y vender que la dinámica cambia.
Qué regalo las Notas de Comunidad, que retratan a los tramposillos. Qué patético que lo sea un Ministerio.
Ministerio de Vivienda y Agenda Urbana@viviendagob
📊 El número de viviendas turísticas registra su mayor caída de la serie histórica: 🔸Descenso interanual del 12,4%, el dato más alto desde que hay registros. 🔸Las viviendas comercializadas en plataformas se redujeron entre mayo y noviembre de 2025 en más de 52.000 unidades.
Español
@Dukenan16 Estos de electomanía empezaron haciendo ruido, con sus frescos y frutales pronósticos de resultados, y ahora hacen "música de acompañamiento".
Español
Lo de elegir demagogos oportunistas para encabezar la izquierda ya se ha probado y no acaba bien.
Necesitamos volver a tener políticos solventes.
x.com/electo_mania/s…
EM-electomania.es@electo_mania
‼️Gabriel Rufián 🍋 llevará a cabo una 'gira' con líderes de la izquierda desde el próximo 18 de febrero, según adelanta @laSextaXplica Habría hablado con todo el espectro político a la izquierda del PSOE 🌹 para explorar una candidatura unitaria. 👇 electomania.es
Español
Q²Ubik retweetledi
The evolution of the football helmet, a critical safety device, has accelerated in recent years, driven by concerns over the long-term effects of concussions, new concepts and materials, and data-driven test protocols.
Learn more this week in Science: scim.ag/4tjrPoI
English
Helmet challenge.
Science Magazine@ScienceMagazine
The evolution of the football helmet, a critical safety device, has accelerated in recent years, driven by concerns over the long-term effects of concussions, new concepts and materials, and data-driven test protocols. Learn more this week in Science: scim.ag/4tjrPoI
Nederlands