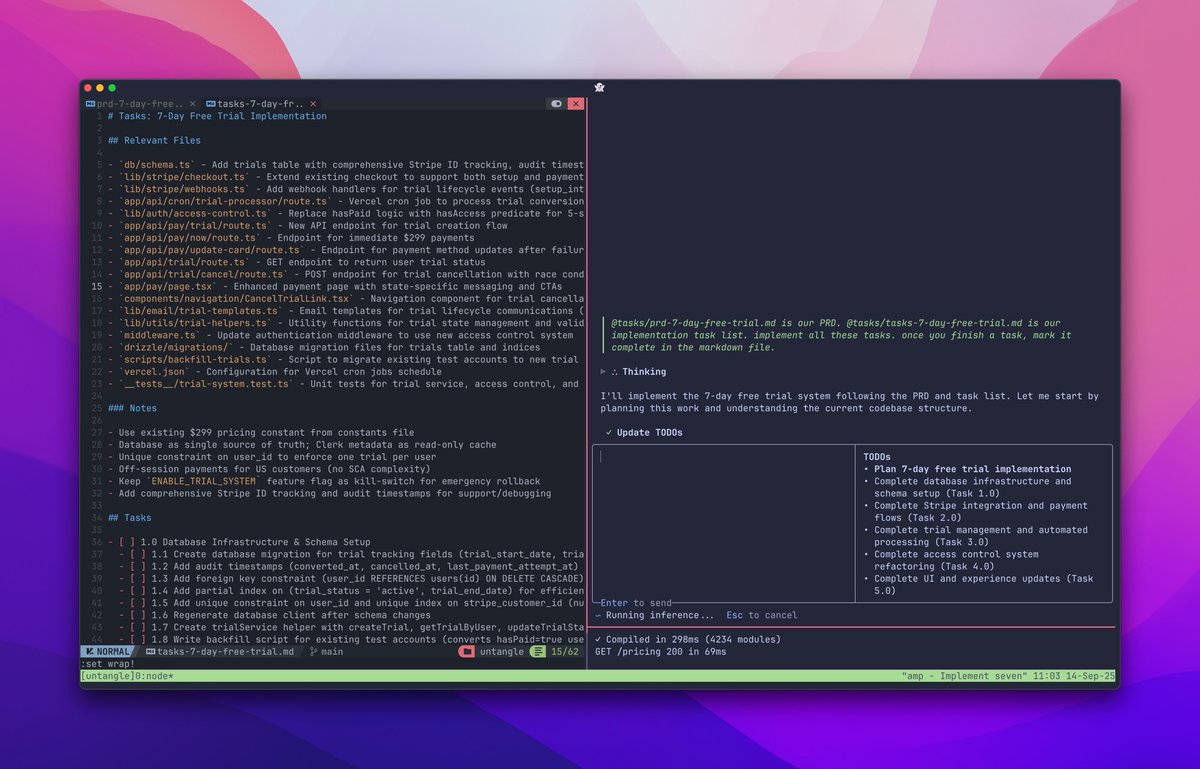
YM
274 posts





i shit you not, it's an IDE AND has browser embeds, so I can localhost multiple pages at once in the same canvas
obsidian's canvas being able to embed ANYTHING, and the @obsdmd editor being literally just code-mirror, makes it the perfect worspace
(@tldraw is also cool)
Alfon@alfonsusac
@bedesqui @kepano using obsidian as IDE is next level power user i havent seen
English


Coding Agent都出来一年多了,记忆机制都还是如此的垃圾,错过的bug换个窗口一错再错,怒而自己又做了一个。
安装:npm i -g onecontext-ai
OneContext的机制是让Agent 自己管理自己的上下文, 底层靠的是文件系统+Git+图谱,这套机制可以让二流模型直接超越GPT/claude,详细看我的论文发表:
Agentic Reasoning:
aclanthology.org/2025.acl-long.…
Git Context Controller:
arxiv.org/abs/2508.00031
这个context 可以无缝加载到不同 session、不同设备,不同 Codex / Claude Code之间,以context为中心,不以工作路径或者模型为中心。
用法:
1. 在 OneContext 里照常打开 Claude Code 或 Codex,它会自动帮你把历史和上下文组织成一个持续存在的 context layer。
2. 在同一个 context 下开新的 agent,它能自动读到之前所有的历史记录
3. 把这个 context 用链接发给别人,对方可以在完全相同的上下文上继续构建。
中文






