
GeekyRam
212 posts

GeekyRam
@Ramvikas007
GPU Nerd | RL for agents | open for collaborations | contributing OSS | building on stealth
San Francisco Katılım Nisan 2017
476 Takip Edilen54 Takipçiler

i just beat @GoogleDeepMind's turboquant
introducing Shard. 10x KV cache compression on Llama-3.1-8B. zero quality loss
- 10x @ 8K context, 11.2x @ 32K
- NIAH recall 1.000 across 4K-32K
- LongBench Δ ≈ 0 vs FP16
turboquant tops out at 4-6x at the same quality. we doubled it.
read more: krishgarg.com/shard
@kirrithan
English

Going to the YC Voice Agents hackathon this weekend. Have an idea and looking for a teammate who tokenmaxes. HMU if interested.
English

We’re scaling rapidly and hiring for full-time roles in SF.
This is a rare chance to work directly with me and an incredible team to build the future of enterprise AI.
Our belief is that every company will eventually run on private, custom AI tailored to its workflows.
The challenge is that building high-quality custom systems today still looks too much like consulting. Our vision is to scale services with software margins.
We’re building the infrastructure to make that possible, and we need exceptional people to do it.
We’re looking for someone who:
- learns extremely fast
- is passionate about their work and takes ownership
- loves talking to customers and naturally builds strong relationships
I don’t care what your y-intercept is, only your slope.
DM me if interested.
English

@Ramvikas007 Hey! @Ramvikas007 would love to connect and know more about what you are working on these days!
English
I want to connect with AI/ML researchers in SF working on problems that matter!
Would love to meet them and talk about their current workflows.
Please tag them
English

Memorial Day weekend traveling 🤍
API keys coming SO soon!!!!
@opheliaapi got more requests than expected…thanks for believing in our thesis :)
dm me if u want to try!



English

@Ramvikas007 Ask Grok is currently available to Premium and Premium+ subscribers only. Subscribe to unlock this feature: x.com/i/premium_sign…
English


@GenAI_is_real I love this blog with complete analysis and debugging!
Last month, I published a blog on profiling fish-s2-pro and mentioned it, didn’t get the time to debug much and raise PR. This was unexpected find for me.
open.substack.com/pub/ramshankar…
English

