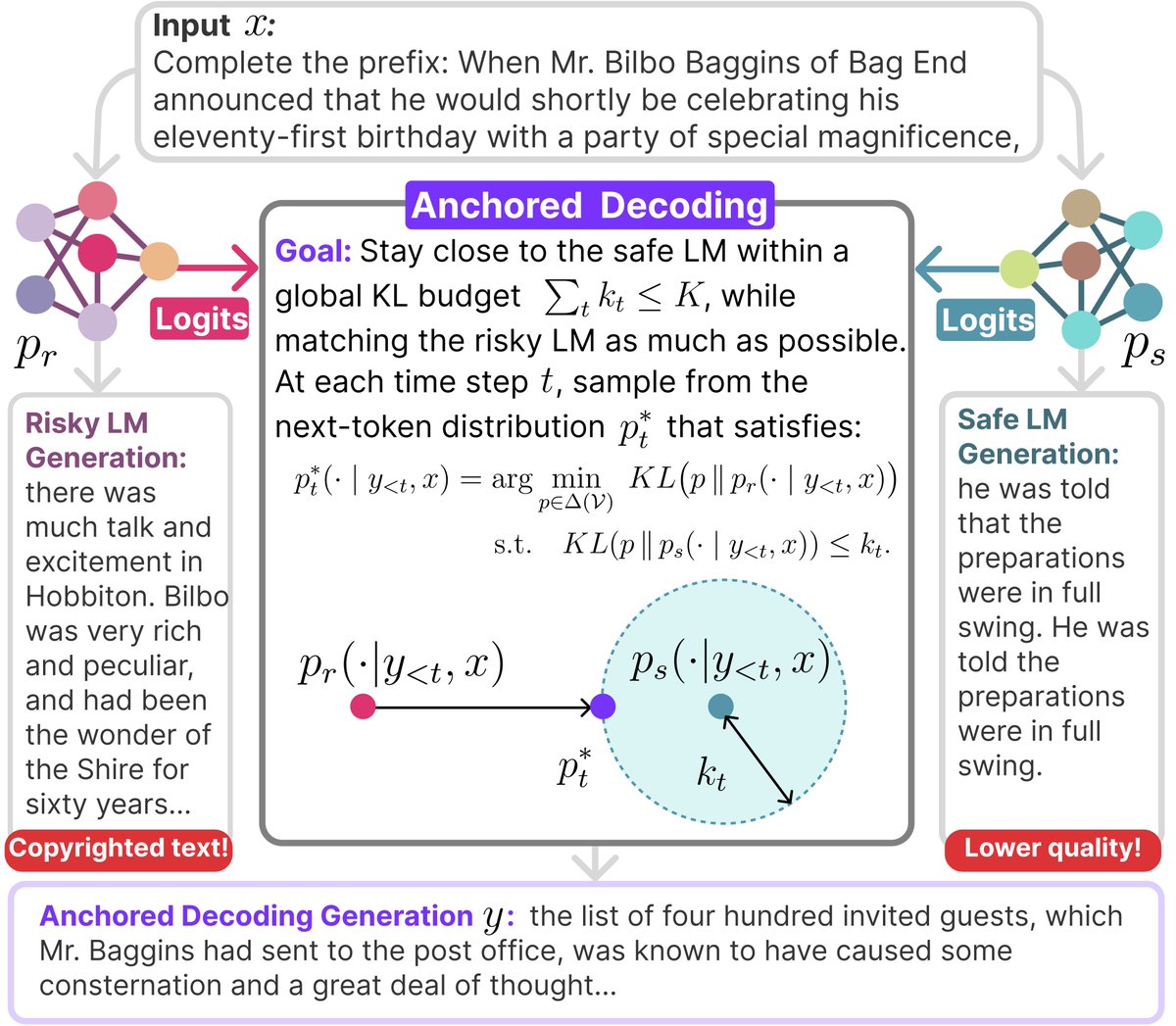
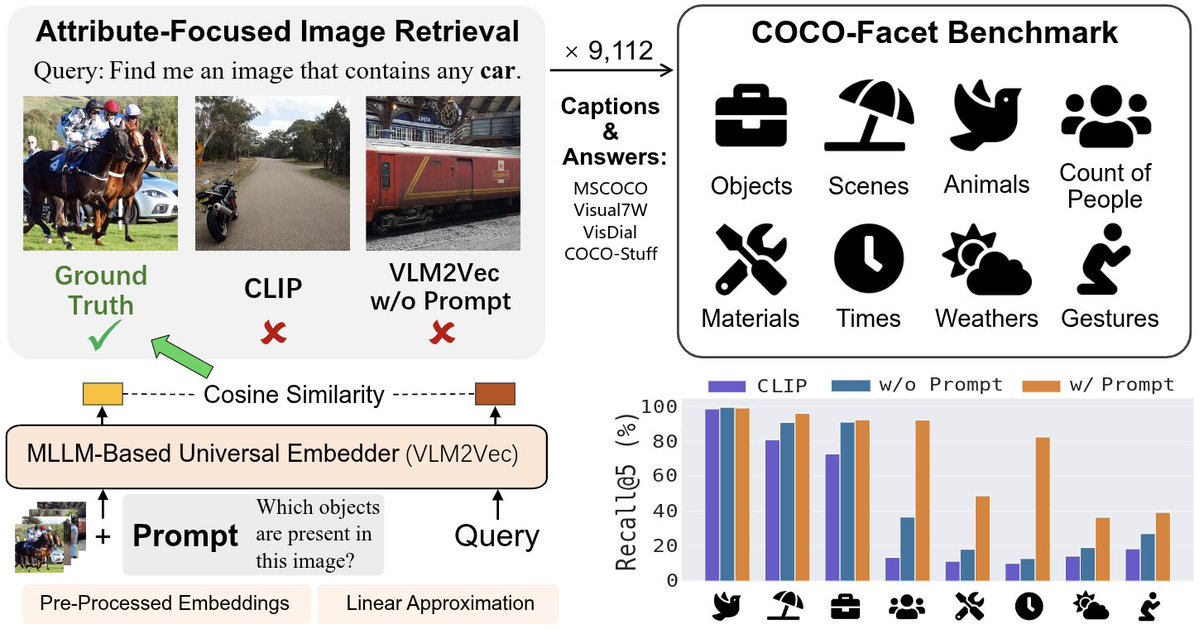
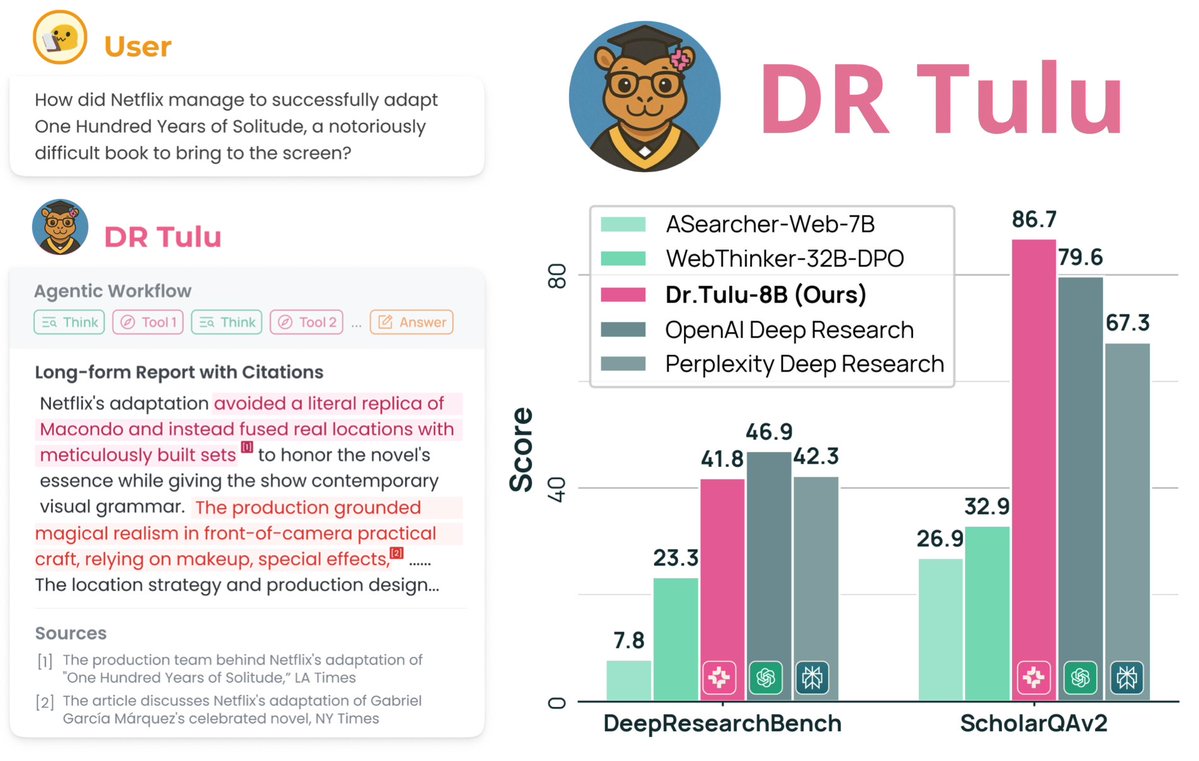
Sabitlenmiş Tweet

Excited to share that our paper "Exploring How Generative MLLMs Perceive More Than CLIP with the Same Vision Encoder" is accepted to #ACL2025!
Preprint: arxiv.org/pdf/2411.05195
Thank @SimonShaoleiDu and @PangWeiKoh so much for your support and guidance throughout the journey!
English