@pulkitology @willknight @WIRED Congratulations on the awesome tech and the launch @pulkitology ! Have been a robotics enthusiast since childhood - looking forward to your baby “Eka robotics” to scale new heights! 👏
English
Ruchir puri
8 posts




Introducing Ricursive Intelligence, a frontier AI lab enabling a recursive self-improvement loop between AI and the chips that fuel it. Learn more at ricursive.com

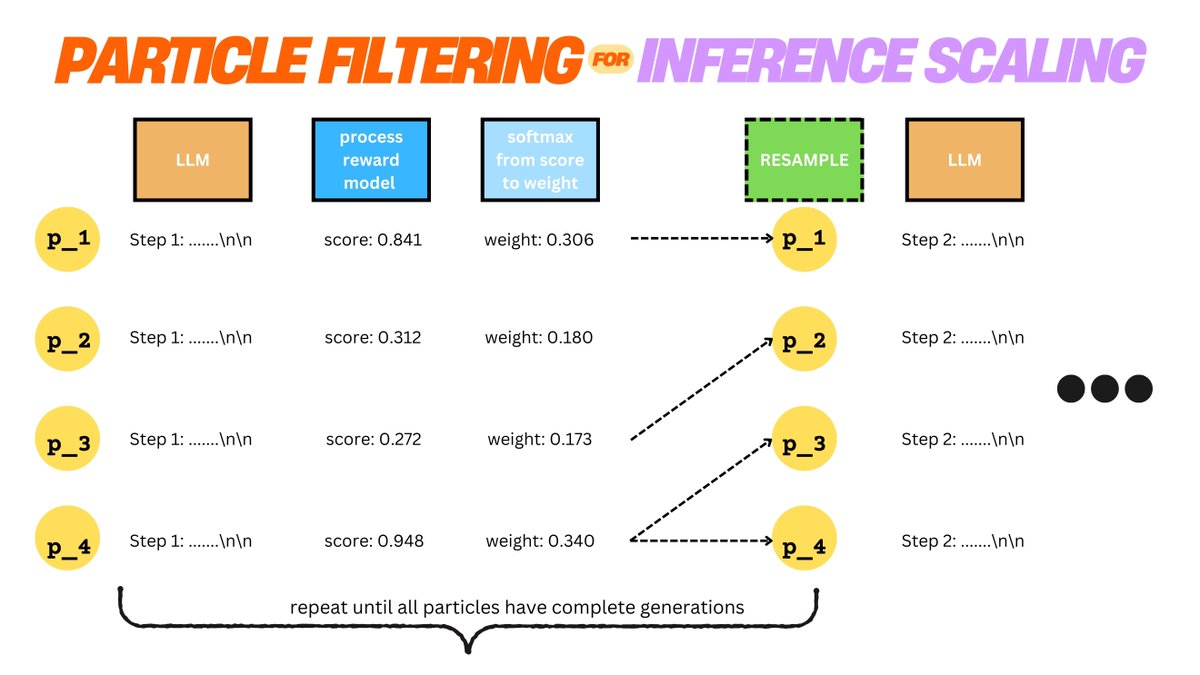
Can we use classical probabilistic inference methods to scale small LMs to o1 level? 🤔 @MIT_CSAIL and Red Hat AI Innovation teams explore: bit.ly/3CHs1Zz