把@dotey 宝玉老师的封装的 Claude Agent SDK又优化了一下,拿来自用了。这玩意配合上 MCP+Skills 比一般的Chat 客户端可要猛得多。
——
就是不用订阅的 Claude Desktop,还能改装
——
kit.deeptoai.com ,拿去玩吧(GLM 4.6 based)。每周都说戒撸,还是戒不了,Vibe Project 还是一周一发。
——
感觉这周又玩过了,天天这么玩,人都要废了,快救救我,说好要接商单的,求你们来找我啊,让我干点正事,挣点钱。球球
中文


🚀 No More Train–Inference Mismatch!
We demonstrate bitwise consistent on-policy RL with TorchTitan (training) + vLLM (inference) — the first open-source run where training and inference numerics match exactly.
It only takes 3 steps:
1️⃣ Make vLLM batch-invariant (same seq → same output regardless of batching)
2️⃣ Ensure forward passes in training use identical kernels as inference
3️⃣ Add custom backward passes in PyTorch
✅ Verified on Qwen3 1.7B + GSM8K:
• batch_inv_ON (bitwise exact) → KL=0.0, faster convergence, higher reward
• batch_inv_OFF → reduced reward, instability
We audited every op, imported vLLM’s fused kernels (SiLU MLPs, RMSNorm+residual), and wrote matching backward passes. Run is fully on-policy, deterministic, and reproducible.
Next:
• Unified model code
• torch.compile support
• Perf tuning (current bitwise RL ≈2.4× slower)
• Broader model + op coverage
🔗 blog.vllm.ai/2025/11/10/bit…
#vLLM #TorchTitan #RL #LLM #AIResearch
English


大家一直吐槽 LobeChat 切换慢,卡顿,之前我一直觉得是我们 next 的用法不对,所以一直在尝试各种写法,从 RSC、平行路由、拦截路由,一直到动静态渲染、路由段重写等等方案。
2 年时间硬生生从 next 小白变成了 next 专家,但还是没有效解决页面切换卡顿的问题。而最近把两个路由段(discover 和 settings)换成了 react-router ,做了 SPA 改造,瞬间不卡了😅 所以 2.0 准备全量改造成 SPA 了
现在回过头来看就是陪 Next 踩了两年 RSC 的坑 😌
paperclover.net/blog/webdev/on…
中文






