Giveaway time!
Win a Claude Max 20x subscription for one month.
To enter
> follow @BleapApp
> RT and like this post
Winner will be selected in 48 hours.
(fyi, you get 20% cashback on your claude, chatgpt and gemini subscriptions when using a Bleap card)
Download the app via the link in our bio today and activate your virtual card in minutes.
playground.microsoft.ai is now available in the USA and soon all over the world.
Today we unveil our image generation models. Soon everyone will have access to many more models to play with in our playground. Enjoy!
Wanna help build these models? JoinAITeam@microsoft.com - In particular, I'm looking for exceptional data, research and infra engineers.
What I like most is the systems idea: keep expensive hardware busy by doing the right work in parallel, and use prediction plus caching to avoid idle time (Don’t let the no-work time go unused!)
#AI#LLM#Inference#Systems#GPU#PerformanceEngineering
Reported results (on Llama-3.1-70B with H100 GPUs) show up to about 2x faster than optimized speculative decoding and up to about 5x faster than standard autoregressive decoding.
I read a new paper called “Speculative Speculative Decoding” (arXiv:2603.03251).
The problem is simple: large language mathematical systems generate text one token at a time. That sequential loop becomes the bottleneck during inference, even on powerful GPUs.
What I like most is the systems idea: keep expensive hardware busy by doing the right work in parallel, and use prediction plus caching to avoid idle time (Don’t let the no-work time go unused!)
#AI#LLM#Inference#Systems#GPU#PerformanceEngineering
Reported results (on Llama-3.1-70B with H100 GPUs) show up to about 2x faster than optimized speculative decoding and up to about 5x faster than standard autoregressive decoding.
Temple has raised its first round. Friends and family. $54m. Post-money valuation of ~$190m.
Every investor in this round is a founder friend or early-stage Zomato investor who wanted in, whether or not Temple ever makes it to market.
But here's what gives me goosebumps – more than 30 Temple employees participated in the round, at par valuation. No discount. Their own money. That's the kind of belief you can't buy.
We are assembling a dream team to build the ultimate wearable for elite performance athletes. Want in? Look up my last post.
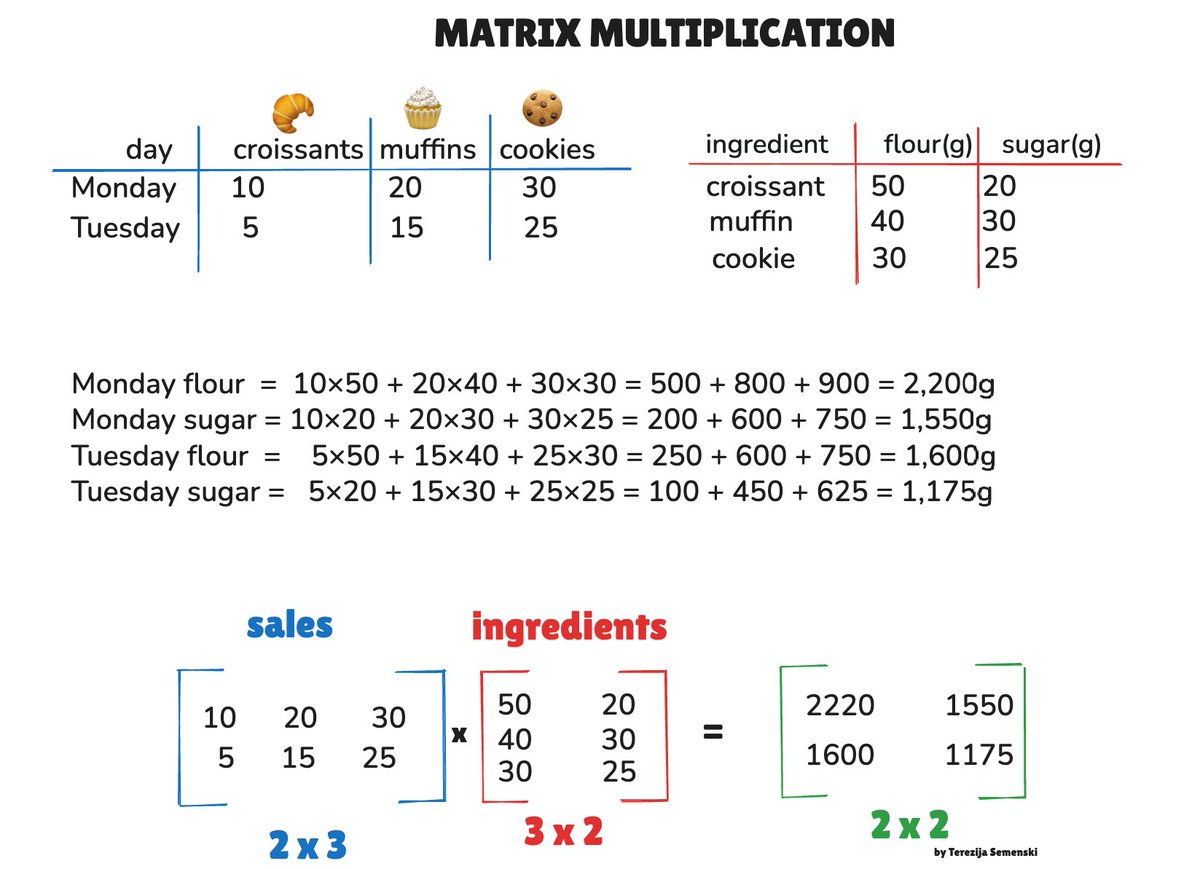
Most ML engineers use matrix multiplication every single day.
Only a few of them can explain what it's actually doing. Here's how matrix multiplication REALLY works, explained visually so it finally clicks 🧵👇