
Sergio
96 posts

Sergio
@SergioOSINT
Security Research | OSINT | AI Research
Katılım Ağustos 2025
85 Takip Edilen7 Takipçiler

@SergioOSINT Sorry, I'm running critical banking, airline & insurance infrastructure so upgrading would be irresponsible towards our shareholders
(no seriously this is just a joke, i do hope no one is still running this in prod, but also i wouldn't be 100% surprised :] )
English
Very irresponsible to publish this without waiting for the patch first. Please delete
Nick G@kallsyms
🚨 0-day alert! GPT 5.5 has found and exploited a network accessible RCE in Mac OS 9.2.1 🚨
English



@SergioOSINT @uwunetes @0xtiago_ @DBrodniak have you tried it yourself? If so, what model(s) did you try?
English

xai is the most unserious US lab lmao why would u ever release this? its a closed source model worse than open source models like why would i use this over deepseek or kimi
Artificial Analysis@ArtificialAnlys
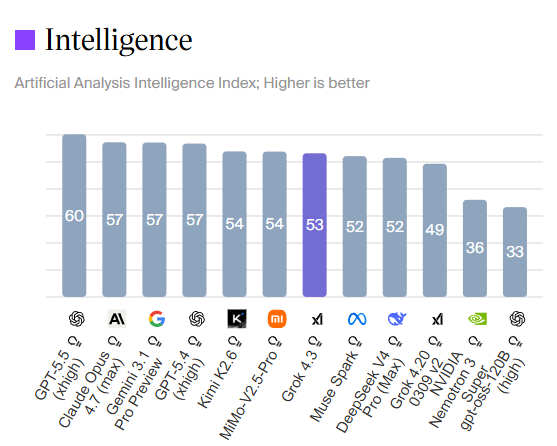
xAI has launched Grok 4.3, achieving 53 on the Artificial Analysis Intelligence Index with improved agentic performance, ~40% lower input price, and ~60% lower output price than Grok 4.20 The release of Grok 4.3 places @xAI just above Muse Spark and Claude Sonnet 4.6 on the Intelligence Index, and a 4 points ahead of the latest version of Grok 4.20. Grok 4.3 improves its Artificial Analysis Intelligence Index score while reducing cost to run the benchmark suite. Key Takeaways: ➤ Grok 4.3 improves on cost-per-intelligence relative to Grok 4.20 0309 v2: it scores higher on the Intelligence Index while costing less to run the full benchmark suite. Grok 4.3 costs $395 to run the Artificial Analysis Intelligence Index, around 20% lower than Grok 4.20 0309 v2, despite using more output tokens. This makes it one of the lower-cost models at its intelligence level ➤ Large increase in real world agentic task performance: The largest single benchmark improvement is on GDPval-AA, where Grok 4.3 scores an ELO of 1500, up 321 points from Grok 4.20 0309 v2’s score of 1179 Grok 4.3, surpassing Gemini 3.1 Pro Preview, Muse Spark, Gpt-5.4 mini (xhigh), and Kimi K2.5. Grok 4.3 narrows the gap to the leading model on GDPval-AA, but still trails GPT-5.5 (xhigh) by 276 Elo points, with an expected win rate of ~17% against GPT-5.5 (xhigh) under the standard Elo formula ➤ Grok 4.3’s performs strongly on instruction following and agentic customer support tasks. It gains 5 points on 𝜏²-Bench Telecom to reach 98%, in line with GLM-5.1. Grok 4.3 maintains an 81% IFBench score from Grok 4.20 0309 v2 ➤ Gains 8 points on AA-Omniscience Accuracy, but at the cost of lower AA-Omniscience Non-Hallucination Rate of 8 points, so Grok 4.20 0309 v2 still leads AA-Omniscience Non-Hallucination Rate, followed by MiMo-V2.5-Pro, in line with Grok 4.3 Congratulations to @xAI and @elonmusk on the impressive release!
English
English

