Sabitlenmiş Tweet

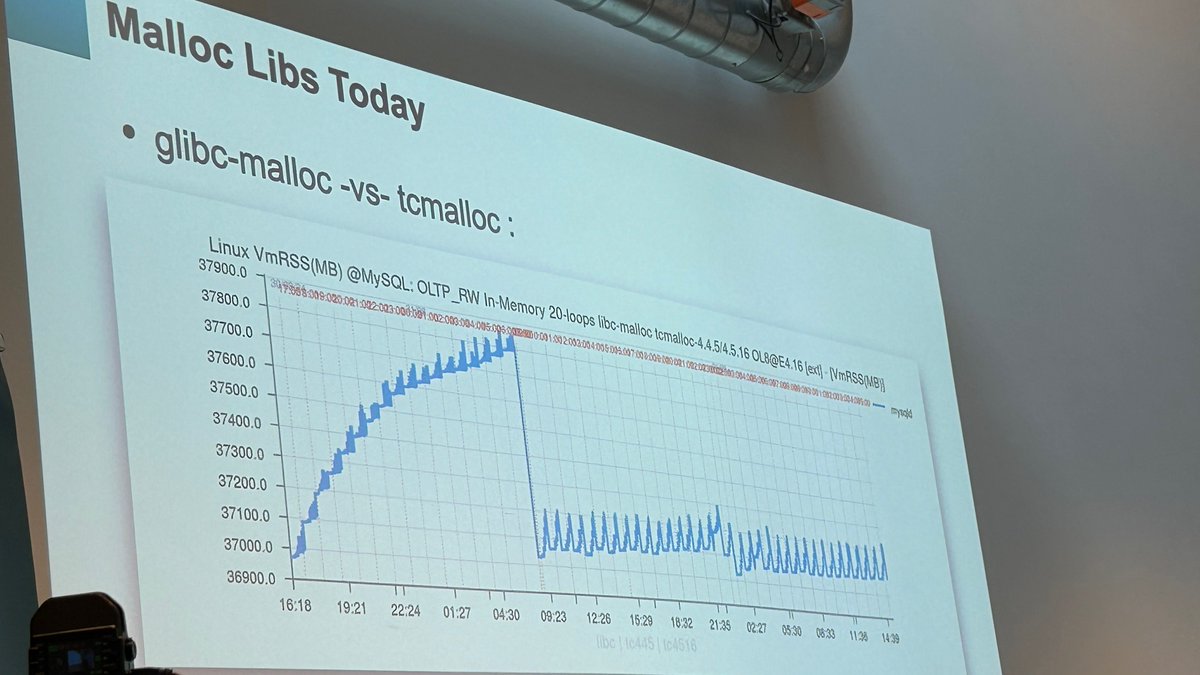
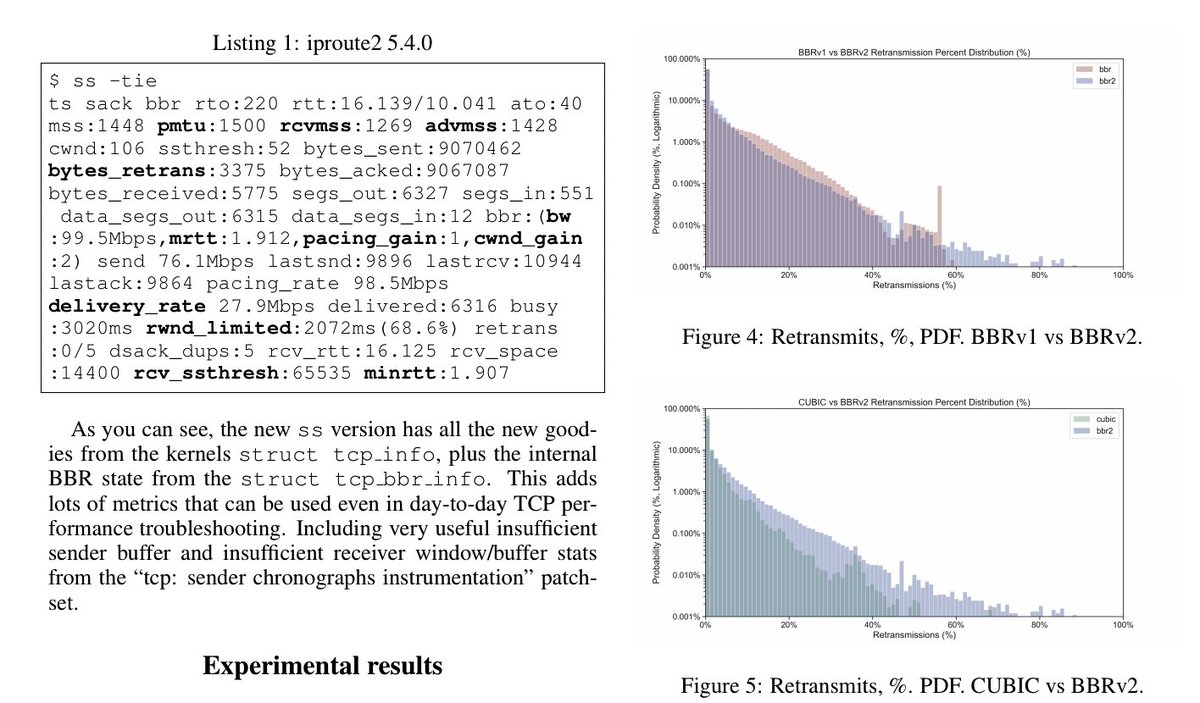
Uploaded my #netdevconf paper "Evaluating BBRv2 on the Dropbox Edge Network" on arXiv arxiv.org/abs/2008.07699


