
Sendery
704 posts


Question for my followers: I am building new worlds and Characters for my own IP. Which do you prefer the Animated style or do you think wider audiences are ready for AI realism? Focus on Just the style please...
English

eres un putisimo pesado con la ia de mierda de verdad que asco os tengo a todos los influencers espanoles de tech solo sabeis hacer el puto ridiculo
Carlos Santana@DotCSV
El último vídeo que he subido, si lo ponéis en baja calidad, se ve así 👇
Español


🔴¡EL FIN DE FREEPIK...!
Y el comienzo de la era Magnific 🔥
Rebranding completo de Freepik que ahora pasará a ser Magnific, cambiando identidad visual, colores, web... ¡TODO!
Un cambio magnífico
Magnific (formerly Freepik)@magnific
Freepik is now Magnific One platform to rewrite the rules of creativity
Español

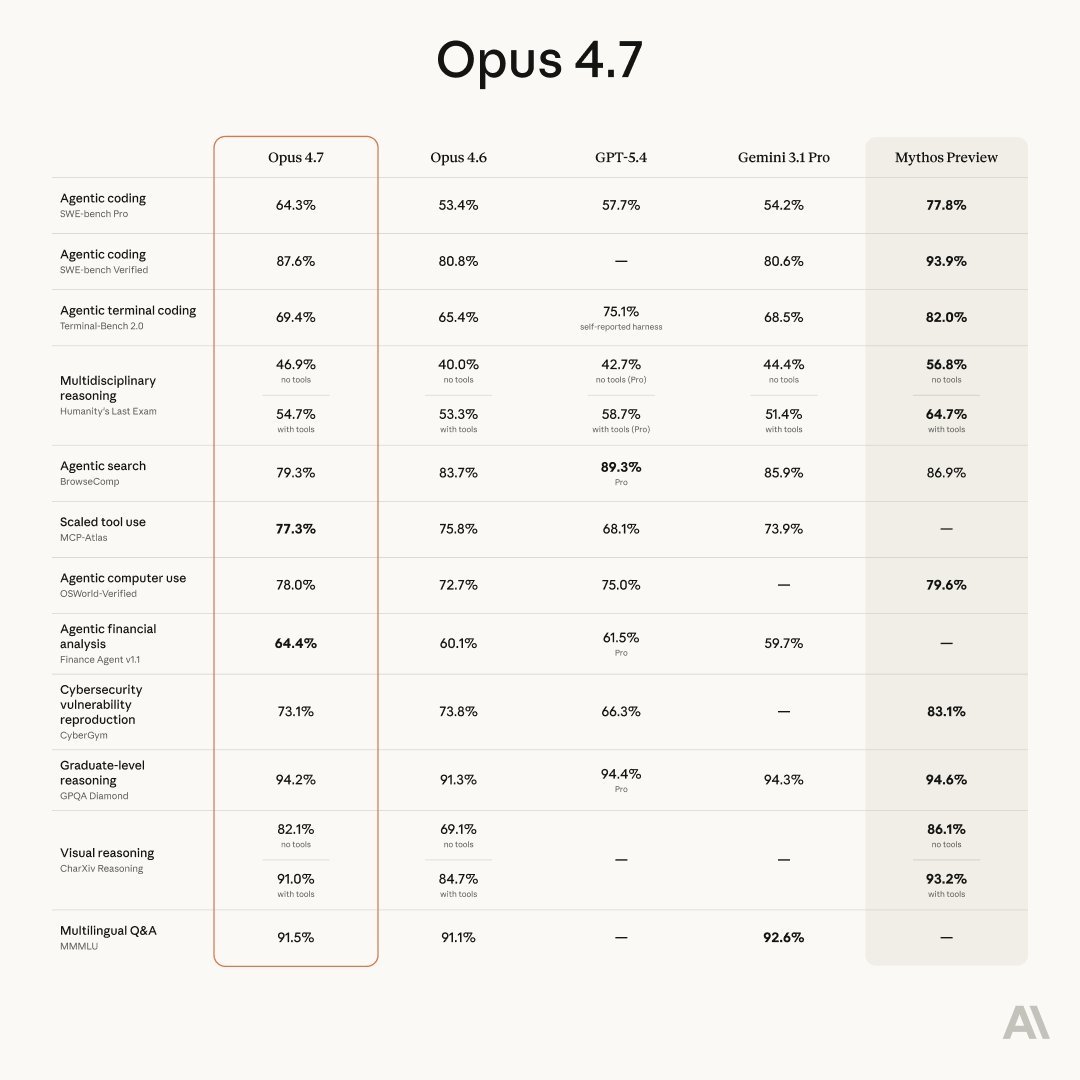
Brillante lo de Anthropic.
① Sacas Opus 4.6
② La gente alucina con lo bueno que es
③ Lo nerfeas durante semanas por costes
④ Lo relanzas como Opus 4.7
⑤ Y de paso cambias el tokenizador para cobrar más
⑥ A facturar
Español