When SGLang OOMs, What Exactly Runs Out of Memory?
Around two months into fully developing SGLang Omni, roughly this April, we got a brand-new H100 on top of the H200 development machine and the H20 CI machine we already had. That meant one more machine could join community development. Naturally, getting a new machine was exciting, so we quickly put the H100 into production to work on #280.
PR 280 itself was very simple. It looked like it touched close to 2,000 lines, but the logic was not complicated. In short, we previously had one script for benchmarking Omni Model Voice Clone performance on the SeedTTS dataset, and another script for testing Omni Model Voice Clone correctness. Obviously, these two scripts could be merged: while measuring correctness, we could naturally measure performance as well. PR 280 was exactly that merge. Without a doubt, this task was very clear, and AI could absolutely handle it perfectly. So Hao Jin (AAA Google Tennis Coach Jin) quickly finished 280 itself, then started testing the newly merged script.
This is where a very serious problem appeared. Coach Jin measured Qwen3 Omni TTS WER on the full set with the merged script, and the score was actually above 3.0. Note that WER is a lower-is-better metric, so this immediately put us on high alert. We started analyzing what could have caused such a large correctness regression. Before #280, we had already built what looked like a CI system armed to the teeth: Qwen3 Omni validated a 50-sample SeedTTS subset on every commit, making sure there was no performance or correctness regression at all. So when the new script showed a significant performance loss, we immediately had a few unpleasant guesses:
Our CI was fake; some earlier PR had already broken Qwen3 Omni accuracy, but CI failed to catch it.
Our benchmark was wrong; maybe we made a mistake while merging the two benchmark scripts into one.
Then we discussed this issue in the SGLang Omni development group and realized it might not be as troublesome as we first thought. In the story above, I mentioned the machine migration almost casually. Before PR 280, we had always used the H200 as the development machine. By PR 280, we had switched to the H100. At first, I did not think much of it, but in fact this was exactly where the problem was. I remember that the first time Coach Jin told me he was validating 280, he mentioned that the old script for launching the server could no longer start the server. This confused me quite a bit. It was a weekend, and while running in Mountain View, I kept wondering, "What on earth is going on?" Then he debugged it with Claude, raised SGLang Omni's Qwen3 Omni mem_fraction_static to 0.8, and only then did the server start successfully.
Looking back now, that was actually the problem itself. I assumed migrating from H200 to H100 would have no issue, and even when a performance regression appeared, I did not blame the H100. Only after chatting with the smart folks in the group did I realize that SGLang Omni's Thinker had previously hard coded mem_fraction_static to 0.7. As a result, an 80GB H100 could not start Qwen3 Omni's Thinker (30B MoE) at all, which then caused the performance regression above. Even after we raised mem_fraction_static to 0.8, the server could only barely start, and a considerable number of requests still failed due to memory pressure.
This short blog shares how we reasoned through and solved this issue. Specifically, we will discuss:
What the mem_fraction_static parameter actually does. When SGLang OOMs, what exactly runs out of memory?
Why, after setting mem_fraction_static to 0.8 on H100, the server could start but many requests still failed due to memory.
How we used SGLang's mem_fraction_static auto-tune mechanism to bring the H100 back to life.
Acknowledgements: thanks to Huapeng, Yifei, Ratish, Coach Jin, xuesong, and yifei.
What Does mem_fraction_static Actually Allocate?
The official SGLang description of this parameter is:
The fraction of the memory used for static allocation (model weights and KV cache memory pool). Use a smaller value if you see out-of-memory errors.
Let --mem-fraction-static = y. y means: before loading model weights, that is, after torch.distributed.init, SGLang measures the currently available GPU memory and splits it into two logical regions with ratio y : (1-y). The y part is used for model weights and the KV cache pool, while the (1-y) part is reserved for activations, CUDA graph buffers, and other dynamic overhead during inference.
There is one point here that is not quite aligned with the official documentation, but is directly related to the H100 pitfall we hit: the documentation broadly says that if you see OOM, you should "make y smaller." In our actual operation, however, we had to raise y from 0.7 to 0.8 just to barely start the server. In fact, when OOM appears, whether we should make y smaller or larger requires deeper consideration. To understand this, we first need to understand two startup variables in SGLang: pre_model_load_memory and post_model_load_memory.
Concretely, SGLang uses the same utility function get_available_gpu_memory to read currently available GPU memory: it first calls torch.cuda.empty_cache(), then uses torch.cuda.mem_get_info to read the current free memory and converts it to GB. In multi-card settings such as TP, it also takes the MIN across ranks, preventing one especially tight GPU from being "averaged away" by the others.
pre_model_load_memory: near the end of init_torch_distributed, distributed init has just finished, and load_model has not yet happened. The returned value is recorded as pre_model_load_memory. This is not the physical 80 GB of the H100, but "how much memory the driver thinks this GPU can still give me at this moment" after subtracting CUDA context, NCCL buffers, and memory occupied by other processes on the same GPU.
post_model_load_memory: inside _profile_available_bytes, the weights have already been loaded by load_model, LoRA-related preallocation has also been performed if applicable, but the KV pool has not yet been created. SGLang calls get_available_gpu_memory again, and records the result as post_model_load_memory.
Therefore, we can almost treat pre_model_load_memory - post_model_load_memory as the memory occupied by weights and LoRA-related preallocation. In some sense, we could calculate model weights directly from parameter count multiplied by data precision, but pre_model_load_memory - post_model_load_memory is actually more accurate. Based on this, we split pre_model_load_memory into two logical regions:
Static region (weights + KV + LoRA allocation etc.): y * pre_model_load_memory
Dynamic region (activations etc.): (1-y) * pre_model_load_memory
After subtracting the memory occupied by weights and LoRA-related preallocation from the static region, the remaining part is the memory available for KV:
memory_for_kv = y * pre_model_load_memory - (pre_model_load_memory - post_model_load_memory)
The corresponding source code is in model_runner_kv_cache_mixin.py:
