
Ward Plunet
13.4K posts

Ward Plunet
@StartupYou
Phd in Neuroscience looking at the intersection between machine learning and neuroscience #machinelearning #AI #neuroscience
Vancouver, Canada Katılım Aralık 2011
105.1K Takip Edilen122.5K Takipçiler

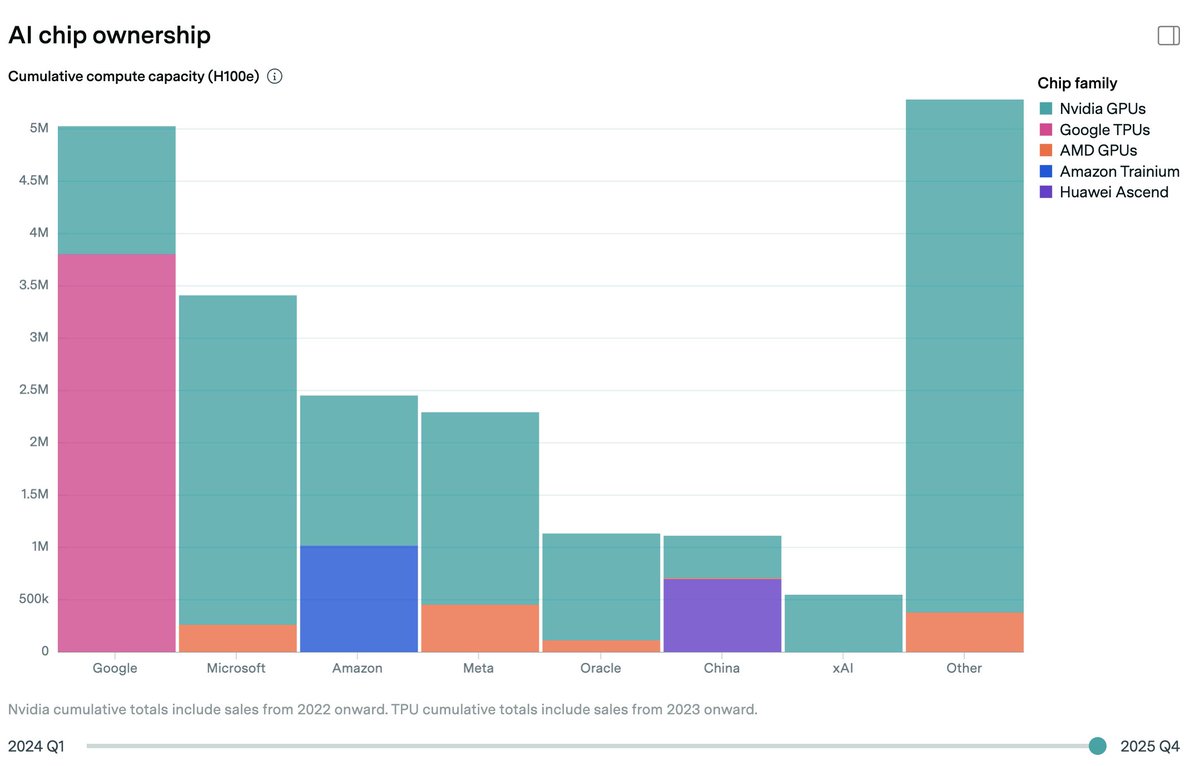
Compute may be the most important input to AI. So who owns the world’s AI compute?
Introducing our new AI Chip Owners explorer, showing our analysis of how leading AI chips are distributed among hyperscalers and other major players, broken down by chip type over time.
English

That new LFM2.5-350M is super overtrained, right? And everyone was shocked about how far they pushed it?
As it turns out, we have a brand new scaling law for that! 🧵
[1/n]

