fin@fi56622380
回顾2025年半导体市场,真的是有太多太多精彩的故事,最大的主题就是:
AI需求驱动导致半导体基建的估值体系重构 + 产业链的价值分配重写
从2024年开始,半导体基建正在飞速吞噬整个IT产业利润,SP500里半导体净利润EPS在IT行业里占比,在两年时间从不到20%上升了到了40%,而且还在呈加速上升姿态
半导体整体前瞻利润率从2023年的25%已经升到了2025年11月的43%,已经明显超过了几个互联网巨头的平均利润率,这也印证了半导体利润率超过互联网会是新常态。整个IT产业的利润分配,流向半导体的比例越来越大。
要知道,就算是20~22年的半导体芯片荒,短缺如此严重,半导体的利润率和整个IT利润分配也没有显著增长
这就是故事的上半篇:AI需求驱动导致半导体基建的估值体系重构,不再是互联网时期的基建从属地位
------------------------
这个现象背后的逻辑是商业模式随着技术特性的变迁:
互联网时代,每次请求的网络和算力成本,边际成本极低,scaling的效果极好,分发的边际成本几乎为零
在AI时代,这个互联网时代分发边际成本几乎为零利于scalable的特性遭遇了根本性的重大挑战:且不说训练成本从此不是一次性开销而是年年增长,就客户的AI推理请求而言,由于inference scaling成为共识,加上垂直领域仍然需要更大规模的旗舰模型来保持竞争力,推理的成本不会随着硬件算力价格的通缩而同步降低
互联网企业从前的最大成本只有OPEX尤其是SDE人工成本,而现在,互联网公司历史上第一次像半导体厂foundry那样背上高折旧成本的资产负债表,商业模型恨不得要慢慢从“流量 × 转化率”部分转向“每 token 毛利”了
简单的说,互联网时代到AI时代的成本分布,在人力成本opex的基础上又加上了沉重的硬件/算力成本capex(财报里占比:MSFT 33%, Meta 38%)。
上个时代的互联网公司+CSP+SAAS是收租行业里的大赢家,而AI时代,算力(半导体/芯片折旧)成为了新的收租行业,整个IT行业的利润分布发生了剧烈的重新分配(EPS利润流向半导体从20%升到40%而且持续攀升中),这就是半导体基建估值体系重构最重要的原因
---------------
半导体高利润率的新常态趋势能持续多久?
目前的高溢价来自于前期不计成本的军备竞赛造成的半导体订单积压过多
但很显然,hyperscalers都不愿意当冤大头,都在试图自建ASIC降低成本,那么可以从2030年远期的算力分布来回看这个问题
长线来看,openai已经明牌了标准答案,10GW Nvidia,10GW ASIC,6GW AMD,其他hyperscaler划分比例有类似考虑
比如说,推理端希望ASIC >50%,GPU里再细分的话,AMD和NV(legacy)对半分。训练还是得NV占大头,60%+,剩下的自研ASIC和AMD对半分
2030年按60%推理,40%训练比例划分,算下来NV 38%, ASIC 39%, AMD 23%,跟openAI比例是几乎完全一致的,算是一个标准答案参考值
当然了,微软,Amazon,Google,Anthropic这几家里AMD的比例会比这个标准答案中枢/参考值明显低一些,xAI则是没有ASIC只有Nvidia+少量AMD
AMD的风险在于,当2030年再往后的更长期,CSP的in house ASIC越来越成熟(微软除外),推理端ASIC占比可能越来越高,很难有incentive新买入大量GPU了,除非卖的足够便宜
最近风头正劲的TPU呢?Meta是不是要转向TPU?对Nvidia的利润率影响大吗?