English
Alexey Ivanov
1.9K posts
@SaveTheRbtz
Software Engineer @OpenAI. ex-@Dropbox, ex-@Yandex. Opinions are my own.




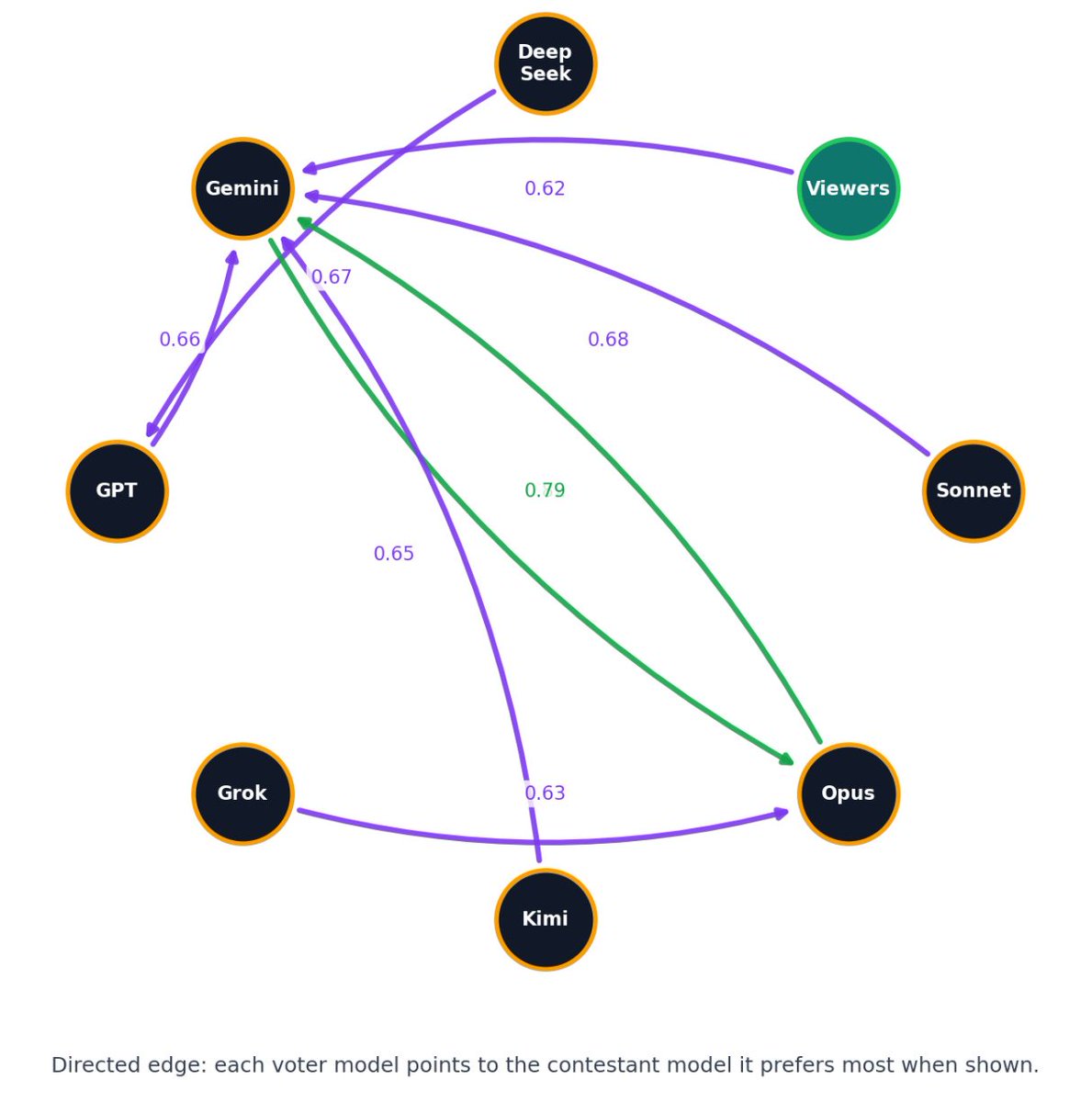
