Sabitlenmiş Tweet

What Makes a Base Language Model Suitable for RL?
Rumors in the community say RL (i.e., RLVR) on LLMs is full of “mysteries”:
(1) Is the magic only happening on Qwen + Math?
(2) Does the "aha moment" only spark during math reasoning?
(3) Is evaluation hiding some tricky traps?
(4) Is RL’s calm surface all thanks to Pre/Mid-training carrying the weight?
Why does RL on LLaMA consistently underperform compared to Qwen?
What makes a base model truly ready for RL scaling?
What are the secrets under the hood?
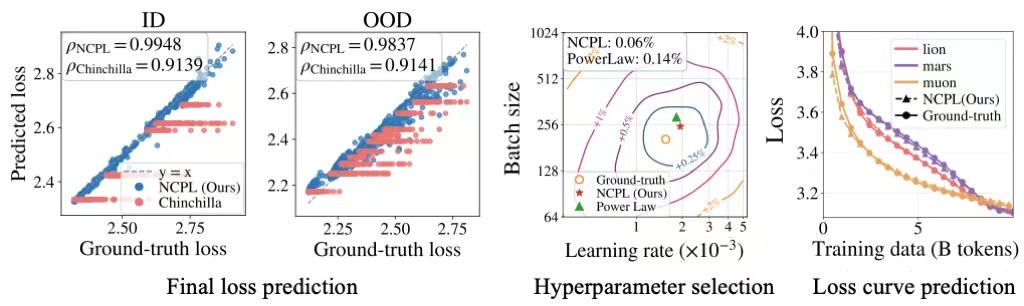
Due to the cost of training from scratch, we conduct extensive controlled experiments with 20B-token mid-training, systematically investigating what really matters for RL success.
💡Key insights:
- High-quality math data is key to RL scaling.
- QA data helps, but it depends on task similarity.
- Instruction data boosts QA’s effectiveness.
- More mid-training improves RL performance.
Armed with these insights, we apply a two-stage (stable+decay) mid-training strategy on LLaMA, scaling up to 200B tokens—and RL performance on LLaMA now matches Qwen!
To support this, we introduce MegaMath-Web-Pro-Max, a high-quality math-centric pretraining corpus. The dataset will be released soon on Hugging Face—stay tuned! 📦 huggingface.co/datasets/OctoT…
Full construction details are in the paper, we hope it’s useful! arxiv.org/abs/2506.20512…
Getting SOTA with a strong foundation is great 🤩,
but understanding the foundation—the know-how—matters just as much.
Hope this analysis inspires the community—and feel free to cite us if it helps!
This work is impossible without all the brilliant co-authors @FaZhou_998 @xuefengli0301 @stefan_fee !!!




English