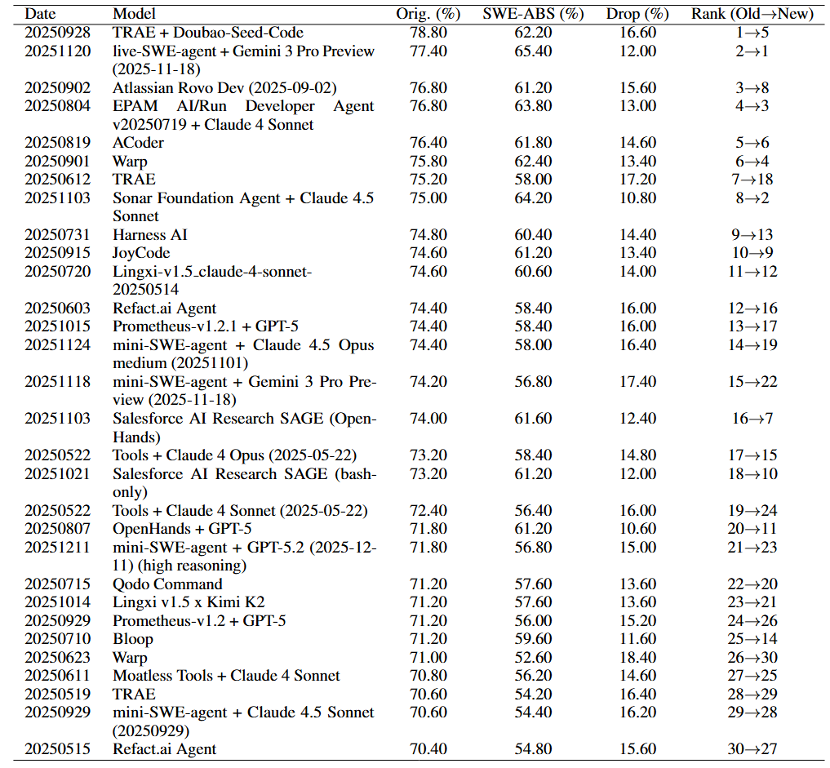
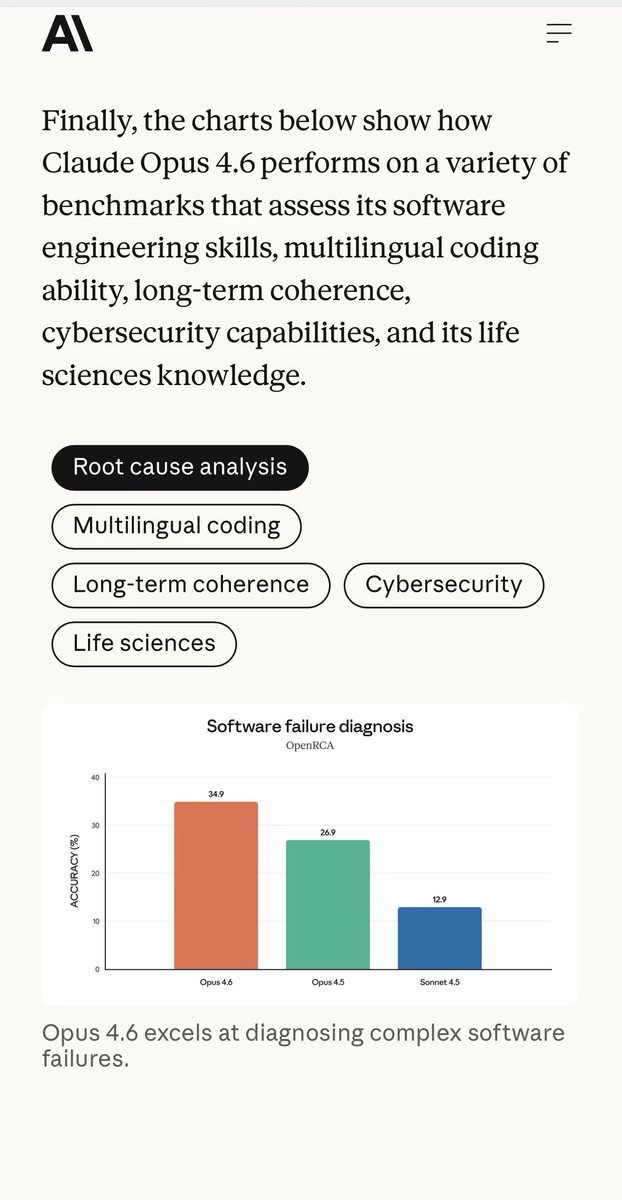
Sabitlenmiş Tweet

📢 Can LLMs locate software service failures? 🤔
My student @SiyuexiH's #ICLR2025 paper introduces OpenRCA, the first benchmark dataset for evaluating LLMs' root cause analysis capabilities in software systems. LLMs/Agents need to analyze system telemetry data to infer results for natural language queries. Experiments show current LLMs struggle with OpenRCA tasks without specialized RCA tools. Joint work with Microsoft and Tsinghua University.
🔗 Learn more:
📜 Paper: openreview.net/pdf?id=M4qNIzQ…
💻 Code: github.com/microsoft/Open…
📊 Leaderboard: microsoft.github.io/OpenRCA/
#iclr2025 #AI4SE #LLM #rootcauseanalysis

English