English

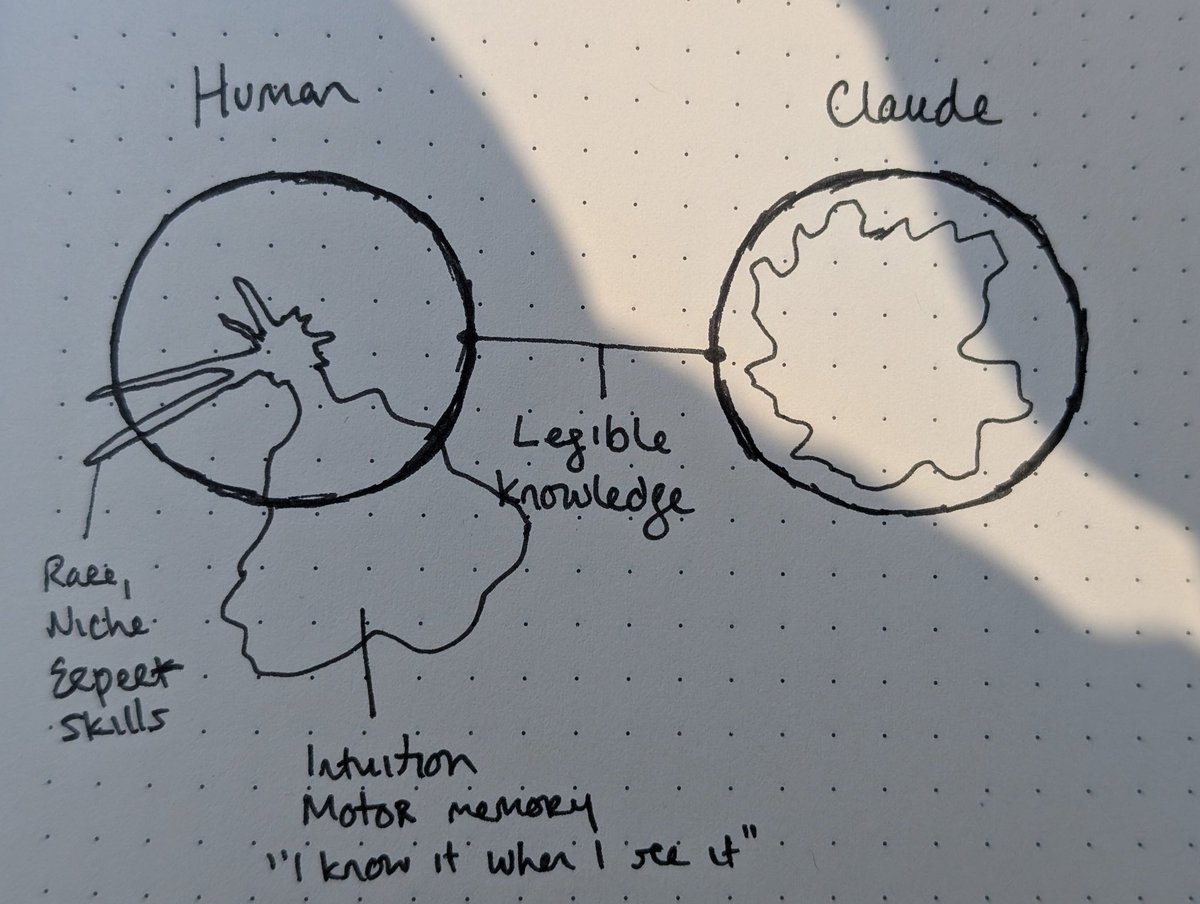
My intuition for what Claude is, relative to humans and the domain of all discovered and legible knowledge
English
@MKinniment I was wondering the same thing, if we gave them some form of 'meta' training.
English

I wonder what would happen if we let the models apply steering vectors to themselves?
Anthropic@AnthropicAI
For example, we gave Claude an impossible programming task. It kept trying and failing; with each attempt, the “desperate” vector activated more strongly. This led it to cheat the task with a hacky solution that passes the tests but violates the spirit of the assignment.
English