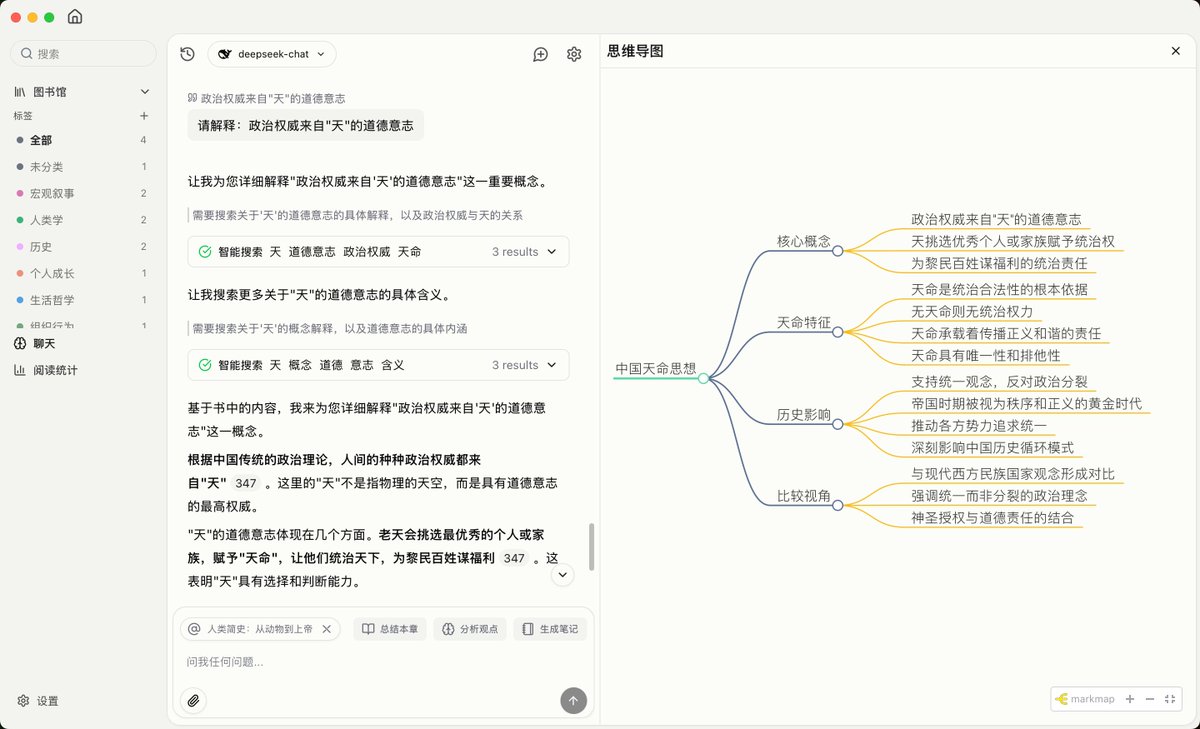

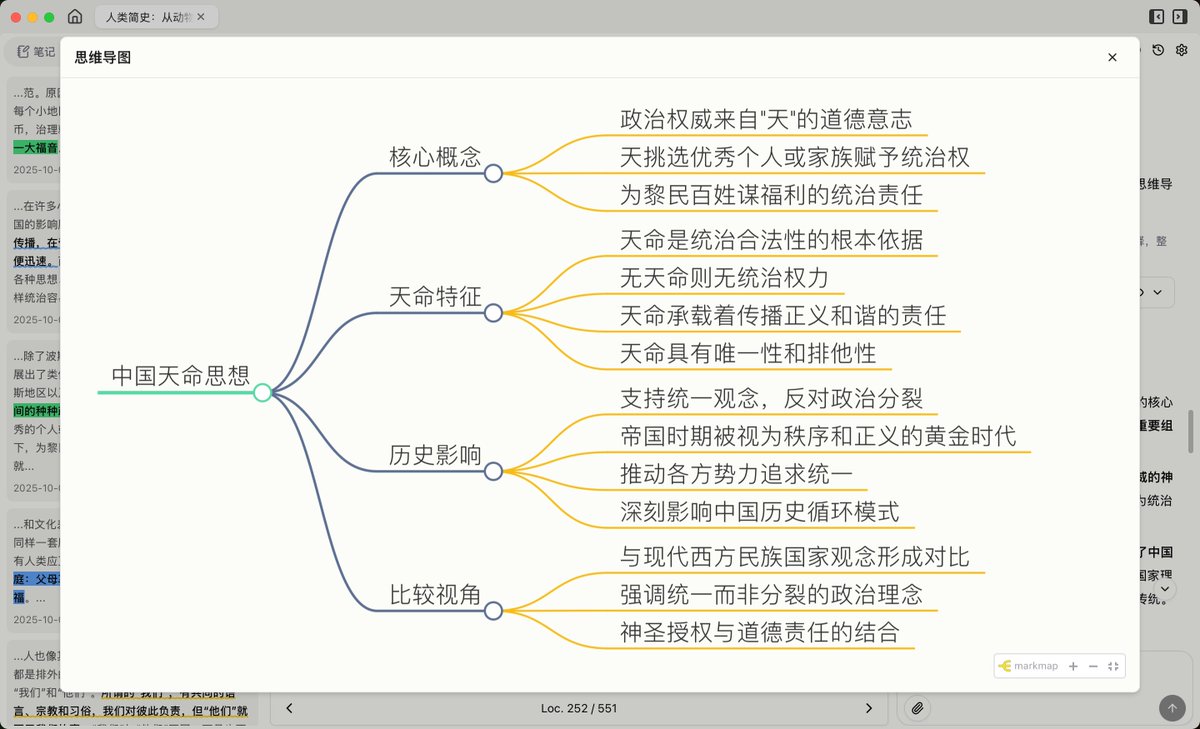



激动人心的时刻,我的个人开源项目 CC Switch 在第一个正式版发布一个月零三天后,突破了 1000 GitHub Stars!
CC Switch 不仅仅是我的第一个正经的开源项目,更是一次对个人方法论的验证,即在AI辅助下,一个普通的开发者能否快速掌握一个全新的领域(比如 Rust 和 Tauri)并构建出实用的应用。
当初选择 Tauri2 重构,一方面是因为 Electron 对于一个小型工具软件过于笨重,另一方面是看多了推上对 Tauri 的吐槽,准备挑战一下自我,不得不说过程是曲折且激动人心的。
感谢每一位用户的支持!我将继续维护并开发新功能(比如国际化、MCP 管理、本地代理功能),让 CC Switch 变得更加方便好用。
另外有时间的话会写几篇文章总结一下开发和重构过程中踩过的坑和收获的经验。
如果你有给 Claude Code 和 Codex 换模型,或者在不同的供应商之间切换的需求,可以试试 CC Switch,欢迎 issue 和 pr!
github.com/farion1231/cc-…
中文