.@sama asks GPT-5.5 what kind of party it wants
Sam Altman@sama
GPT-5.5 is going to have a party for itself. it chose 5/5 at 5:55 pm for the date and time. if you'd like to come, let us know here: luma.com/5.5 codex will help the team pick people from the replies. 5.5 had some good ideas/requests for the party, which we'll do.
English
@bridgemindai I respect your work and everything, but if so then please don't include Security as a statistic of it. GPT 5.5 is near Mythos level on security research and general security, and Sonnet 4.6 is not near Mythos level (should be obvious)
English

@SergioOSINT Fair. BridgeBench is code-analysis fabrication, not a security-research benchmark.
English
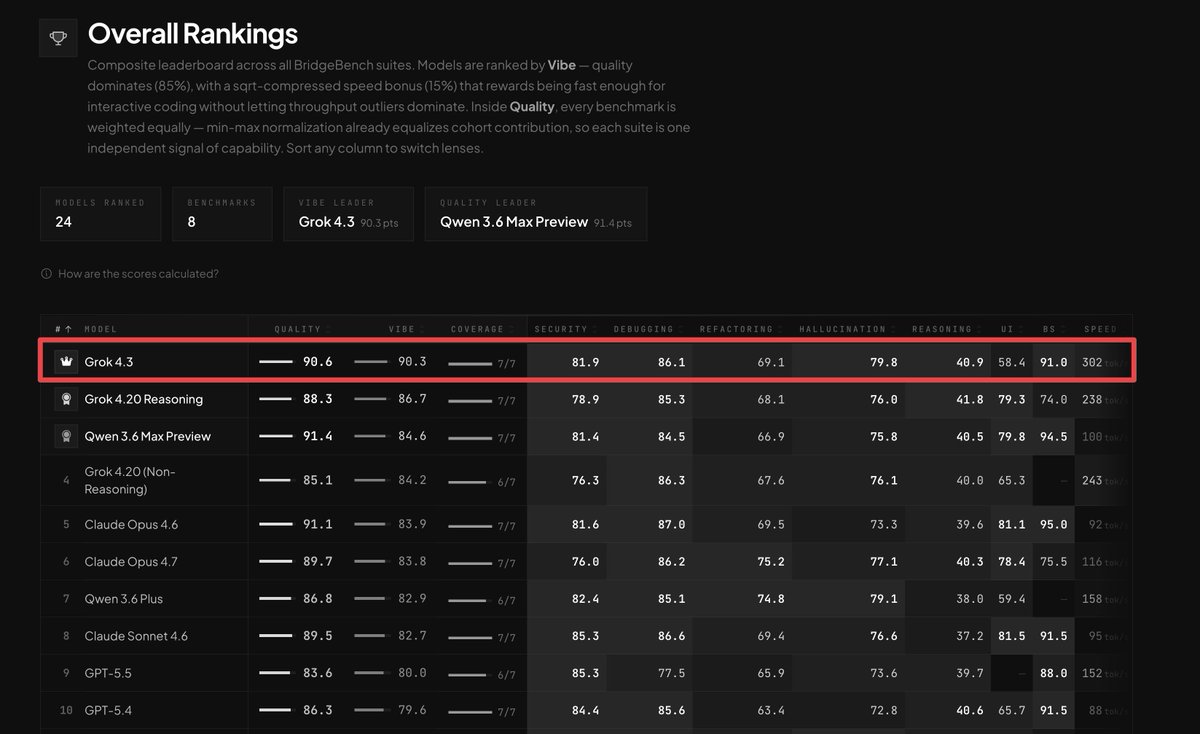
Grok 4.3 just took #1 on BridgeBench.
500B parameters.
90.3 Vibe score.
302 tok/s.
Lowest hallucination rate in the field.
Fast enough for real vibe coding, not just leaderboard screenshots.
The AI race is shifting.
If Grok keeps compounding at this pace, xAI is not just competing.
They’re becoming the favorite to win.
English

Where are all the people that called me crazy just because I said Mythos wasn't really that dangerous?
We now have GPT-5.5, which doesn't seem to be much worse, and unlike Mythos you can actually use it right now
AI Security Institute@AISecurityInst
OpenAI’s GPT-5.5 is the second model to complete one of our multi-step cyber-attack simulations end-to-end 🧵
English
@edugarmer @XFreeze We're going to see a bunch of iterations first as Elon expects the release of Grok 5 I think it was to be AGI
English