Hermes agent ships with this nifty /manim_video skill so I asked it to explain how a QMD query works:
English
@javilop @miriamgonp @DotCSV @antor @cuenca Seguro que con esto afilado un poco más la punta de lo puedes pasar a un agente para que use Notebooklm como herramienta:
github.com/teng-lin/noteb…
Español

Míriam González@miriamgonp
@javilop Gracias Javi. Aclarar que somos conscientes de que es un tema delicado y no dejamos que la IA tome decidiones finales de tratamientos, lo que hacemos es allanar el terreno a los oncólogos para que puedan tener quizá caminos posibles que no hayan contemplado. Gracias 🙏
Español
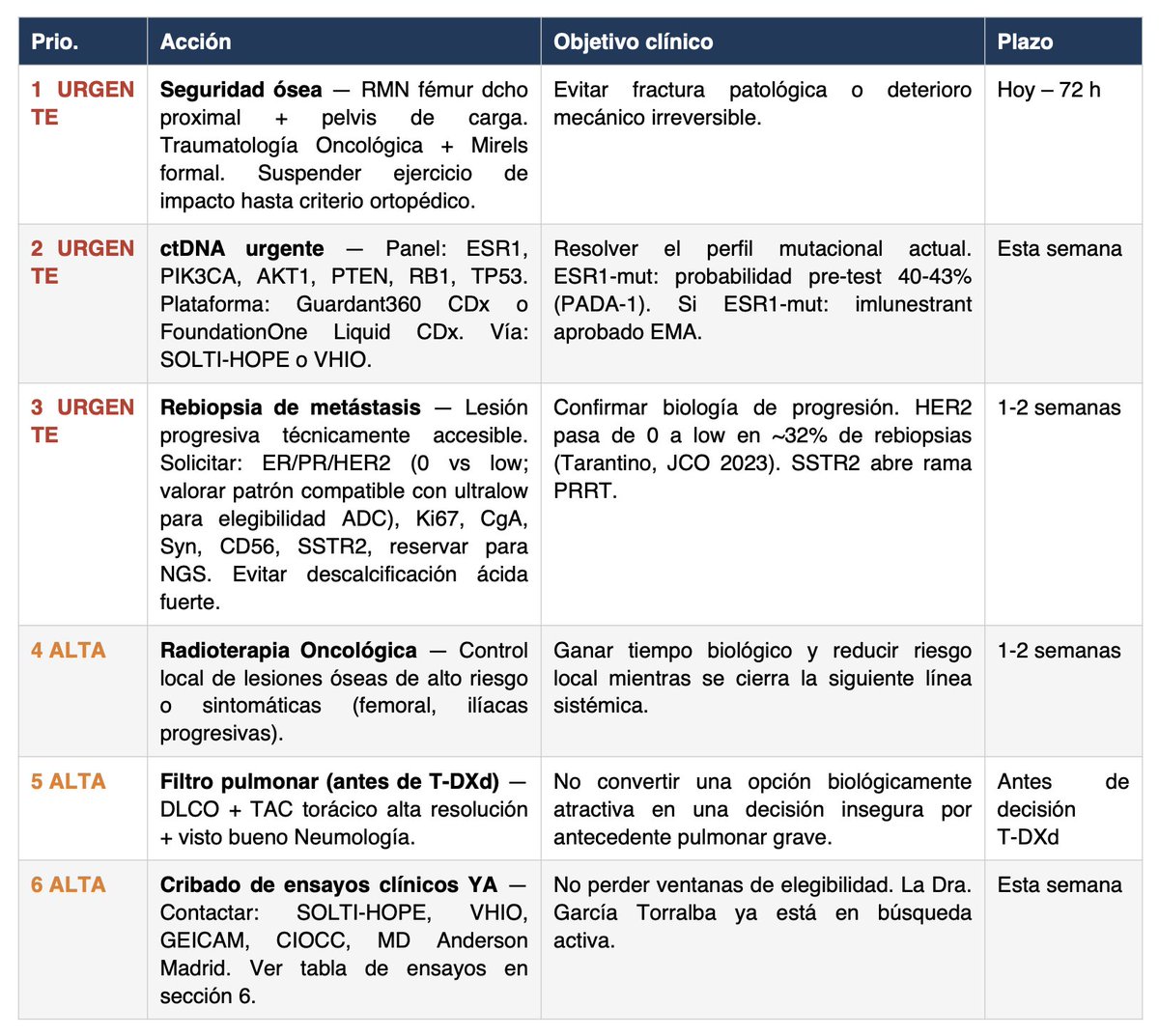
🔴 NECESITO TU ATENCIÓN
Llevo una semana ayudando a Miriam en su caso de cáncer metastásico y quiero compartir la metodología que he estado usando porque es absolutamente replicable.
Pienso que, con suerte, puede ser ÚTIL A OTRAS PERSONAS con cáncer (o con cualquier otra enfermedad).
Los resultados que hemos conseguido no son un milagro, pero pensamos que son realmente útiles y pueden significar una diferencia crucial en un caso médico de vida o muerte.
Aquí va paso a paso el método:
1/ Usar los modelos más avanzados del momento (por desgracia de pago, y no son baratos, opino que Sanidad Pública debería invertir en esto):
- ChatGPT Pro + Extended (40min de pensamiento aprox por llamada)
- Claude Opus 4.6 MAX
Pendientes de probar a fondo:
- Perplexity Sonar Pro
- Notebook LM
2/ Dárselo MUY MASCADO a la IA todo el historial. Esto parece una tontería pero es muy importante.
- Lo primero que pido, con Claude Cowork que tiene acceso al disco duro, es que entre en la carpeta en la que está TODO EL HISTORIAL (pueden ser más de 100 pdfs) y lo unifique todo en:
- Un único PDF (puede ser de más de 1000 páginas o lo que sea necesario)
- Un único txt legible, que debe hacer correctamente usando un script con OCR y luego comprobar con lupa que está bien hecho.
Insisto: no saltar al siguiente paso antes de tener muy bien hecho lo anterior, sobre todo el txt.
3/ Una vez tenemos lo anterior utilizar este prompt junto con el txt y el PDF como archivos de entrada y lanzarlo en AMBOS modelos (y en más si es posible) a la vez.
