@StasBekman Great work @StasBekman! Really enjoyed/learned a lot about practical optimization from your ALST blog.
English
Sameer Reddy
286 posts
@SameerReddy0
AI Research Engineer @ Predibase

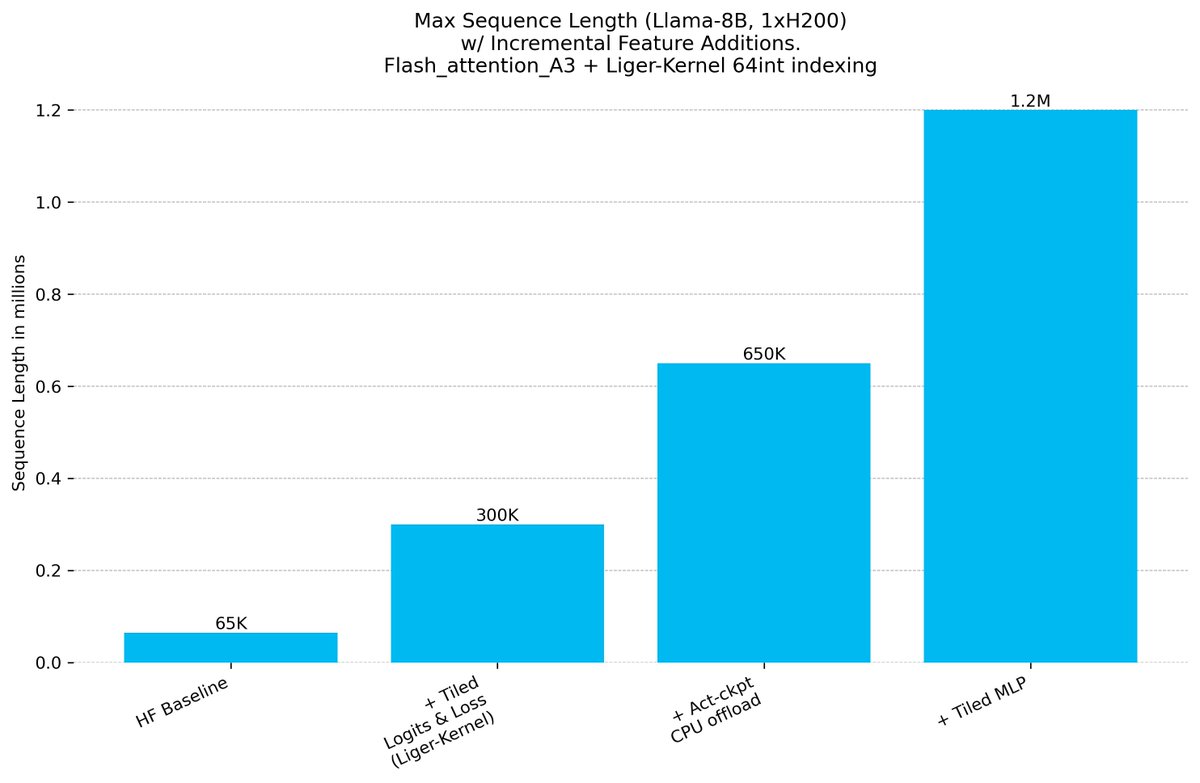











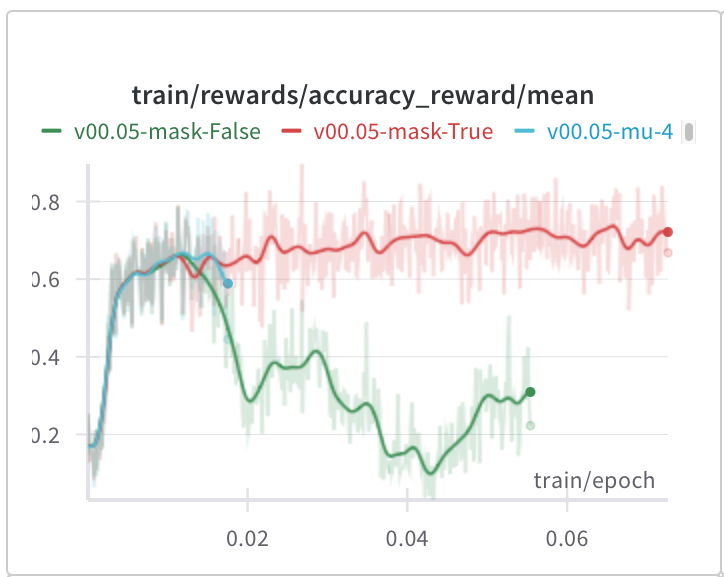
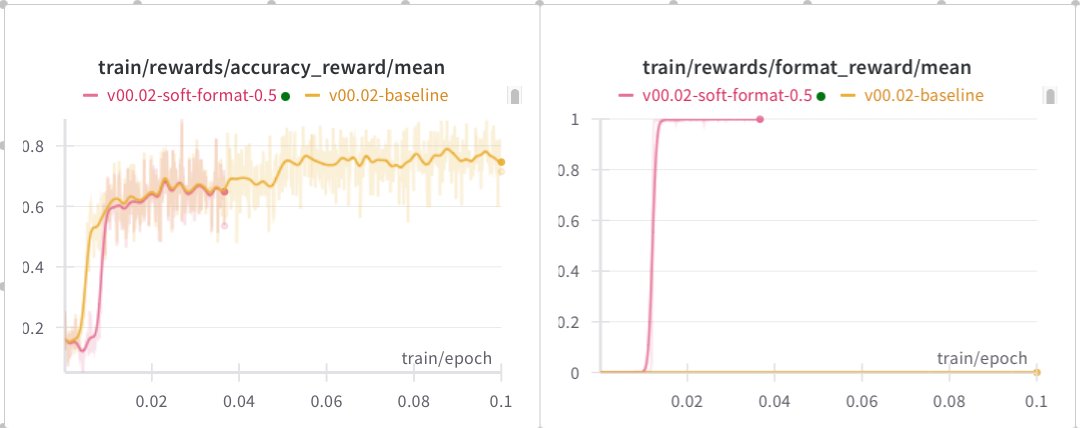
New log book: figuring out which of the many methods are actually needed for stable R1-Zero-like training








🪄 just realized these four major US AI Labs map almost perfectly to the four Hogwarts houses: 1. Slytherin - @xai (obviously) 2. Gryffindor - @OpenAI (obviously) 3. Hufflepuff - @AnthropicAI (obviously) 4. Ravenclaw - @AIatMeta (obviously)