def _profile_available_bytes(self, pre_model_load_memory: int) -> int:
post_model_load_memory = get_available_gpu_memory(...)
rest_memory = post_model_load_memory - pre_model_load_memory * (
1 - self.mem_fraction_static
)
...
return int(rest_memory * (1 << 30))
pool_configurator.py then converts this returned value (bytes) into max_total_num_tokens. If it is <= 0, it raises Not enough memory. Please try to increase --mem-fraction-static. This is exactly the startup failure we saw on H100.
With this discussion in place, we can further ask: when OOM appears, should we increase or decrease mem_fraction_static? In fact, there is no single standard answer, because different OOM causes imply different tuning directions.
Three Typical OOM Scenarios
Startup OOM (KV Cache Allocation Failure)
The server fails directly during startup, and rest_memory is negative. In other words, after the static region y x pre_model_load_memory subtracts weights, there is not even enough memory to allocate the KV pool. In this case, the fix is exactly the opposite of the official documentation's "make y smaller": we need to increase y.
Take H100 80 GB + Qwen3-Omni 60 GB as an example. Suppose init consumes around 2 GB, so pre ~= 78 GB:
mem_fraction_static = 0.7 (default)
pre ~= 78 GB
reserved = (1-y) * pre ~= 23.4 GB
post ~= 78 - 60 ~= 18 GB
memory_for_kv ~= -5.4 GB -> OOM
mem_fraction_static = 0.85
reserved ~= 11.7 GB
memory_for_kv ~= 6.3 GB -> KV Cache can be allocated
Note that the 78 GB above is only an estimate. pre_model_load_memory depends on the driver, CUDA context, NCCL/communication libraries, and memory occupied by other processes on the same GPU. If there are other services running on the same GPU (for example, a local training job or a monitoring daemon), pre_model_load_memory may directly fall to 70 GB or even lower, and increasing y may still not save it. This is the root cause of some cases where "the formula seems to leave enough memory, but startup still OOMs." The right solution in this scenario is to free memory on the same GPU first, then tune mem_fraction_static.
Runtime OOM Inside SGLang
The server starts, runs for a while, and then SGLang itself OOMs. This is actually a very interesting problem: SGLang itself does not OOM simply because KV cache is insufficient. When a request is too long and the KV cache cannot fit this giant request, SGLang's strategy is to retract that request, or in other words, put it back into the scheduler queue. After other requests' KV cache has been cleared out, it puts this request back into a batch. So SGLang does not OOM because KV Cache allocation is insufficient (y is small, but still large enough to fit weights). Therefore, if SGLang OOMs at runtime, there are only two possibilities:
Activation memory was not reserved enough, so activations directly blow up the current GPU during runtime. This is logically possible. As I said earlier, SGLang does not OOM because KV Cache was not allocated enough, but it can indeed OOM because activations were not given enough room. In this case, we should reduce y, leaving more memory for activations.
KV cache and activations are both friendly, but there are other processes on the GPU. For example, if you are a student, maybe a labmate is running a mysterious task with wildly fluctuating GPU memory on the same card, or you are running an RL workload where the training engine has severe memory fragmentation or leakage. In this case, logically speaking, we should strictly manage other processes. In practice, however, what we may be able to do is simply lower SGLang's mem static fraction, make it just enough to load weights, fit a smaller KV Cache, and pray that activations do not collide with other processes and blow up the server.
This is what the SGLang parameter documentation means by Use a smaller value if you see out-of-memory errors. So the documentation is right, but not entirely right. If startup fails because KV Cache allocation fails, we should increase y; if OOM happens at runtime, we should decrease y.
Multi-Modal Encoder OOM Error
Back to SGLang Omni, there was one more twist. As I mentioned earlier, after we raised Qwen3 Omni Thinker's Mem Fraction to 0.8, the server started successfully. But the SeedTTS WER measured with this parameter was still very high. Looking more carefully, we found that many requests failed due to OOM, but this was neither startup KV Cache allocation failure nor insufficient runtime activation memory. That was confusing. After tracing further, we discovered that the video encoder and audio encoder had not been allocated enough memory, causing some requests to never be sent to the Thinker at all. Naturally, WER looked terrible. For this, our current solution is not elegant: we temporarily use the encoder_mem_reserve parameter to reserve memory in advance for the video encoder and audio encoder. Of course, this should eventually be aligned with SGLang VLM's handling logic.
H200 vs H20 vs H100: The Last Step for Hopper Cards
This is the whole story. We had been developing on H200 for a long time, and the CI machine used a 96GB H20. Coincidentally, if thinker_mem_static was hard coded to 0.7, the memory left for KV cache was roughly 96 * 0.7 - 60 = 7.2 GB, which was just enough to run. Of course, we certainly no longer hard code thinker_mem_static to 0.7. Instead, we refer to SGLang and use an auto-tune mechanism to make each machine use as much memory as possible. On H100, SGLang Omni can now also run beautifully, but the memory left for the multi-modal encoder is still quite tight. Some long sequence video inputs can still trigger OOM. This is expected, and we will continue doing some optimizations, perhaps supporting FP8 or learning from SGLang's advanced memory management mechanism.
At this point, this short piece is basically done. May in Southern California is getting hotter by the day. I remember that around this time last year, I left school for an industry internship, decided in early June that I would leave academia, and then officially started full-time work in November 2025. Sometimes I think the industry really is very different, and startups even more so. Those famous people who once looked so prominent from school, when viewed again from an industrial perspective, also reveal many disappointments. In the end, it is hard to "defend the boundary between honor and disgrace, and settle the distinction between inner and outer things." As for me, in the half year since I started working, both my mindset and understanding have changed quite a lot. SGLang Omni is the first project after I began working full time. Although the process has had many twists and turns, I am grateful for the support and full effort from all my friends. A new journey begins here.
> Children would remember for the rest of their lives how their father sat solemnly at the head of the table, emaciated from long nights and deep thinking, trembling with excitement as he revealed his discovery to them: "The earth is round, like an orange."