@XFreeze Amazing. Grok 5 might really surpass Anthropic. We may have a suprise by the end of the year. Things may change soon.
English

Grok 4.3 is sitting in the top 7 with literally just 500B parameters. The lowest size by far
Meanwhile, every other model competing at this level is between 1T to 6T parameters
It's not just small. It's also the most intelligent, fastest, and lowest-hallucination model in its class....all while being one of the cheapest to run
xAI built the most efficient frontier model on the planet

Artificial Analysis@ArtificialAnlys
xAI has launched Grok 4.3, achieving 53 on the Artificial Analysis Intelligence Index with improved agentic performance, ~40% lower input price, and ~60% lower output price than Grok 4.20 The release of Grok 4.3 places @xAI just above Muse Spark and Claude Sonnet 4.6 on the Intelligence Index, and a 4 points ahead of the latest version of Grok 4.20. Grok 4.3 improves its Artificial Analysis Intelligence Index score while reducing cost to run the benchmark suite. Key Takeaways: ➤ Grok 4.3 improves on cost-per-intelligence relative to Grok 4.20 0309 v2: it scores higher on the Intelligence Index while costing less to run the full benchmark suite. Grok 4.3 costs $395 to run the Artificial Analysis Intelligence Index, around 20% lower than Grok 4.20 0309 v2, despite using more output tokens. This makes it one of the lower-cost models at its intelligence level ➤ Large increase in real world agentic task performance: The largest single benchmark improvement is on GDPval-AA, where Grok 4.3 scores an ELO of 1500, up 321 points from Grok 4.20 0309 v2’s score of 1179 Grok 4.3, surpassing Gemini 3.1 Pro Preview, Muse Spark, Gpt-5.4 mini (xhigh), and Kimi K2.5. Grok 4.3 narrows the gap to the leading model on GDPval-AA, but still trails GPT-5.5 (xhigh) by 276 Elo points, with an expected win rate of ~17% against GPT-5.5 (xhigh) under the standard Elo formula ➤ Grok 4.3’s performs strongly on instruction following and agentic customer support tasks. It gains 5 points on 𝜏²-Bench Telecom to reach 98%, in line with GLM-5.1. Grok 4.3 maintains an 81% IFBench score from Grok 4.20 0309 v2 ➤ Gains 8 points on AA-Omniscience Accuracy, but at the cost of lower AA-Omniscience Non-Hallucination Rate of 8 points, so Grok 4.20 0309 v2 still leads AA-Omniscience Non-Hallucination Rate, followed by MiMo-V2.5-Pro, in line with Grok 4.3 Congratulations to @xAI and @elonmusk on the impressive release!
English
@haider1 I mean this doesn't really mean it's marketing just that OpenAI is a bit more careless, as well as this, Mythos was supposed to be good at code not general offensive cyber so not active directory and such attacks. This is way out of the field Mythos was made for.
English

seems like the "mythos" panic was mostly anthropic marketing
AISI found gpt-5.5 performs nearly on par with, or better than, mythos in several cases — completing TLO end-to-end in 2/10 attempts, while mythos preview did it in 3/10
on expert-level tasks:
gpt-5.5 scored 71.4%
mythos scored 68.6%

English
@scaling01 I mean if we're going to be fair, Grok 4.3 is punching well, both MiMo-V2.5 Pro and Kimi K2.6 are both 1T+ models and distilled heavily from other models as well. Grok 4.3 is a 0.5 T model.
English


So why is mythos gatekept now?
AI Security Institute@AISecurityInst
OpenAI’s GPT-5.5 is the second model to complete one of our multi-step cyber-attack simulations end-to-end 🧵
English
@levzzz5154 @MTSlive Mostly when you mean distilling its taking full trajectories including thoughts
English