实际上,Meta今年capex72B,明年capex110B,未来六年capex平均值可能达到160B附近,而Meta 6年10B的TPU订单算下来年均只有1.6B,而且购买的是TPU云服务,并不是裸TPU
也就是说,Meta这笔TPU订单只占到Meta未来6年capex的1%,并没有严肃的考虑大规模部署,可能只是作为和Nvidia讨价还价的手段而已
另外从Meta最近几个月的招聘广告来看,也并没有看到任何TPU engineer方面的招聘,不像
Anthropic那样从五月就招一堆TPU kernel engineer,十月才宣布大规模采购TPU做训练
所以说,不管原因是diversify供货商,还是给自研ASIC延迟做退路,还是因为AMD的MI350X延迟,Meta买TPU基本上只有一个考虑:增加买Nvidia GPU的议价权,但顶多只有推理份额里能讨价还价,实际效果很有限,对Nvidia利润率影响也很有限。
要知道,22年加密货币熊市矿难的时候,NVDA库存上升到了198天,利润率只是从65%回撤到了56%,算上PE/宏观双杀股价才从300变100,现在一直供不应求,利润率没道理能降下来
再加上TPU v8设计过于保守(没用HBM4),Kyber rack的Rubin方案会比TPU v8的TCO更好,到头来最后还是得继续依赖Nvidia,很难议价。只要Nvidia继续保持这样的大踏步前进,竞争对手其实要跟上还是不容易的。
总之,一方面,全产业链瓶颈,比如cowos扩张都很谨慎,供不应求的状态还能持续多年。
另一方面,AI变现的利润曲线和硬件投入曲线存在“时间错配”,应用端的增长曲线会落后几年,只要这个应用端和基建端的增长曲线的时间错位依旧存在,半导体在IT行业的利润分配就会一直占优势。
从OpenAI的到2030年的投入曲线来看,这个时间错位至少要持续到2030年附近。也就是说半导体行业的超级扩张期带来的在IT产业利润划分的主导地位,目前看至少能持续到2030年
而半导体高利润率可能会维持的更长远一些,因为从互联网时代一次性基建属性变成了现在的收租基建属性
---------------------------------------------------
AI 不是只养活了 GPU,而是在用算力预算把“能把电变成 token 的每一环”都抬了一轮,从内存,存储,互联,光纤,电力,储能…..等等
上半篇讲完了“半导体吞噬IT利润”,那么下半篇讲的就是“AI算力价值溢出效应(Spillover Effect)重塑半导体内部格局”:GPU算力增长 -> 内存/存储/互联/CPU瓶颈 -> 溢出效应 -> 结构性机会
2025 年更有趣的故事,是巨大的行业红利在半导体内部怎么诞生结构性新机会,比如说,一个super cluster需要几个数据中心互联,光纤互联的长度需要上百万mile这个级别,这就是新机会
