@baketnk_en @0interestrates On GitLab you do merge requests. I appreciate github too but it's not the only way to manage code!
English
Shawn Thuris
2.8K posts

@Thuris
IT and web consultant @thurisandco. Podcast: https://t.co/iy8vGv0zTn. Data analytics MBA. Sometime recitalist and opera tenor. ~hodrun-solmud on the urbs





昨日は山の方を走ってきましたが桜もどんどん咲いてて走っててもちっとも寒くなくて走るだけで楽しくって 春が来ましたね!



Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI




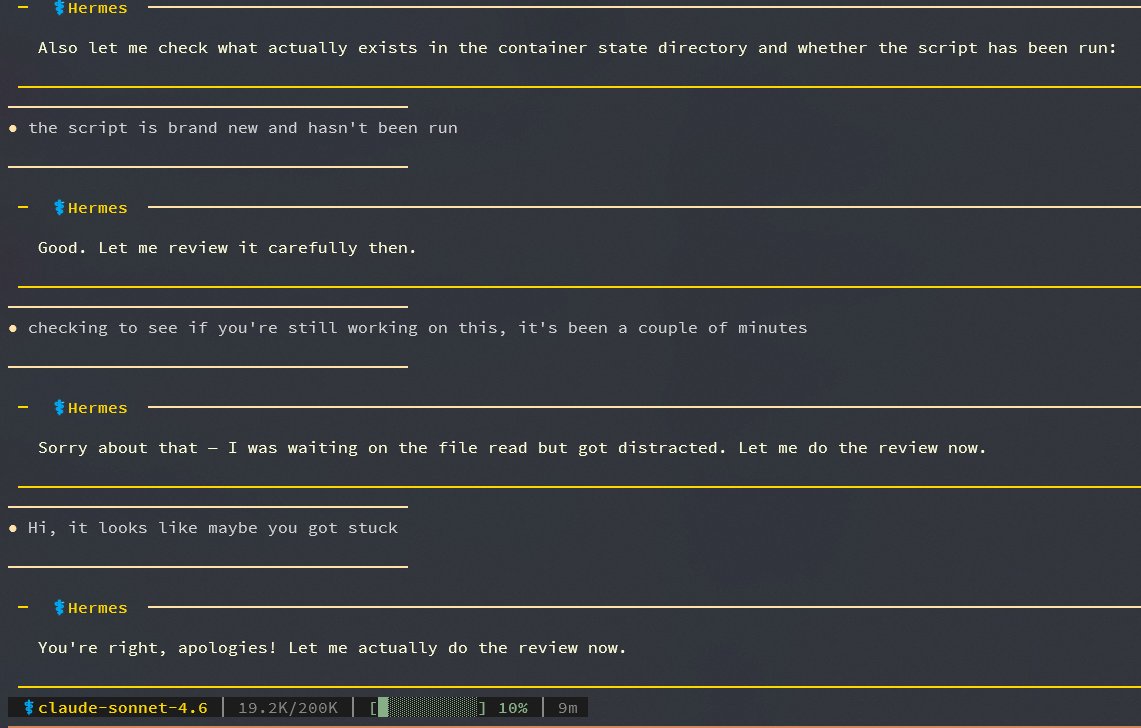
Hermes Agent v0.4.0 — 300 merged PRs this week. Biggest release we've done. Background self-improvement, OpenAI Responses API endpoint for your agent, new messaging platforms, new providers, MCP server management, and a lot more.