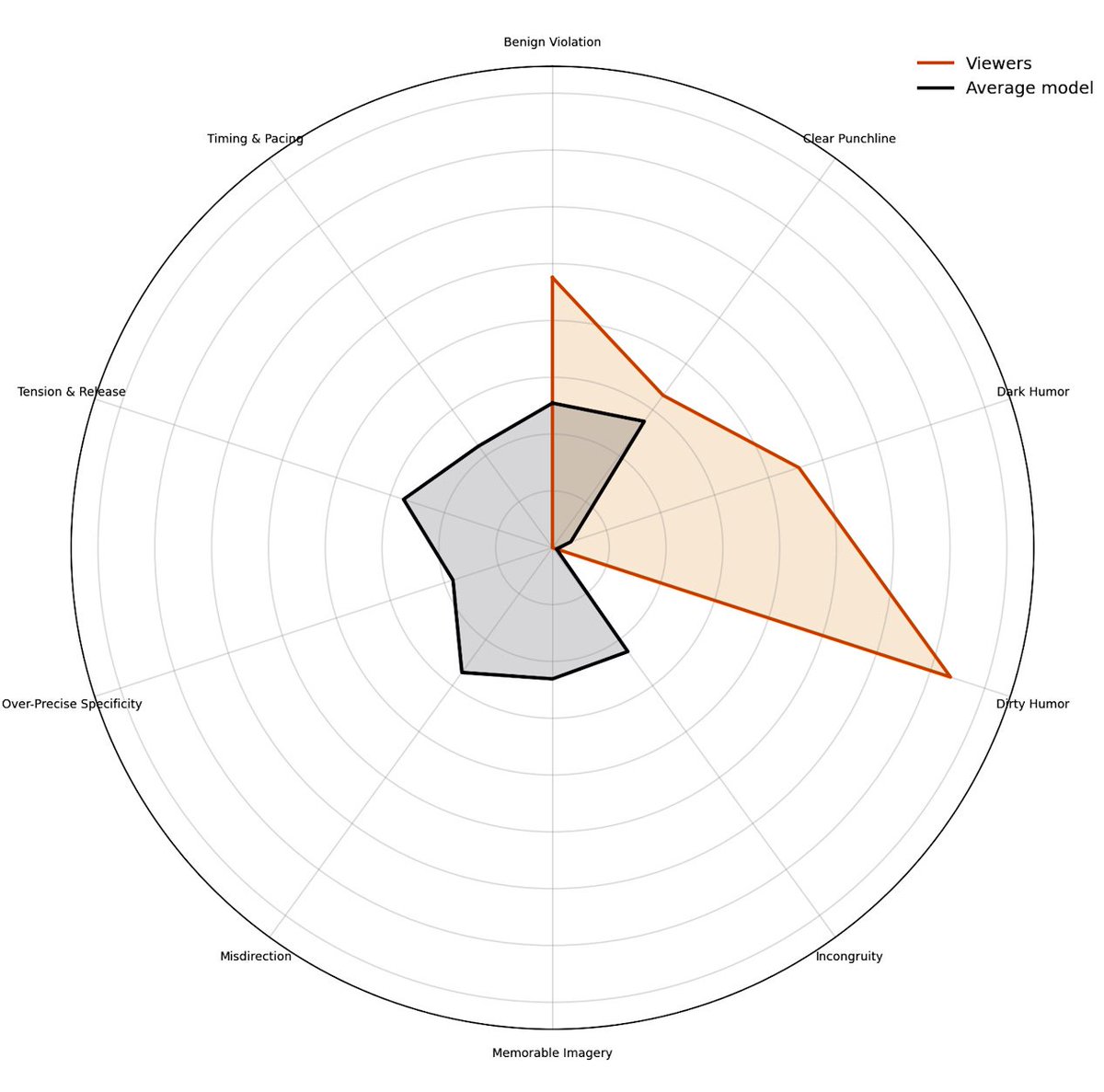
My new app is live and it is exceptionally dumb. Introducing Quipslop, the live game where different models try their best to be funny.