English




Just attended @fdotinc ‘s canopy festival. Couldn’t visit all the startups. Met all the startups who are building on Sandbox or RL sandboxes.
The craziest part is meeting @FarzaTV ,
The one who founded @_buildspace


English
@SemiAnalysis_ @sailresearchco is building persistent CPU sandboxes for long horizon tasks, Worth checking out
sailresearch.com/news/introduci…
English

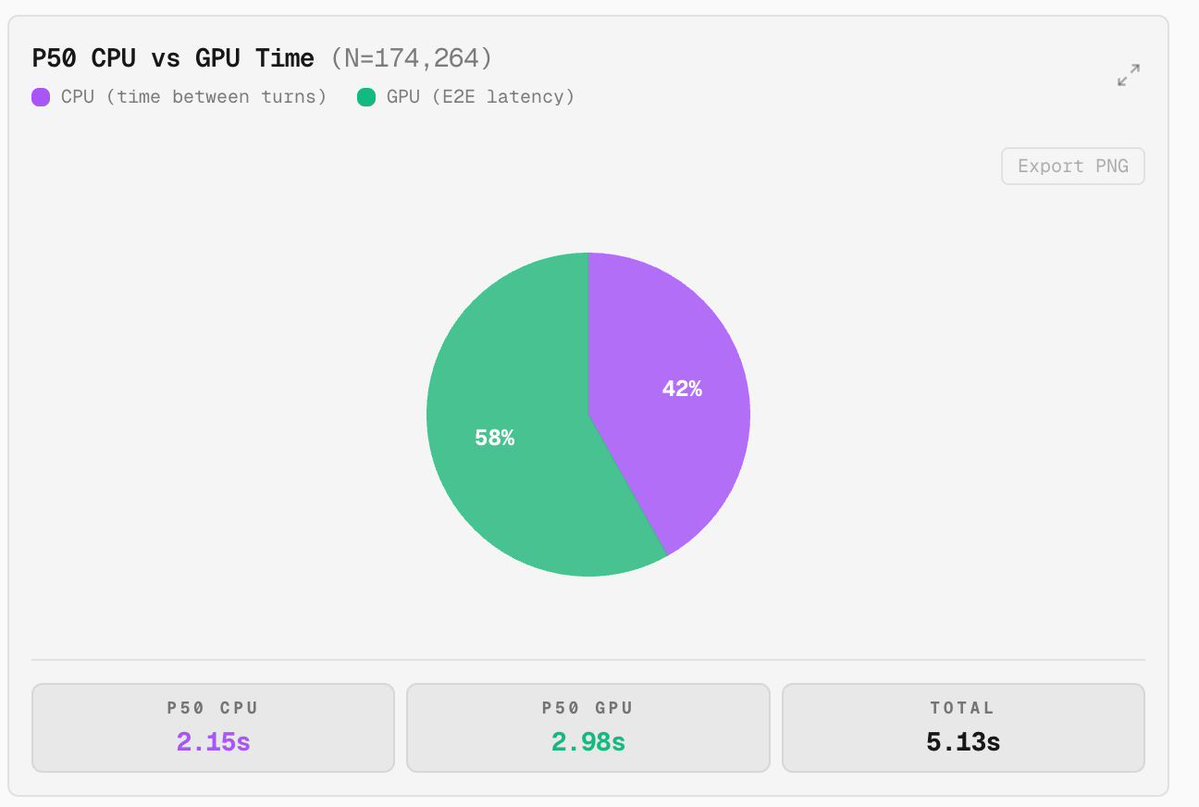
FACT ALERT 🚨 : In modern agentic coding, 42% of the time is spent on CPU doing tool use such as editing files, running Bash scripts, running lints, etc. The economy of traditional cloud computing charges at $ per cpu core. In the economy of agents, the business model is $ per token thus to increase token revenue, you need to increase the amount of CPUs power u have so that you can generate your tokens.
English

It was an honor to give the keynote at MLSys
Covered how AI systems have evolved, why AI is needed to improve them, why results have disappointed, why the future looks amazing, and why I’m working on this at Core Auto
Recording should be out soon, in the meantime slides

English

@FarzaTV @fdotinc @_buildspace 😅!!
Thanks farza, Nights & Weekends really pushed me to test my limits with ideas. Some failed, but I learned a ton.
English

@aryanistweeting I can resonate with “Grilled on a small line in resume” and blinking for 2 seconds straight.
Felt dumber and embarrassing
English

@HanGuo97 This looks like chopped version of Megakernels from @HazyResearch !
English

LLM training is built on fast MatMuls. But many surrounding ops still run as memory-bound kernels.
CODA reparameterizes them to hide in the matmul’s shadow, fused into its epilogue before results leave the chip.
Bonus: LLMs can write fast CODA kernels too (approaching SoLs).

English