
rick awsb ($people, $people)
20.8K posts

rick awsb ($people, $people)
@rickawsb
瞎读书,乱解释,买啥亏啥,宏观小学生,政经评论外卖员,正在ai中慢慢迷失自我,crypto holder, defi farmer, not financial advice 非投资建议
no where Katılım Kasım 2017
12.3K Takip Edilen148.7K Takipçiler

openai 的显卡充足, infra 基建强啊,
这样全世界人民疯狂蹬codex额度,
我没卡过,
也还没在 timeline 上看到有人说卡顿,缓慢。
中文
英伟达也认为存储是比gpu更大的瓶颈
— nvda最新文章解读
NVIDIA 最新发布的《AI Model Co-Design》是一篇介绍 TensorRT-LLM 和 Blackwell 的技术文章,
但也是一份未来几年大模型设计和 AI 基础设施的发展路线图。
文章真正讨论的是如何让模型从设计之初就适应 GPU。这意味着 AI 已经进入了一个新的阶段:模型开始围绕硬件设计,而不是硬件围绕模型优化。
过去大模型竞争的重点一直是 Accuracy,但本文开篇便将 AI 的目标重新定义为 Accuracy、Throughput 和 Interactivity 三者的平衡。准确率已经不再是唯一决定因素,更大的商业价值来自单位时间产生更多 Token,以及更低的响应延迟。整篇文章几乎完全围绕推理(Inference)展开,而很少讨论训练,这本身就是 NVIDIA 对未来市场重心的判断。
理解全文的关键是 Roofline Model:任何程序最终都会受到两个瓶颈中的一个限制,要么是 Compute,要么是 Memory。
决定程序属于哪一种的是每搬运一个 Byte 数据,GPU 能完成多少计算:算术强度高,程序受 Compute 限制;算术强度低,程序受 Memory 限制。
"Latency-sensitive decoding runs at low concurrency and is memory-bound."
推理为什么天然容易 Memory-bound?原因在于推理分成两个完全不同的阶段。Prefill 处理整个 Prompt,可以一次计算成千上万个 Token,大矩阵带来很高的 Weight Reuse,因此通常属于 Compute-bound。而 Decode 必须逐 Token 生成,下一个 Token 必须等待上一个 Token,天然无法沿时间维度并行,只能依赖不同用户之间的 Batch。随着 Batch 变小,每次生成一个 Token 仍然需要读取几乎完整的模型权重,Weight Reuse 急剧下降,GPU 更多时间花在等待数据,而不是计算。
文章用 FFN 举了一个典型例子。FFN 的 GEMM 可以写成 M×K 乘以 K×N,其中 M 对应 Token 数,N 和 K 对应模型维度。推理过程中,M 会随着并发下降迅速缩小,而 N 和 K 基本保持不变。这意味着真正的计算量下降了,但需要读取的 N×K 权重矩阵几乎没有减少。文章因此得出结论:"FFN latency becomes memory-bound because the GEMM-N and GEMM-K dimensions remain large as GEMM-M shrinks." 换句话说,GPU 已经不是在等待计算完成,而是在等待 Weight Read。
这也是为什么文章不断强调 Memory,而几乎没有讨论 FLOPS。Roofline(天花板) 一节最有代表性的三句话分别是:"Workloads with low arithmetic intensity are capped by memory bandwidth."、"Latency-sensitive decoding is memory-bound."、"Memory time exceeds math time at every token count."
三句话实际上表达的是同一个意思:对于现代推理而言,真正限制系统性能的已经不是 GPU 算力,而是 Memory 带宽和 Weight Read。
MoE 可以缓解这个问题,但无法彻底解决。MoE 将 Dense 模型每层全部计算变成只激活少数 Expert,大幅降低 Compute。然而 Compute 降低的同时,新的瓶颈开始出现。首先是 Expert Parallel 带来的 All-to-All 通信,其次是 Router 带来的负载均衡问题,最后是 Weight Read 本身仍然存在。每个 Expert 依然需要读取大量参数,因此 MoE 更多是把瓶颈从 Compute 转移到了 Memory 与 Communication,而不是消灭瓶颈。
这也是 NVIDIA 为什么重点介绍 Wide Expert Parallel。因为nvda希望将 Expert 分布到更多 GPU 上,可以提高整个系统的 Aggregate Memory Bandwidth,同时降低每张 GPU 保存的 Expert 数量,从而减少 Weight Read 带来的延迟。
注意,这里的收益并不是来自更多 FLOPS,而是来自更多 Memory Bandwidth。这也是文章第一次明确把 GPU 扩展解释为 Memory 扩展,而不是 Compute 扩展。
nvda25年发布的Helix Parallel 则解决了另一类 Memory 问题——KV Cache。传统 Tensor Parallel 在 GPU 数量超过 KV Head 数之后,不得不复制整份 KV Cache,导致 HBM 占用迅速增加。Helix 将 KV Cache 按 Sequence 切分,而不是按 Head 切分,每张 GPU 只保存部分 KV Cache,再在 Attention 阶段交换 Sequence,随后切换回 TP×EP 完成 FFN。这意味着 Attention 和 FFN 不再采用同一种并行策略,而是各自选择最优方案。随着 Long Context 从几万 Token 增长到百万 Token,Helix 的价值会越来越大。
整篇文章提出了七条设计原则,但本质上都围绕同一个目标。Near-square Matrix 提高 Arithmetic Intensity;128、256、512 对齐提高 Tensor Core 利用率;Prefer Width over Depth 增加 Weight Reuse;NVFP4 减少 Memory Traffic;Wide EP 提高 Aggregate Memory Bandwidth;Chunked Pipeline 减少 Pipeline Bubble;Helix 将 Attention 与 FFN 解耦,分别采用不同 Parallel Strategy。看似是七条独立建议,本质都是围绕 Roofline Model,目标只有一个:减少 Data Movement,提高 GPU 利用率。
真正值得关注的反而是文章没有直接说出来的内容。第一,GPU Compute 的增长已经快于模型真正需要的 Compute,未来继续增加 FLOPS 的边际收益正在下降。第二,推理时代的瓶颈已经从 Compute 转向 Memory,HBM、KV Cache、Weight Read 和 Memory Traffic 将越来越重要。第三,GPU 的竞争开始演变成整个系统的竞争,包括 HBM、NVLink、TensorRT、并行策略和软件栈,而不仅仅是单颗 GPU 的性能。第四,AI 基础设施未来真正需要优化的对象,不再是计算,而是 Data Movement。
总结来说就是:在越来越多的 AI 推理场景中,存储(准确地说是 Memory、Memory Bandwidth、Weight Read 和 Data Movement)已经比 GPU 算力更容易成为系统瓶颈。
作者背景:这篇文章的七位作者几乎全部来自 GPU Architecture、TensorRT-LLM、Distributed Inference、Model-Hardware Co-design 和 Compute Architecture 团队。