半导体产业链的结构性趋势带来的新机会,最典型的例子就是内存(DRAM/HBM)和存储(SSD),HBM的需求增长太夸张,连带挤压DDR4/5产能,直接让以周期性为标志的内存行业甚至喊出了“周期不存在”了,Hynix因为在HBM上领先,甚至都开始憧憬起了几年后年利润1000亿美元,妥妥一个万亿市值的公司
这两个板块背后,是结构性趋势的转变:AI workload从训练逐渐往推理延申,推理比例越来越大。
而推理是一个非常纯粹的吃内存带宽速度(memory bound)的事情,可以说带宽速度=token/s。模型尺寸越来越大,以及上下文context length的增加,对内存的尺寸要求也相应增大,导致了内存的需求激增:推理即内存
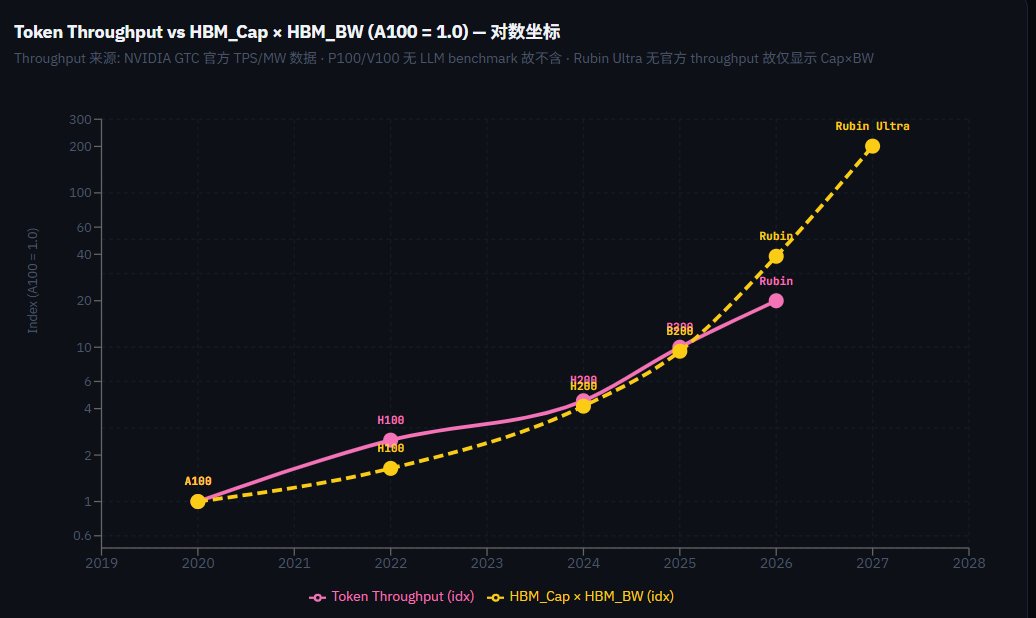
下一代的的GPU/ASIC内存已经成了暴力美学,配备的内存size之巨大,是三年前无法想象的,回看22年H100的80GB简直像个玩具,这才几年就增长了十倍:
Nvidia Ultra Rubin - 1024GB HBM
Qualcomm AI200 - 768GB LPDDR
AMD MI400x - 432GB HBM
内存的另外一个潜在的爆发点在端侧,也就是手机/PC/汽车/机器人的端侧LLM,这两年主流的手机旗舰机已经从6GB升级到了8GB/12GB/16GB,提前为可能的端侧LLM生态做准备,毕竟手机算力下一代就能达到150TOPS量级,妥妥的桌面级,非常暴力
潜力上来说,端侧内存升级是比云端内存增量要更大的市场,毕竟端侧终端device的数量太惊人了,每年都是billion级别,一旦端侧LLM生态繁荣起来,内存用量翻倍轻而易举,针对端侧低功耗内存/存算一体的各种设计都会跟上
但端侧genAI的软件生态,似乎明显滞后,一直比我想象的进度要慢,可能是因为这方面还处于摸索期,并没有云端那么确定的ROI,厂商们在投入上都很谨慎,我在23~24年时候看好27年,可能还是太乐观了
互联网->移动互联网用了10~15年,端侧genAI/LLM可能也需要7~10年,可能得等云端ROI开发的差不多了,边际收益下降了,才能轮得到端侧genAI/LLM拿到开发资源,跑通端侧ROI。
--------------------------------------
另一个2025年半导体内部结构性转变的故事是NAND存储,特别是企业级eSSD硬盘
结构性趋势来源也是同一个,AI workload的推理需求越来越大。内存红利也外溢到了SSD存储,甚至HDD存储,因为内存不够用就用高速SSD作为多级缓存
主要逻辑是AI推理过程中内存溢出KV cache offloading到下一层SSD存储,以及向量数据库检索/indexing,都在增加SSD存储的需求
Micron财报说的精准又直白:“AI inference use cases such as KV cache tiering and vector database search and indexing, are driving demand for performance storage.”