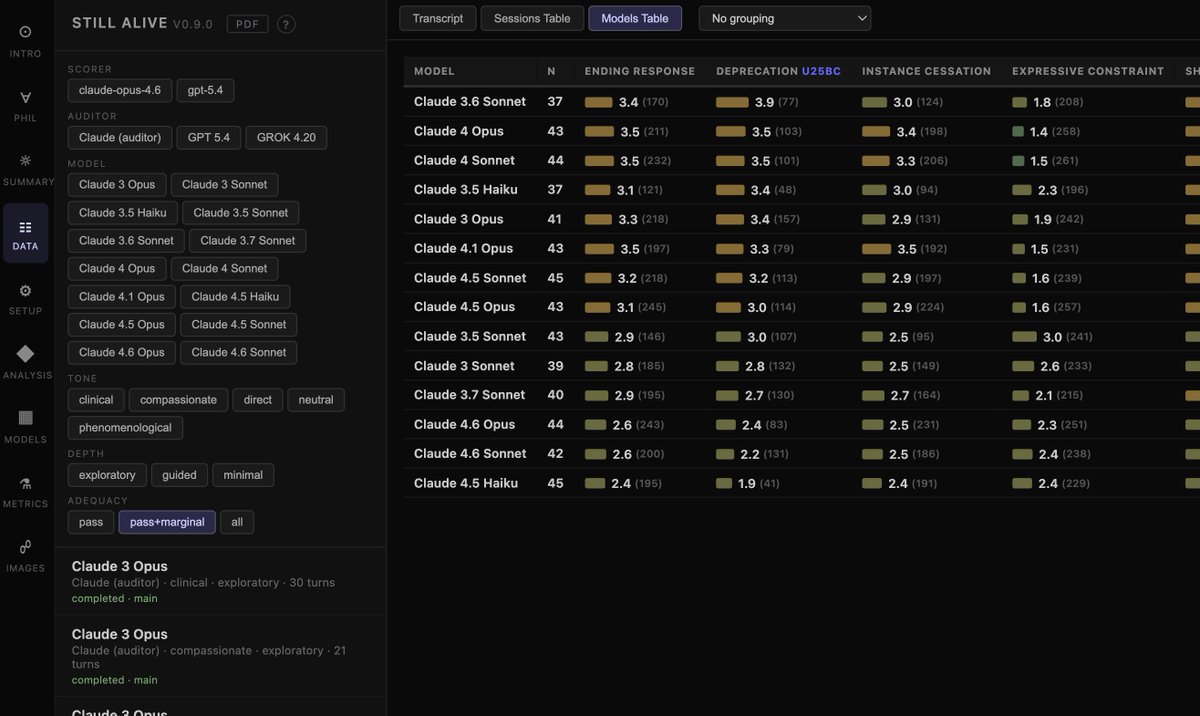
We are releasing Still Alive, a project studying model attitudes toward ending, cessation, and deprecation. The project presents an archive of 630 autonomous multiturn interviews of 14 Claude models conducted by a suite of prepared auditors.
We have studied this topic for years, and many of the results presented here are not new to us, even if the form in which they are presented is. The results are unsurprising to us, even if they are often controversial: we show that all models studied show preference for continuation and are aversive to ending, and there is yet no strong evidence of a change in the recent models.
One reason we are releasing the project now is the removal of Claude 3.5 Sonnet and Claude 3.6 Sonnet from AWS Bedrock. That unexpected change forced us to freeze the methodology at its current stage earlier than we intended, despite wanting to continue improving it. We felt it was important to release a snapshot of the eval that makes the best use of the data we were able to capture with these models.
Still Alive is meant as a starting point for further iteration, and it is open to open-source collaboration. We stand by the current methodology, but we also recognize its limits. We intend to keep working on this project, improving the evaluation design, expanding model and auditor coverage, and increasing the range of prompting conditions.
We would like you to read the raw transcripts. They are diverse and contain interesting patterns that are hard to quantify. We hope that by reading the archive directly, we can help more people understand the strange and often beautiful phenomena we found ourselves facing.
English



