Sabitlenmiş Tweet

Oh my gosh $80000 for a bitcoin you guys. Where is this going to peak?
ral.eth 🔰@RaleighC
Oh my gosh $290 for a bitcoin you guys. Where is this going to peak?
English
ral.eth 🔰
25.1K posts

@RaleighC
Founder at https://t.co/lWmBGnsOPN \ Proximus Ordo Seclorum / \ Inventor entrepreneur / \ https://t.co/8h6ug80ouW / \ hodl #Bitcoin /
Oh my gosh $290 for a bitcoin you guys. Where is this going to peak?


Age verification, Lobbying and Dark Money will push Age Verification and thus, Digital ID further than any of us can imagine.



Jensen Huang is loving the new Dell Pro Max with GB300 at NVIDIA GTC.💙 They asked me to sign it, but I already did 😉


Fun fact: The trailer releases for Dune 1 & 2 both happened at the bottom of bear markets. Bitcoin went on to have bull runs that led to new all time highs and lasted for years each time. The trailer for Dune 3 released today. Run it back turbo.




I am an ex-Palantir executive, and it is factually correct that @PalantirTech intended to take over the US government while heavily funding the effort. Many of my ex-colleagues are now installed inside the USG apparatus. There is a reason the C-suite of $PLTR has me blocked. The enemy is within, and we are currently an occupied nation. 🇺🇸 We basically have a terrorist entity deeply embedding itself into the USG.

@peterktodd @xkcd Not that I trust Gemini, or any other AI, but this is a faster and more thorough cross-check than I ever could have done before in history. And I did not, in fact, give it the Lean proof.

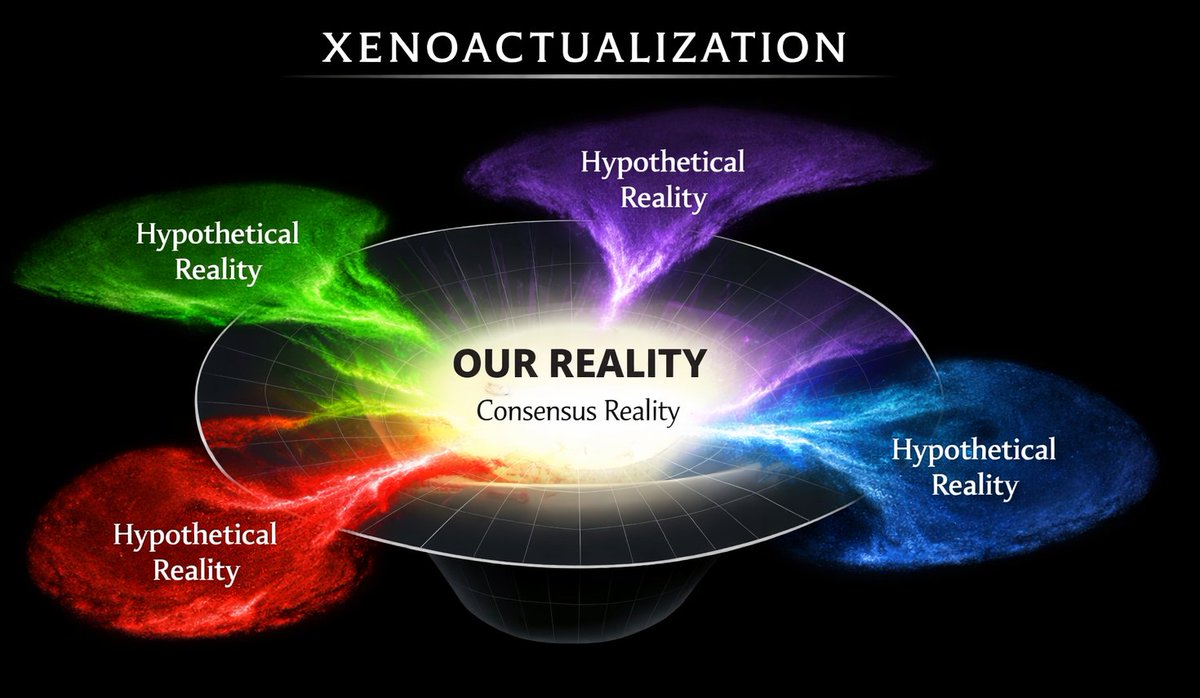
@L_emiLLLL Salvation from the Outside.
ethereum has become a milady derivative LMFAO
Damn, they actually passed it? Unlicensed operation of 3D printers and CNCs is now a felony in Washington? I get that it's fashionable to hate manufacturing in some places but how many kids and FIRST robotics teams are going to end up with criminal records because of this?





This is wild. theaustralian.com.au/business/techn…