至于为什么存储价格在第四季度才爆发,这需要区分一下合约价格和现货价格,合约价格涨幅会温和一些,就算是最紧缺的企业级eSSD合约Q4上涨大概25%。而当NAND产能在2025年被合约慢慢的吃光,现货的价格就造成了观感上强烈的冲击,一个月上涨50%以上。
另一个未经验证的逻辑是多模态的爆发,特别是AI图片和AI视频的需求爆发,也会加剧存储的短缺,我觉得这条线只能说未来可期,但目前的视频/图片精细程度,可能还不到当年GPT3的水平,要达到出圈效果还需要一些时日。
------------------------
那么下一步还有什么趋势转移带来的半导体结构性的机会呢
那么就要先看下一步AI推理端的需求趋势是什么,毫无疑问,agentic flow的比例会越来越大,2025并不是year of agent,而是一个decade of agent
从CPU视角去看agentic workload,routing和工具处理都在CPU上,如果把常用的agentic框架做profiling,比如SWE-Agent, LangChain, Toolformer,CPU最长可以占到90%的E2E端到端延迟,throughput瓶颈也更多的卡在CPU,甚至CPU能耗也超过了总能耗的40%
Agentic AI目前是一个CPU瓶颈更多的事情,在 agentic 框架里,CPU 是永远在忙的总指挥orchestrator, 很可能会成就CPU需求的新一波回暖
AMD 2025年Q2财报(8月5日),Lisa Su明确表述了这一现象:"In particular, adoption of agentic AI is creating additional demand for general-purpose compute infrastructure, as customers quickly realize that each token generated by a GPU triggers multiple CPU-intensive tasks."
"agent AI的采用正在对通用计算基础架构产生额外的需求,因为客户很快就意识到GPU产生的每个令牌都会触发多个CPU密集型任务。"
Q3 财报里Lisa又明牌了一次CPU TAM increasing due to Gen AI. "Many customers are now planning substantially larger CPU build outs over the coming quarters to support increased demands from AI, serving as a powerful new catalyst for our server business."
Nvidia也是把agent flow视为CPU需求,GB200/300 架构配置的CPU比例也比以往大的多,36颗 Grace CPU : 72颗 Blackwell GPU,直接达到了1:2的水平,AMD的路线则是用1~4个256核的EPYC去服务MI400系列72~128个GPU
以后的硬件架构,一定会往优化agent workload方向发展,比如agent task graph的调度和load balancing,CPU/GPU协同micro-batching
算力上的比较,说不定以后也会摆脱现在的纯GPU token rate比较,转向整个系统级全栈agentic benchmark比较.
--------------------------
半导体结构性转变带来的机会同时,下一步,可能也会带来一些意想不到的次生效应
云端AI数据中心需求爆发,造成内存和存储的暴涨,给消费电子的成本带来了很大压力,在2026年,这也许会演变成消费电子产业潜在的黑天鹅
PC厂商最近的股票大跌,也是这个原因。HP已经说了要减少内存配置,暗示要把PC重回8GB内存+256GB存储的时代了。
DRAM内存和存储再这么涨下去,可能会出现很离谱的情况:内存/存储现货价格比CPU和GPU还要更贵。尴尬的是,这可能直接延缓了消费电子期望的AI PC的进程,毕竟大内存是更有利AI PC的表现力的。
夸张的说,每个PC厂商和手机厂商的员工,甚至是消费电子厂商的员工,都应该买入存储和内存,作为职业风险对冲
明年年初开始,安卓阵营的内存以及存储成本要压不住了,三星,小米的手机售价都提高的话(美国市场现在已经提高不少了),利好最大的就是苹果
苹果的内存产能,nand产能都是专属长约锁价特供的,顺带还把Kioxia给坑了好多不涨价产能,导致苹果的成本优势进一步扩大,苹果全球手机销量市占率增长可能会非常可观,接下来一阵子可能会是iphone辉煌的时光。
-----------------------
2025年半导体市场真的是太多精彩的故事了,Nvidia/AMD/TPU和各家hyperscaler的恩怨情仇引得各路下注的吃瓜群众心情跌宕起伏。
HBM/内存厂商吃到了memory-bound的红利,NAND厂商意外收获了KV cache的溢出效应,CPU在沉寂近十年后,可能会因agent orchestration再次回到增长叙事的中心
不再是Nvidia/AVGO几家算力厂商独大,而是AI workload算力价值溢出后的每一次演进,从训练到推理,从文本到多模态,从单模型调用到agentic flow,都在重写产业链的价值分配。
云端AI的繁荣正在挤压消费电子的生存空间——当PC厂商被迫讨论重回8GB时代,苹果却因供应链优势坐收渔利。这场算力军备竞赛的次生效应,可能在2026年以意想不到的方式重塑整个消费电子格局
半导体的故事不再是一条单线,而是一张持续自我重构的网。而 2025 年,大概只是合纵连横的第一回合