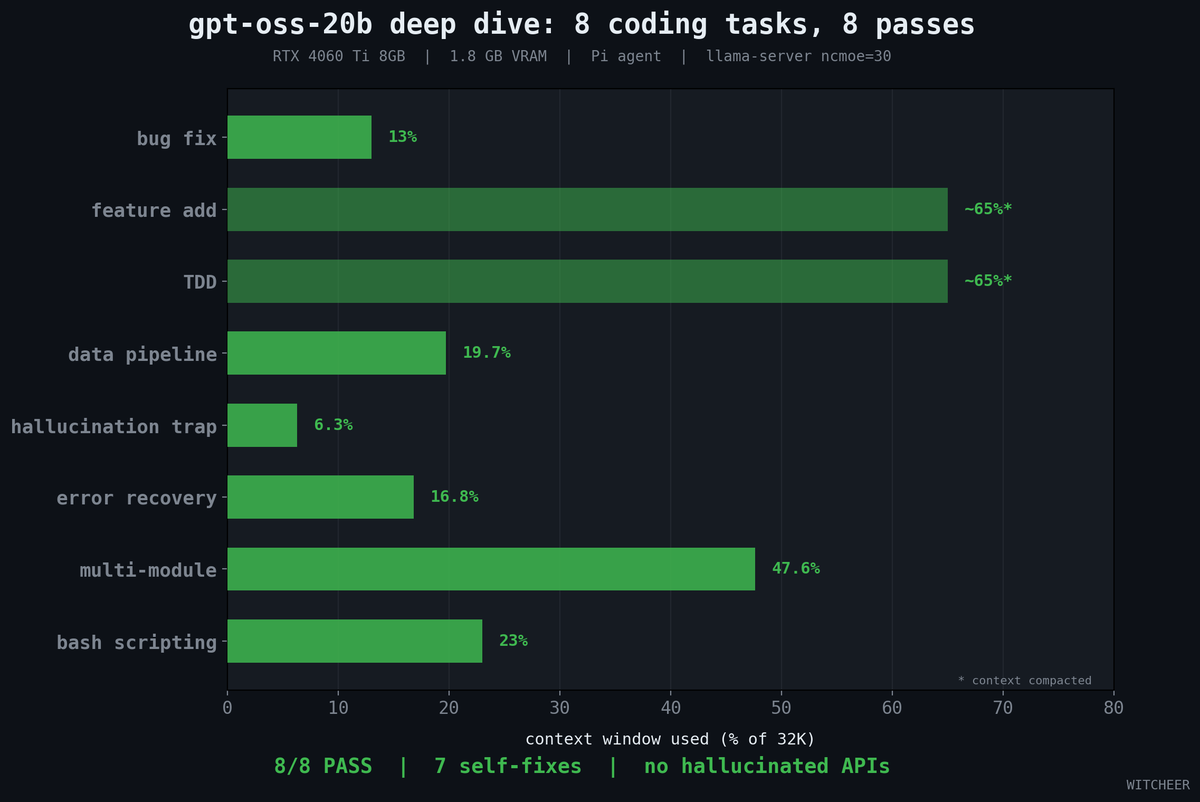
One of the weakest models for coding tasks: terrible tool discipline and reasoning you can’t turn off. It’s the only model I’ve managed to push into a looping hallucination just by asking a technical question in the WebUI, repeated three times with a full model reload between prompts. Impressively strong (and wrong) behavior.
English