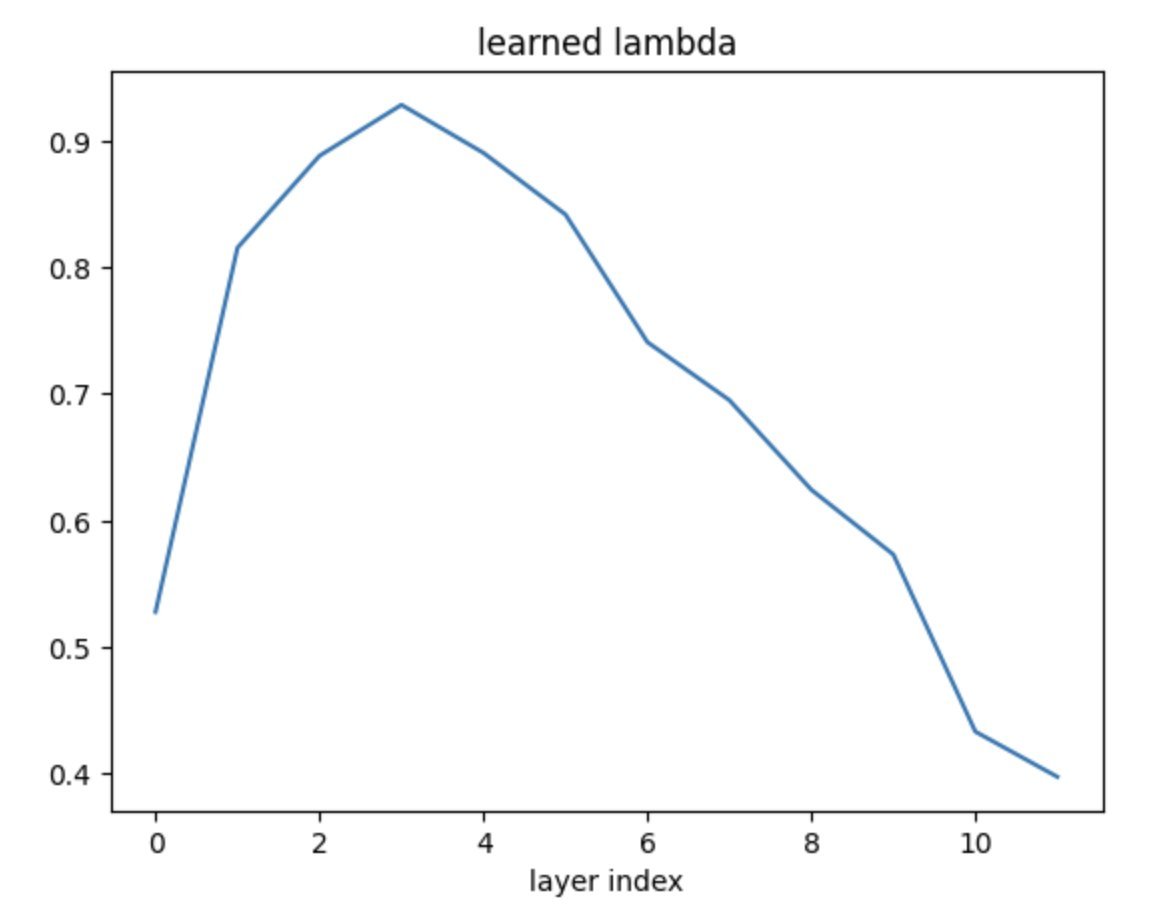
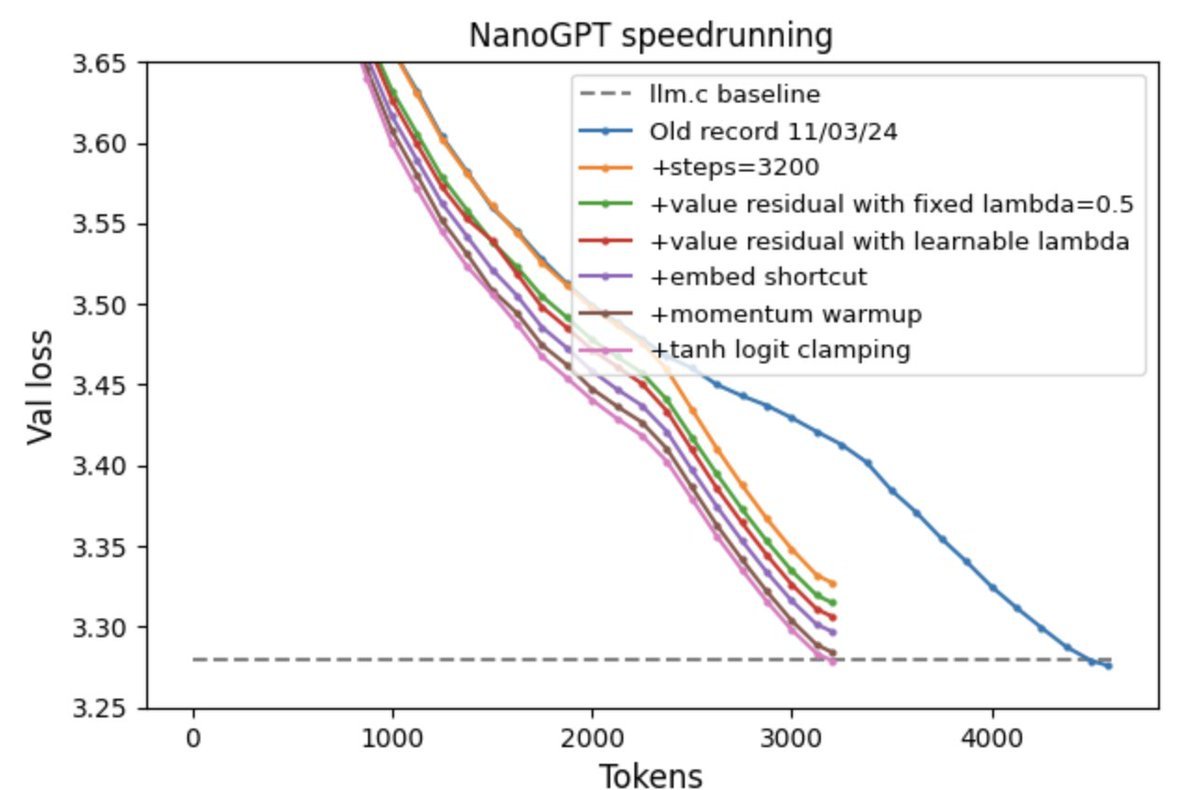
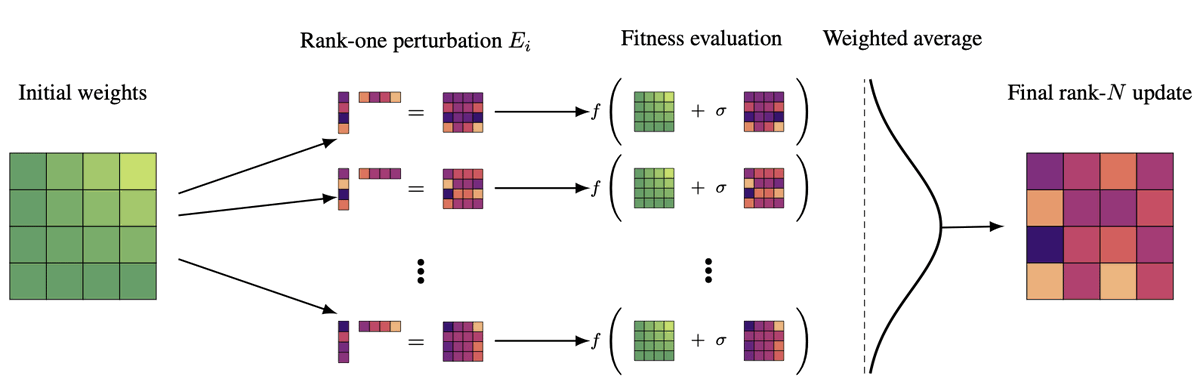
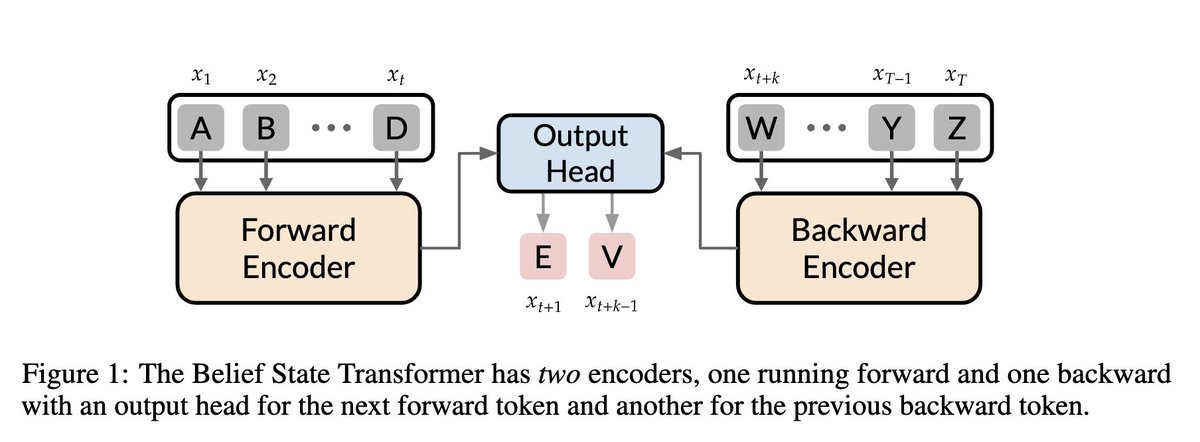
Karn Tiwari retweetledi

Flow-based generative models trained with flow matching tend to learn curved trajectories, which are challenging to approximate in a few steps.
Rectified flows aim to learn straight trajectories, which are easier to simulate with less computation.
English