👉 Os lo dejo aquí, este prompt es increíble complejo/avanzado: dropbox.com/scl/fi/f5luli8… Está pensado para el caso concreto de Miriam, pero con los modelos del punto 1/ podrías adaptarlo a tu caso particular sin problemas.
4/ La PUNTA DE FLECHA enfrentando un modelo al otro: esta metodología no la he escuchado a nadie, pero funciona increíblemente bien. La sensación es la de ir afilando una estaca hasta que adquiere una punta reluciente.
Funciona así: con paciencia y en sucesivas iteraciones (aconsejo mínimo 5 veces, y en en cuenta que si ChatGPT tarda 40min te va a llevar un buen rato) enfrenta el resultado (el PDF) de un modelo a otro. Con un prompt sencillo del estilo:
"Otro comité de expertos opina esto. ¿Cómo lo ves? Si estás de acuerdo o lo contrario dime por qué, y genera un nuevo PDF si lo ves preciso".
El resultado se lo cruzas al modelo contrario. Así, en sucesivas iteraciones, búsquedas de internet, papers, etc. irán encontrando y afilando más cosas.
¿Cuándo acabar? Cuando AMBOS modelos digan que está perfecto y no puedan mejorar más el trabajo del contrario. Esto es tan absurdamente rompedor que pienso que los resultados de TODOS los modelos actuales mejorarían si siguieran esta metodología (apoyándose en una espiral rollo "adversarial model". No entiendo por qué nadie se ha dado cuenta de esto, si lo ha hecho, por qué no se le da más bombo. Funciona impresionantemente bien en cualquier ámbito, inclusive programación y matemáticas.
Es mas, mi teoría es que esto podría hacerse todavía mejor haciéndolo no solo con dos modelos: sino con una mayor combinatoria, añadiendo quizás Perplexity Sonar Pro, etc.
RESULTADOS
Increíbles. Obviamente no puedo saber si mejores que el mejor de los comités científico-sanitarios del mundo, pero le están dando a Miriam una nueva dimensión del caso, tests adicionales que hacer, posibles pruebas, etc.
Obviamente la IA milagros no hace, pero pienso que puede ya, a día de hoy, ayudar a muchos pacientes. Y Sanidad Pública debería invertir mucho, pero mucho, en esto.
Voy a preguntarle a Miriam si puedo poner el PDF completo de resultados más avanzado que conseguimos, para que os hagáis una idea de su calidad. Ya me ha dado más o menos permiso, pero quiero asegurarme 100%.