NVIDIA AI@NVIDIAAI
As AI models continue to grow in scale and capability, shaping a model matters just as much as its size. We're introducing a new series on AI Model Co-Design exploring the synergy between models and hardware. The first post focuses on how model dimensions influence GPU performance, and how the right design choices improve both system throughput and per-user responsiveness. You can read it here: nvda.ws/452Idiy
中文
rick awsb ($people, $people) retweetledi

rick awsb ($people, $people) retweetledi

🔴 今晚直播|为什么 Crypto 需要 AI?
AI 正在重新定义软件,而 Crypto 正在重新定义价值网络。当两者相遇,会创造怎样的新机会?
今晚,Bay AI Circle 邀请到 @ChandlerGuo 做客,与你一起畅聊:
🔹 AI 与 Crypto 的真正交汇点
🔹 AI Agent 与 Web3 的未来
🔹 AI Native Crypto Ecosystem 的新机遇
🔹 创业者现在应该如何布局
📅 今天 8:00 PM (PT)
👇 点击下方链接,预约提醒(Set Reminder),直播开始第一时间加入!
x.com/i/spaces/1RJjp…
#AI #Crypto #Web3 #AIAgents #BayAICircle
中文

因为神经网络的可塑性更强,未来总是属于年轻人的,现场感受到那种蓬勃向上的生命力真的很强,这是一种能打破文明进程中遍历性破缺的力量。
🐹_Leslie鼠鼠@LeslieLi92210
很荣幸! 今天晚上能在深圳和十二位朋友见面 由TC组局的饭局(感谢tc姐我们才能吃上洪大厨)@TC8880 希望大家可以多多支持predict.fun !! 带着我们00后大军蹭了顿饭 熟悉的天策 meme 小芦 牛肉粉 猴子 樱花 howe 见到了很久不见的子时哥 Ray 老齐 wise 今天真的很疲惫,但和大家相处的过程还是蛮放松,也学到了很多! 嗯…..收获满满的一天 @silverfang88 @Leobai825 @TC8880 @beefnoode @web3houzi @Web3Dc888 @WiseInvest513 @luyisikai @0xsakura666 @Ray80230 @0xcryptoHowe @oooodjdjd
中文