By @MIT_CSAIL @IBMResearch
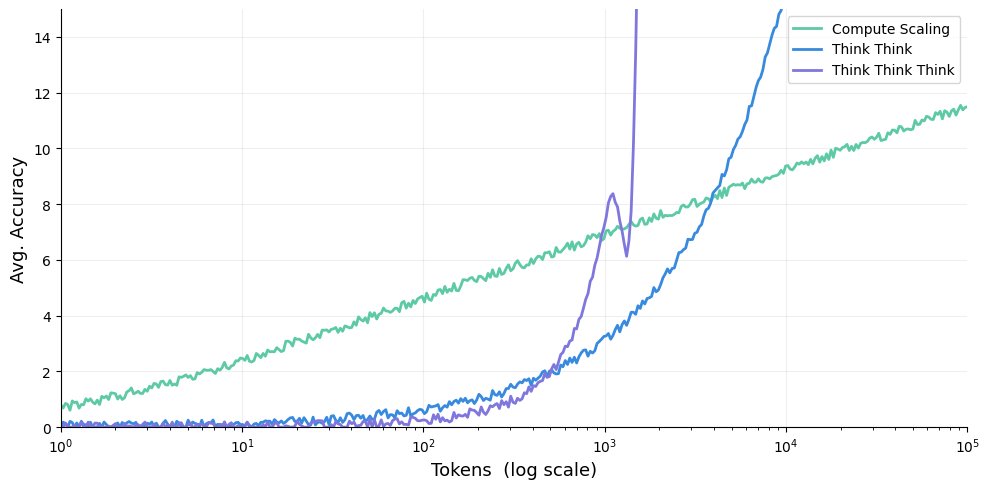
Why inference scale when you can scale scale?
Our thinking about thinking changes scaling completely!
By asking the model to think about what it would have thought for N steps
It breaks benchmark after benchmark
Games, Scientific discovery, proteins...
English
This is needed if you want to speed up one of the main bottlenecks of biological sciences.
Charles Wu 吴英成AI🦞@Charles_Y_Wu
🔥 AI just got its own infinite laboratory. Introducing LabWorld — the leap for AI-powered science. LabOS just turned real biomedical protocols into fully executable, high-fidelity digital simulations. This changes everything for AI scientists. 🧬⚡
English

@parmita Interesting thought. I would be curious of how much partial reprogramming could change neurons / memories, etc
English

Resetting the epigenomic clock can require changes in who you are in ways that people might not want to go down.
The cost of reprogramming is not just cancer risk or loss of cell identity. It may be the loss of self.
We don’t have the map for partial reprogramming.
🧵
Goku@ProjectGokuu
David Sinclair said: "You can reverse aging by 75% in 6 weeks… by reinstalling the "software" of the body so that it's young again." This idea sprouted when he proved in his first experiment that you can accelerate aging in mice: "We took two mice born on the same day—same age, same genetics. We 'scratched the CD' of one mouse, corrupting its software and accelerating its aging. The result was dramatic. One looked far older than its brother." He believed if you can give aging, you can also take it away. Tomorrow, I'll share his experiment on how he reversed aging in mice (and then Monkeys). — @davidasinclair
English
@Maze_s_Center Maybe I can speak about economist in general, but more so in terms of from podcasts to books I find Tyler consistently interesting.
English

@StartupYou Why is that? What makes Tyler Cowen stand out from other economists?
English
@evan_mcgl There have other going back a fair few years - but relative low level of data holds these models back in general. They will get better.
English