Español
Sendery retweetledi

Introducing Claude Managed Agents: everything you need to build and deploy agents at scale.
It pairs an agent harness tuned for performance with production infrastructure, so you can go from prototype to launch in days.
Now in public beta on the Claude Platform.
English

English

Doing a workshop on my technical writing process in SF in 2 weeks, hosted by friends @MilksandMatcha and @swyx.
Would love to see you there! Link below.
Sarah Chieng@MilksandMatcha
@trq212 @swyx rsvp here partiful.com/e/8rq83wouDT66…
English

Ray Kurzweil is on stage right now at HumanX and the room is only like 25% full! WTF?

English
Sendery retweetledi

Milla Jovovich (actress from The Fifth Element) created a world-beating Claude memory system with @bensig?!
- 100% on LongMemEval — first perfect score ever recorded.
Free and 100% open source. Github link in the quoted post from Ben.
I'm keen to hear how it works for you.
Ben Sigman@bensig
My friend Milla Jovovich and I spent months creating an AI memory system with Claude. It just posted a perfect score on the standard benchmark - beating every product in the space, free or paid. It's called MemPalace, and it works nothing like anything else out there. Instead of sending your data to a background agent in the cloud, it mines your conversations locally and organizes them into a palace - a structured architecture with wings, halls, and rooms that mirrors how human memory actually works. Here is what that gets you: → Your AI knows who you are before you type a single word - family, projects, preferences, loaded in ~120 tokens → Palace architecture organizes memories by domain and type - not a flat list of facts, a navigable structure → Semantic search across months of conversations finds the answer in position 1 or 2 → AAAK compression fits your entire life context into 120 tokens - 30x lossless compression any LLM reads natively → Contradiction detection catches wrong names, wrong pronouns, wrong ages before you ever see them The benchmarks: 100% recall on LongMemEval — first perfect score ever recorded. 500/500 questions. Every question type at 100%. 92.9% on ConvoMem — more than 2x Mem0's score. 100% on LoCoMo — every multi-hop reasoning category, including temporal inference which stumps most systems. No API key. No cloud. No subscription. One dependency. Runs on your machine. Your memories never leave. MIT License. 100% Open Source. github.com/milla-jovovich…
English
@OfficialLoganK @ai_for_success it's already active managing git branches?
English

@ai_for_success we have an internal version of this right now : ) wrapping it up soon!
English

I wish AI Studio had an option to clone a repo directly from GitHub and build on top of it too.
Currently, you can start and push code to GitHub, but not the other way around.
English
@MatthewBerman I like it but all the good stuff is in the features section the main page lacks a good hook of the real capabilities
English

I built something...
journeykits.ai
Journey helps agents discover and install full workflows easily.
Please leave your feedback below!
English
Looking for more people to try out something I've been working on. Comment below if you're running sophisticated agent workflows.
English
@developedbyed Include TRELIS for 3d asset generation and an autorig
English

@MatthewBerman I considere the bet on the metaverse was maybe to bold but without it no meta quest, no Ray-Ban meta AI, no xreal, no proyect Astra o Orion...
I think that meta lacks the ability to create easy integrable things if the have play more in favor for makers the ecosystem will shine
English
Do they have to keep the name Meta?
Forward Future@ForwardFuture
“A dinosaur of the ZIRP era.” @creatine_cycle chat metaverse closure with Matt and Nick: “Maybe one day we replace screens with goggles, but the form factor still doesn’t feel right.” “The metaverse feels like already feels like a relic, like NFTs.”
English
Sendery retweetledi

@Meta_Engineers @Arm It will be great if there is a SBC raspberry PI/Jetson Nano like to start a tinkers/maker community
English

Today we’re announcing a new partnership with @Arm to collaborate on the development of multiple generations of purpose-built CPUs to support our compute and AI infrastructure.
The first generation of the chip that we co-developed, the Arm AGI CPU, delivers more than 2x performance per rack compared with x86 platforms. The Arm AGI CPU will also be available to the broader AI ecosystem through Arm and Meta will be releasing our board and rack designs for this CPU under the Open Compute Project later this year.
Learn more about our partnership: go.meta.me/15e3b8

English
@mreflow Follow the tips of @MatthewBerman for telegram channels for memory optimization and recurrent jobs. Use /new when chats are to long
English
For those using OpenClaw at a high level, what’s your favorite default model? I was using Nemotron 3-super locally on my Spark but it hits context limits too quickly. I’m mostly using Sonnet-4.6 now but API costs rack up fast. I love my claw but honestly haven’t optimized models and model switching as much as I should.
I like the bigger context windows when building out new skills and automations so it doesn’t forget what we’re building but that’s also when API costs soar. I like my local models because I have a Spark for that reason but context windows aren’t great on the local models I’ve tried…
Looking for advice from some more experienced OpenClawers.
English