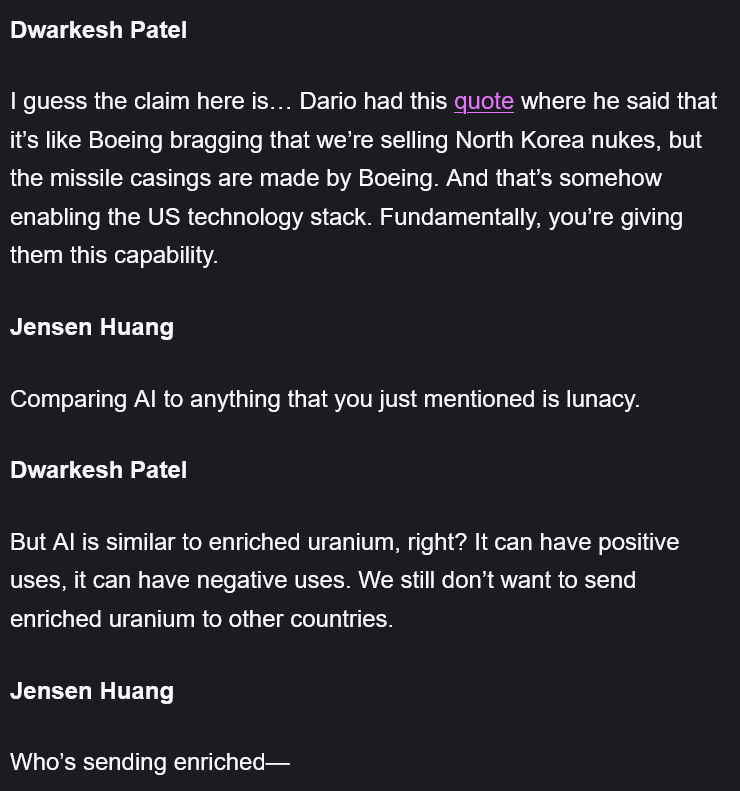
@sameQCU They were kinda talking past each other. Jenson was too.
English
Dysfunctional Screenpass
3K posts

@ScreenpassInt
I am your average Seahawks screen pass


The day that DeepSeek comes out on Huawei first, that is a horrible outcome for our nation.

Today is a big day! We're launching a ~ new ~ version of Claude Code in the desktop app. It's been redesigned from the ground up for parallel work and is a lot faster. It's been my main way to use Claude Code for the last few weeks.




@aleabitoreddit Was it you that mentioned Riber SA as well? $Alrib? It’s been flying as well.

Boris Cherny ( @bcherny ) created Claude Code, but few know his full career story. Today I'm sharing an interview with him about how he grew as an engineer, we discussed: • Why every engineer needs "side quests" • Why being under leveled is a good thing • The story behind his growth to Principal (IC8) at Meta • Technical book that had the biggest impact on him as an engineer • The most important principle in product engineering • Claude Code stories & competition in AI coding products You can find the full episode here: • YouTube: youtu.be/AmdLVWMdjOk • Spotify: open.spotify.com/episode/4toWH5… • Transcript: developing.dev/p/boris-cherny… • Apple: podcasts.apple.com/au/podcast/the…




Today is a big day! We're launching a ~ new ~ version of Claude Code in the desktop app. It's been redesigned from the ground up for parallel work and is a lot faster. It's been my main way to use Claude Code for the last few weeks.



Can I get some questions answered by someone at Anthropic? 1. Can you use an OAuth token generated from a subscription to power the Claude Agent SDK strictly for using Claude Code in a local dev loop? All I want is a more reliable API for parallelizing multiple Claude Code's. 2. If I build an open source tool that relies on this pattern - i.e. for making parallelization easier - can I distribute it so that other people can use it? The reason I'm asking is that the legal compliance docs and @trq212's public statements (below) appear to contradict. x.com/trq212/status/…

Matt Maher tested frontier models in Cursor v. other harnesses. Cursor boosted model performance by 11% on average: Gemini: 52% → 57% GPT-5.4: 82% → 88% Opus: 77% → 93% His benchmark measures how well models implement a 100-feature PRD. @cursor_ai consistently outperformed.