@orstep3oxj @xueyuanjoey 请问:DUV做7nm 5nm是如何做到良率稳定价格不高2倍4倍的?
这是一个物理/数学问题,我每次问,很多爱国者都当政治语文题回答
中文
华虹证明了:中国晶圆厂只要不跟着任教主“邪修”多次曝光,还是经营不错的
但同样成熟制成华虹PB已经显著高于GFS STM等等了(技术不如)
期待⚡️订单溢出,下半年让老登晶圆厂全部重定价
Macro_Lin|市场观察@LinQingV
据传三星把4nm、5nm和车用8nm对新客户的报价上调15%,4nm产能连明年的都已排满。一个常年报价比台积电低两三成的价格竞争者开始挑单,代工市场的买方卖方已经易位。中芯华虹的成熟制程提价大概率延续到2027年,订单外溢已经落到报表上,华虹一季度净利润同比增长513%,12英寸投片持续超过设计产能。关键是,消费电子和汽车客户的利润还承受得起几轮涨价。
中文


ai带来的加速是前所未有的,各行各业都将面临巨大的重构
对于长期持有价值投资者来说,只有数学的必然和物理的极限,才可能是真正的湖城河
其他的一切,都可能被颠覆
中文

This is a key reason I don’t expect the flow of frontier open weights models to continue indefinitely, or even for very much longer. reuters.com/world/beijing-…
English
有人把ai比做电力革命,这是对硅基文明的侮辱
爱迪生开启了电力革命
而ai正在批量生产爱迪生,
批量生产爱因斯坦,甚至是批量生产远超爱因斯坦能力的人。
ai正在生产数据中心里的天才国度

中文

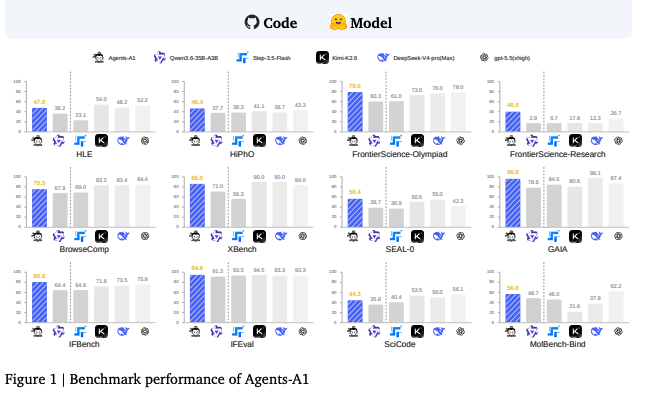
Agent Horizon Scaling:参数不足运行(时间)补?
过去几个月,越来越多的工程优化让小模型能力不断逼近前沿模型,至少是前沿开源模型。
上海 AI Lab 的 《Scaling the Horizon, Not the Parameters》 最新论文把这点又推进到了新的高度:通过Horizon Scaling(扩大 Agent 的工作跨度),论文证明了,在特定任务上35B 可以打败 1T参数模型,
更重要的是,很多复杂任务的能力,并不一定来自更大的模型,而可以来自更长的执行过程。
因此,论文认为,gent 的能力开始变成:
基础模型能力 × Runtime Compute × Horizon。
论文将大量必须存放在 HBM 中的知识,开始放到:
Internet
SSD
Database
Browser
Tool
模型需要的时候再去获取。
从系统架构来看,这其实就是一种新的 Memory Hierarchy。
过去:
HBM → Forward → Answer
未来:
HBM → Search → Tool → Verifier → Reflection → Answer
知识开始从 HBM 外迁,HBM 越来越像 CPU Cache,Internet 越来越像 Hard Disk,模型越来越像 CPU。
这一方面是在"用 DRAM 和 SSD 补 HBM",另一方面更是在用 Runtime Compute 补 HBM。
大参数大模型需要几十 GB 参数记住 API、论文、网页、代码,使用论文的方法可以搜索 → 阅读 → 理解 → 验证。知识不用提前存进去,而是在运行时动态计算出来。
这其实和计算机体系结构的发展规律完全一致:CPU 有 Cache、DRAM、SSD 分层,用更多访问时间换更大的存储容量。
Agent 也是一样。论文把经典的 Time-Space Tradeoff 引入了 AI 系统。
不过,需要强调的是,论文的方法替代的是模型的知识(Knowledge),不是能力(Capability)。
模型参数里面其实有两种东西。
第一种是知识,例如 API、论文、GitHub、新闻、数据库。这些越来越可以运行时获取。
第二种是能力,例如推理、规划、世界模型、抽象思维。这些目前仍然主要来自更大的基础模型。
因此,Agent 并没有否定 Parameter Scaling,而是在放大缩放定律:
基础模型越强,每一次搜索、每一次规划、每一次代码修改都会更准确,整个 Agent 的能力也会随之提升。
Agent = Foundation Model × Runtime Compute × Horizon × External Memory。
这就是 Rich Sutton 的《The Bitter Lesson》的另一种路径实践。过去:Parameter Scaling。未来:Parameter Scaling + Horizon Scaling。
中文
@emollick By the time exponential growth becomes the dominant investment narrative, the economy is likely nearing the top of the current cycle.
English
AI implementation advice on my X feed is divided between those who "feel the exponential" and those whose (unconscious?) mental model of AI is that this is about as good as it is going to get, so it is time to build around the limitations & cost structures of today's capabilities
English