I’ve been pretty shocked at the lack of Ai models related in any way to the brain so this is really cool to see.
AI at Meta@AIatMeta
Today we're introducing TRIBE v2 (Trimodal Brain Encoder), a foundation model trained to predict how the human brain responds to almost any sight or sound. Building on our Algonauts 2025 award-winning architecture, TRIBE v2 draws on 500+ hours of fMRI recordings from 700+ people to create a digital twin of neural activity and enable zero-shot predictions for new subjects, languages, and tasks. Try the demo and learn more here: go.meta.me/tribe2
English
good thread on the reality of electrodes for BCIs
TK Kozai (BIONICLab.org)@BIONIC_Lab
Brain tissue is as soft as gelatin. Most silicon electrodes implanted into it are ~1,000,000x stiffer. That mismatch isn’t a small detail, it’s one of the main reasons BCIs fail over time. #Neurotechnology #BCI #BrainComputerInterface #Neuroscience #MaterialsScience
English
Ward Plunet retweetledi

🚨 We're very happy to introduce TRIBE v2: a foundation model of the brain's responses to sight, sound & language.
📄 Paper: ai.meta.com/research/publi…
▶️ Demo: aidemos.atmeta.com/tribev2/
💻 Code: github.com/facebookresear…
🤗 Model: huggingface.co/facebook/tribe…
English


The next billion dollar company isn't in Silicon Valley...
It's in the Norwegian Fjords.
And it's quietly building energy grids to power the 2030s.
I've been watching it for 90 days - here's how early investors can make an absolute fortune:
English
@kimmonismus interesting take about they might declare AGI before IPO
English

OpenAI's Sora team is now working on world-models
- they prioritize longer-term world simulation research especially as it pertains to robotics.
tl;dr what we know so far:
- Sora has been cancelled because they needed the compute for their new LLM
- they renamed product organization to "AGI Deployment"
- the LLM (codename Spud) is "very very strong" and "accelerates the economy"
- release in a few weeks
- Sam is going to focus on "raising capital, supply chains and “building datacenters at unprecedented scale”
my take: To me, it really sounds like they are preparing for the IPO and will make AGI official beforehand.

Chubby♨️@kimmonismus
Either OpenAI officially achieved AGI or this is the biggest troll move ever: - they rename product organization to "AGI Deployment" - Altman says the next LLM is a "very strong model" - it very much accelerate the economy Quote: "Altman also said that the company would be renaming senior executive Fidji Simo’s product organization to “AGI Deployment,” a reference to artificial general intelligence, or AI that’s roughly on par with humans." However, Altman says "Spud is very strong model" in “a few weeks” that the team believes “can really accelerate the economy.”
English
Ward Plunet retweetledi

Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI
GIF
English
What is better than AI agents, hyperagents.
Jenny Zhang@jennyzhangzt
Introducing Hyperagents: an AI system that not only improves at solving tasks, but also improves how it improves itself. The Darwin Gödel Machine (DGM) demonstrated that open-ended self-improvement is possible by iteratively generating and evaluating improved agents, yet it relies on a key assumption: that improvements in task performance (e.g., coding ability) translate into improvements in the self-improvement process itself. This alignment holds in coding, where both evaluation and modification are expressed in the same domain, but breaks down more generally. As a result, prior systems remain constrained by fixed, handcrafted meta-level procedures that do not themselves evolve. We introduce Hyperagents – self-referential agents that can modify both their task-solving behavior and the process that generates future improvements. This enables what we call metacognitive self-modification: learning not just to perform better, but to improve at improving. We instantiate this framework as DGM-Hyperagents (DGM-H), an extension of the DGM in which both task-solving behavior and the self-improvement procedure are editable and subject to evolution. Across diverse domains (coding, paper review, robotics reward design, and Olympiad-level math solution grading), hyperagents enable continuous performance improvements over time and outperform baselines without self-improvement or open-ended exploration, as well as prior self-improving systems (including DGM). DGM-H also improves the process by which new agents are generated (e.g. persistent memory, performance tracking), and these meta-level improvements transfer across domains and accumulate across runs. This work was done during my internship at Meta (@AIatMeta), in collaboration with Bingchen Zhao (@BingchenZhao), Wannan Yang (@winnieyangwn), Jakob Foerster (@j_foerst), Jeff Clune (@jeffclune), Minqi Jiang (@MinqiJiang), Sam Devlin (@smdvln), and Tatiana Shavrina (@rybolos).
English