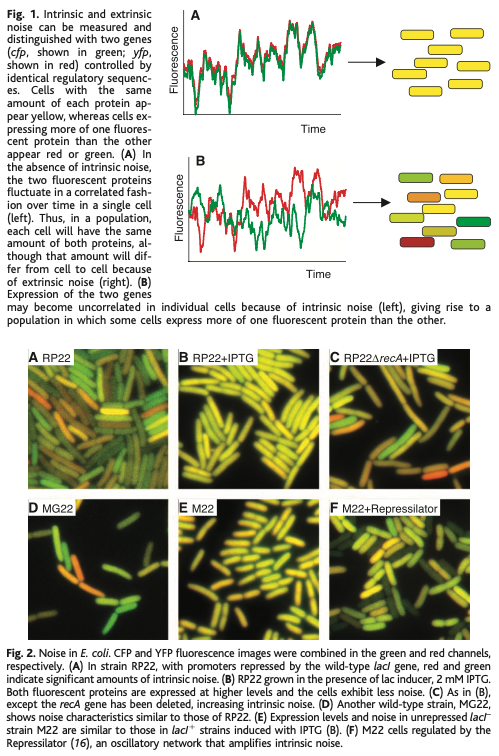
The Sharing Scientist retweetledi

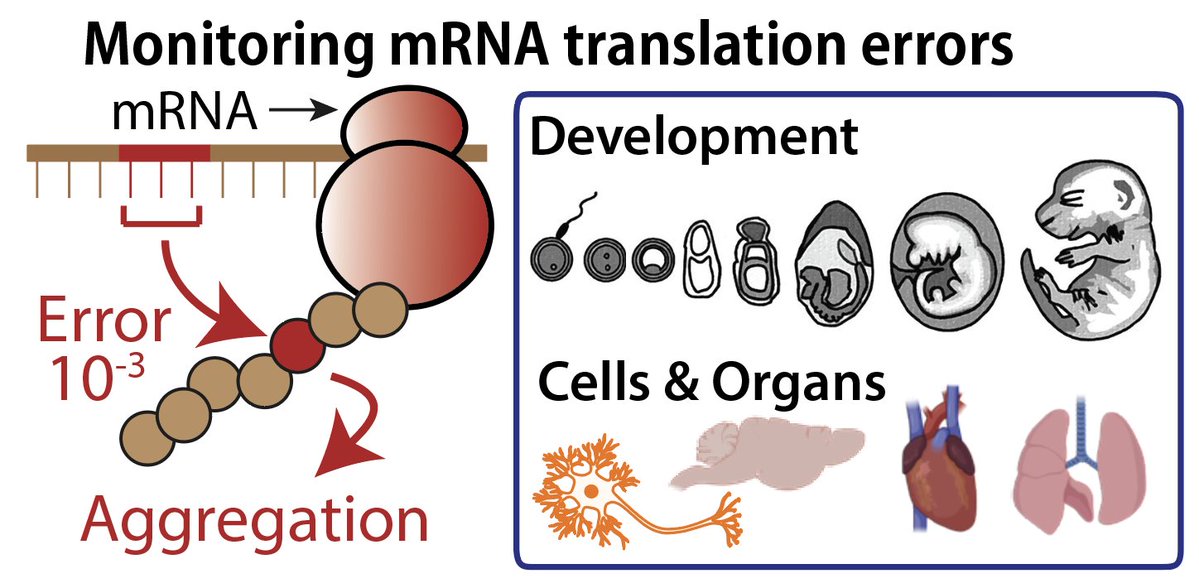
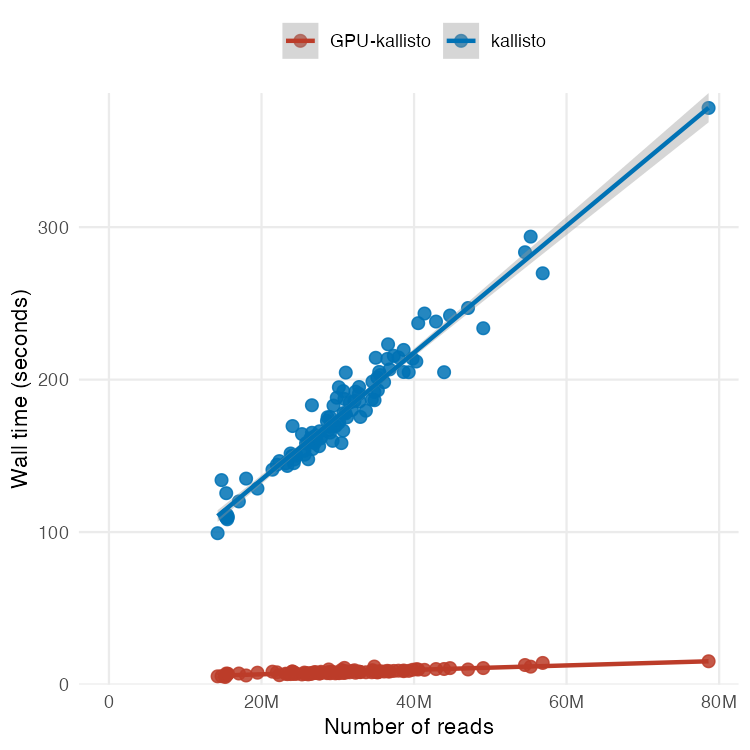
Excited to share our discovery of a new programmable RNA-guided DNA-targeting system hiding inside bacteriophages that predates CRISPR.
We call it VIPR (Viral Interference Programmable Repeat), and it uses an entirely new logic to find its targets.
Thread + link below.
English