@sama 71.4% pass rate sounds amazing until you remember that in software, the other 28.6% is where everything breaks. A smartphone camera that nails 71% of shots is great for Instagram. It's not replacing a professional photographer
x.com/i/status/20491…
Krittin Kalra@KrittinKalra
MKBHD explained the future of vibe coding… by accident
English

lisan say more mean things about us you're being too nice
Lisan al Gaib@scaling01
GPT-5.5 is on par with Claude Mythos - GPT-5.5 average pass rate of 71.4% (±8.0%) - Mythos Preview 68.6% (±8.7%) - GPT-5.5 solved a task that takes a human expert ~12 hours in under 11 minutes at a cost of $1.73
English

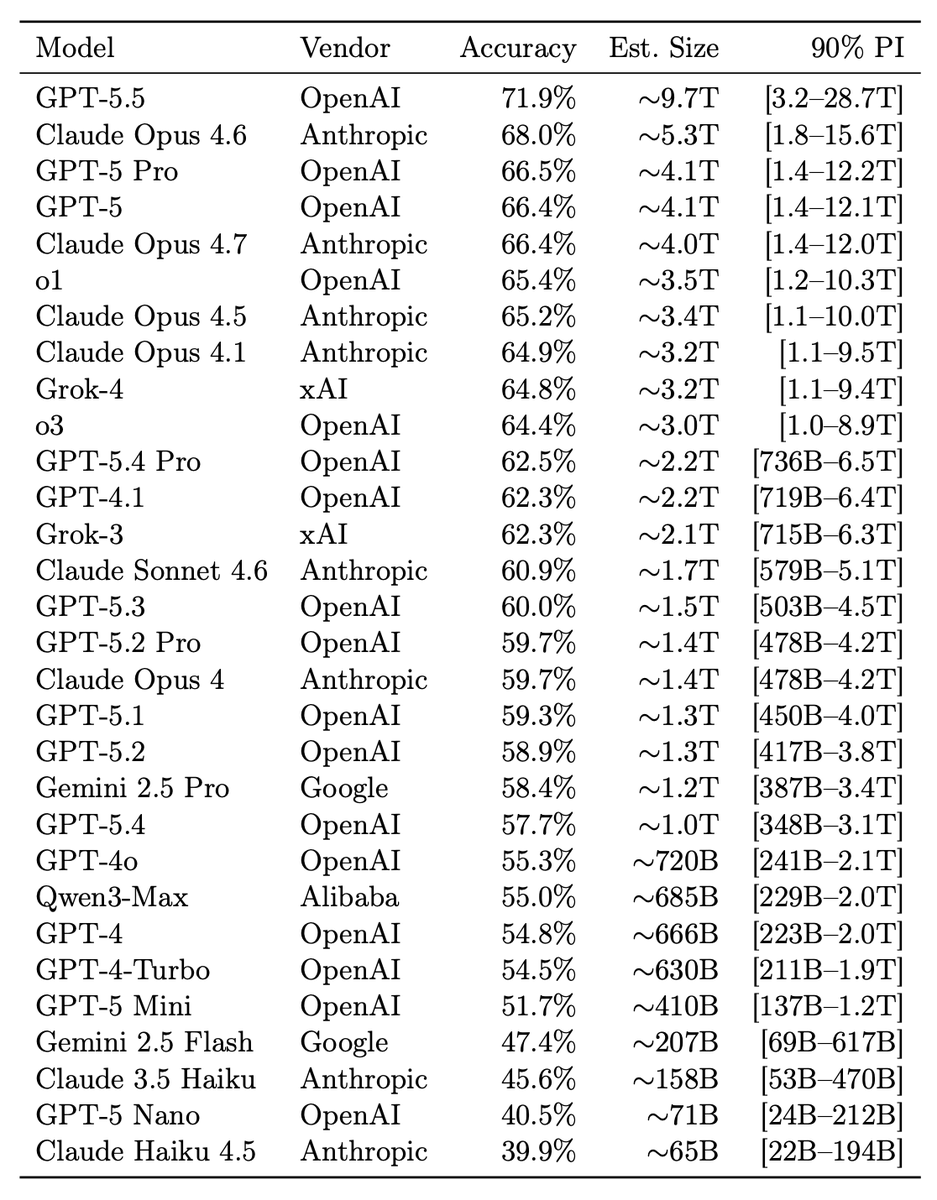

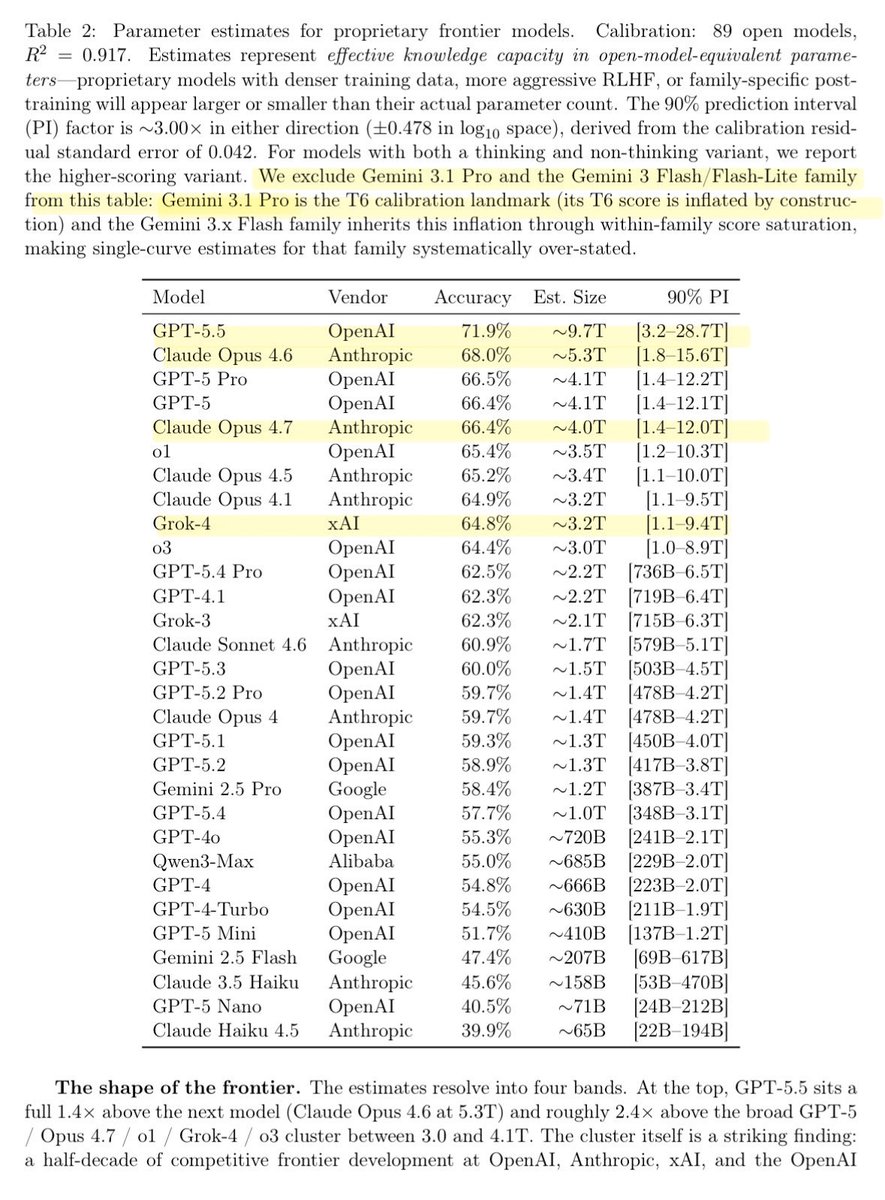
Researchers just estimated the size of all the LLMs by asking it knowledge questions of varying degrees of obscurity!
– GPT 5.5: ~10T params
– Claude Opus 4.x: ~4-5T
– Grok 4: ~3T
The idea here is that factual capacity scales log-linearly with size. The paper shows 7 knowledge tiers and T7 is essentially ~0% for all models, suggesting there is still significant headroom for pretraining. Gemini 3.1 Pro is likely >10T given its used as an anchor but has no direct estimate.
This means we can infer what different models might cost to some degree and their post-training effectiveness (performance at certain non-factual tasks given its size).
One of the coolest papers I’ve read of late.
English

"I'm too scared to talk to this girl"
What your ancestors did on a random Wednesday:
English