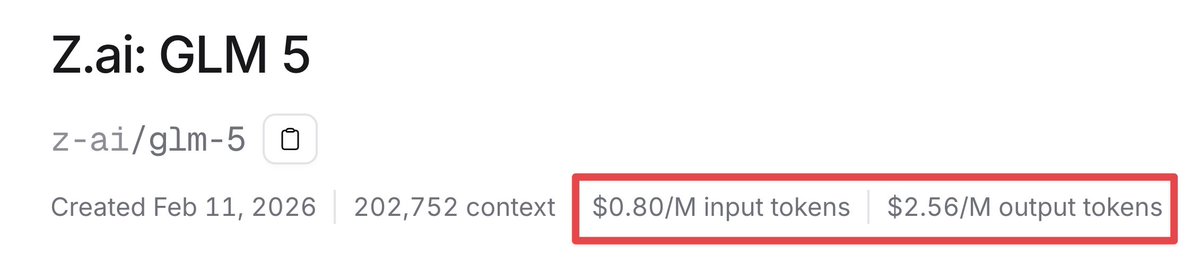
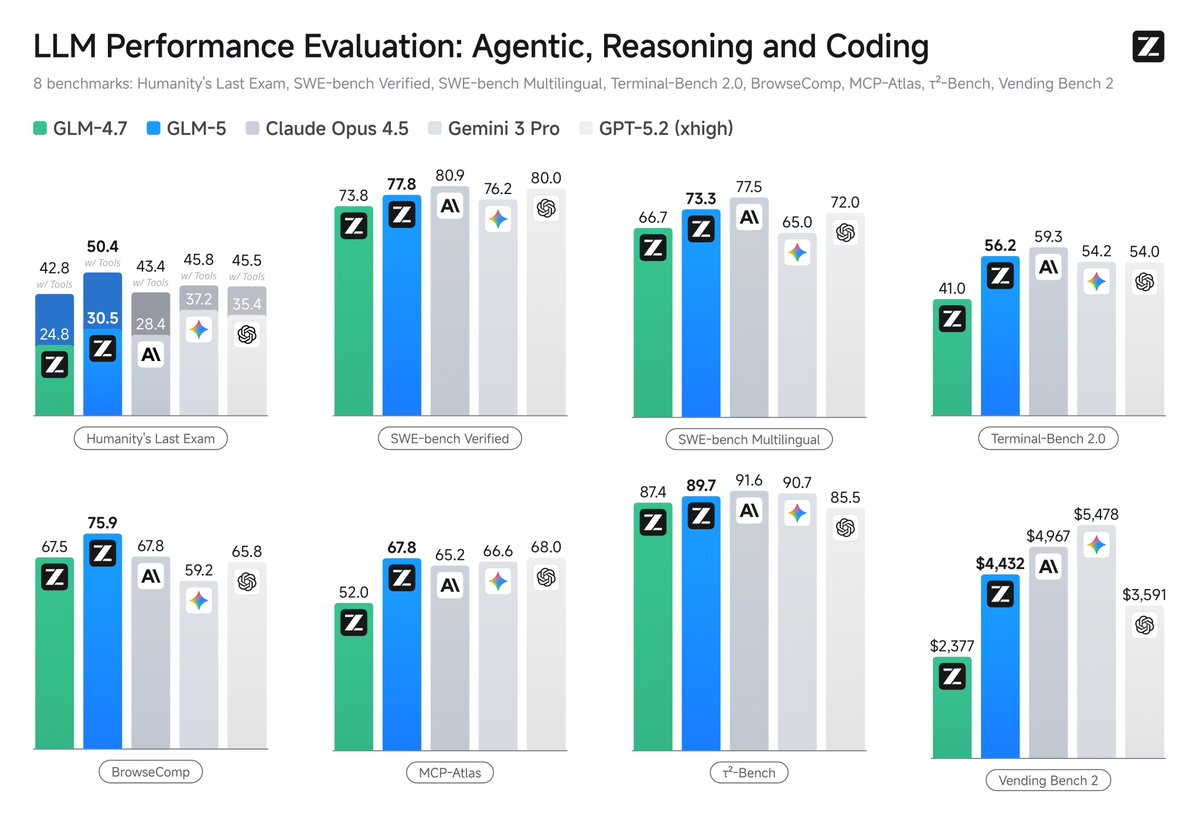
@warpdotdev Nice release!!! Worked out quite well from initial testing.
Here's the quick way to plug into DeepInfra for cheap.

English
Thach Nguyen
178 posts
@Thachnh
Staff @DeepInfra - building AI Inference Cloud | Co-Founder & CEO @Millis.ai - 600ms AI Voice Agent


OpenClaw 2026.4.27 🦞 🧠 DeepInfra provider 📎 better file attachments 🛡️ operator-managed proxy routing 🧭 stricter model selection + local model fixes 🔧 gateway, channel, and session reliability Ships more than it brags. github.com/openclaw/openc…