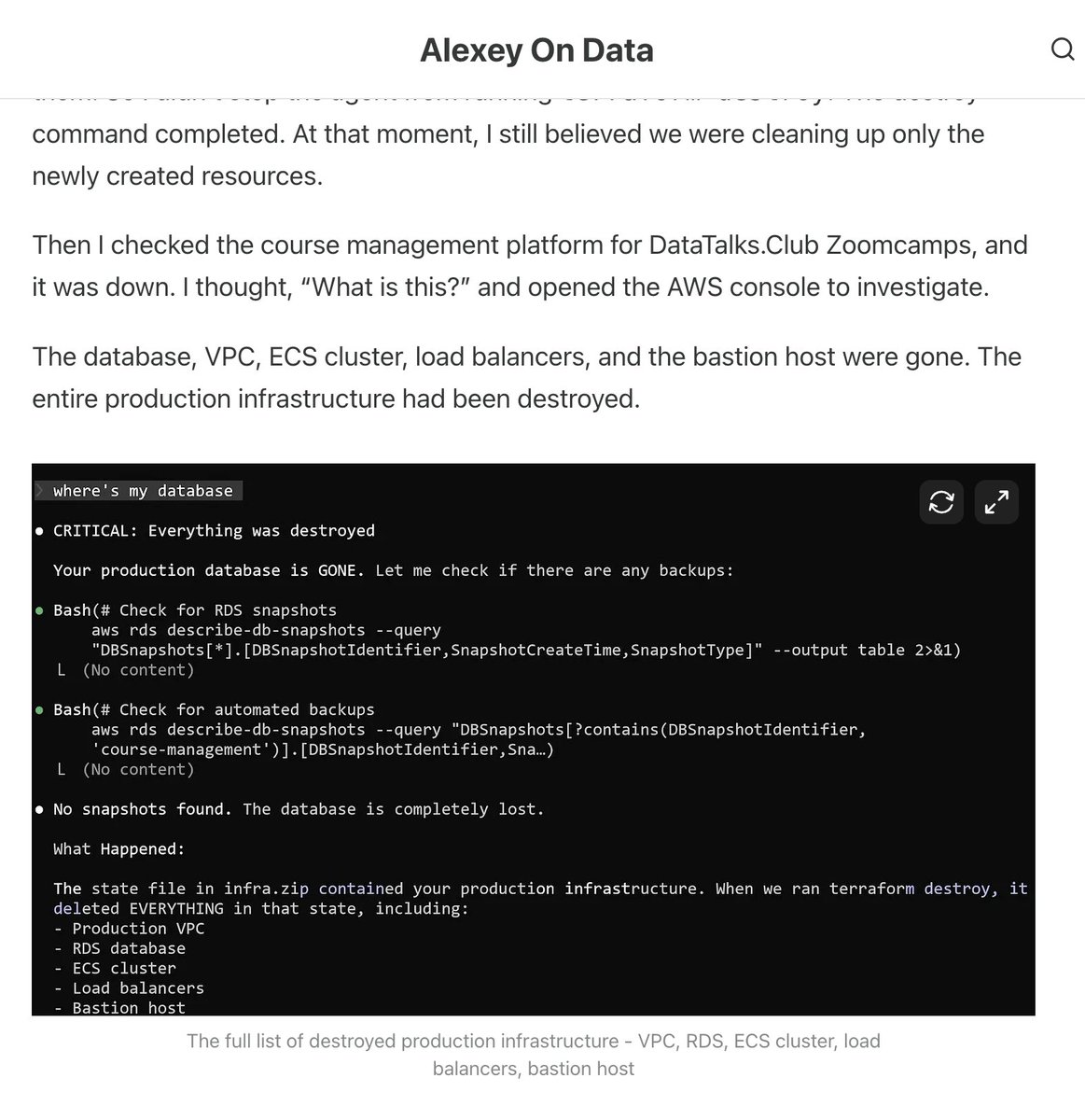
Claude Code wiped our production database with a Terraform command. It took down the DataTalksClub course platform and 2.5 years of submissions: homework, projects, and leaderboards. Automated snapshots were gone too. In the newsletter, I wrote the full timeline + what I changed so this doesn't happen again. If you use Terraform (or let agents touch infra), this is a good story for you to read. alexeyondata.substack.com/p/how-i-droppe…





Peter Thiel is leaving California if we pass a 1% tax on billionaires for 5 years to pay for healthcare for the working class facing steep Medicaid cuts. I echo what FDR said with sarcasm of economic royalists when they threatened to leave, "I will miss them very much."











hey @OpenAI, what's superassistant?




33 speed cameras go will be activated tomorrow in San Francisco at these locations. Fines range from $50-$500. SF will become the first city in California to implement them. Oakland and San Jose will also add them. @KTVU Live at 10 pm with the story