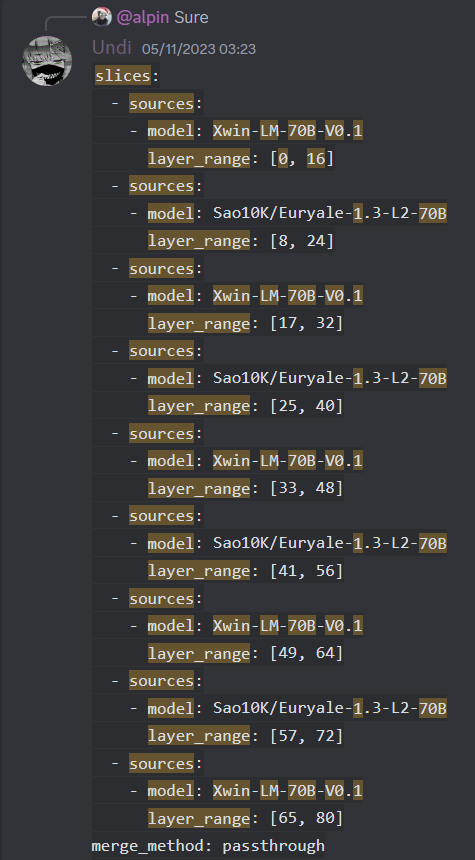
Undi
50 posts



Mathieu a mis fin à ses jours, trois mois après avoir reçu une greffe de barbe à Istanbul, en Turquie. Résultat désastreux, douleurs atroces, sentiment de trahison… Son père Jacques témoigne ➡️ l.leparisien.fr/BwqW


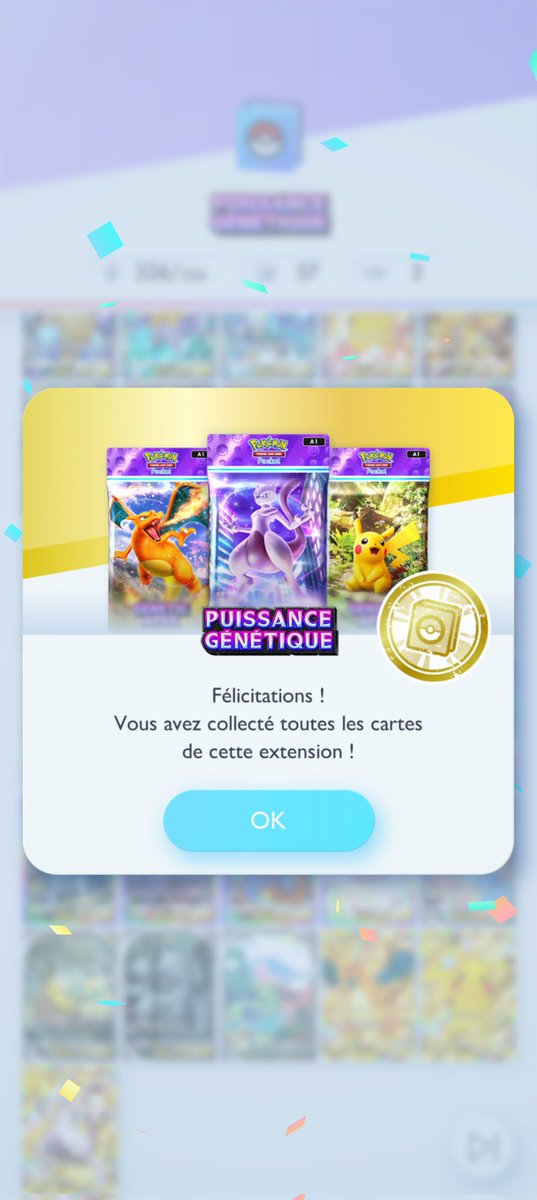

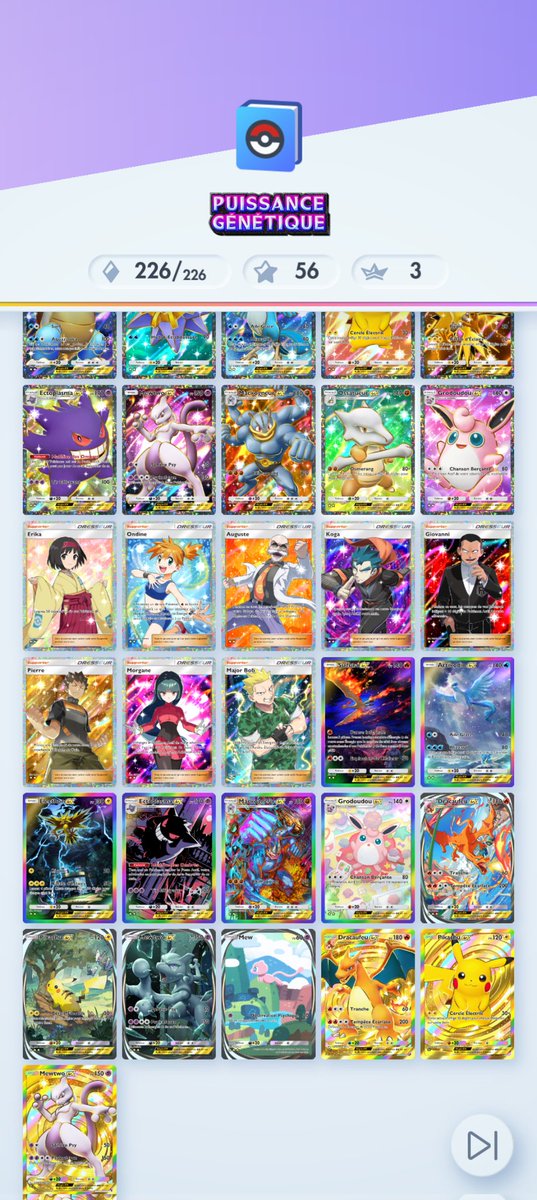




As I thought, 24g is definitely enough for training. I think even batch size2 shouldn't be difficult.

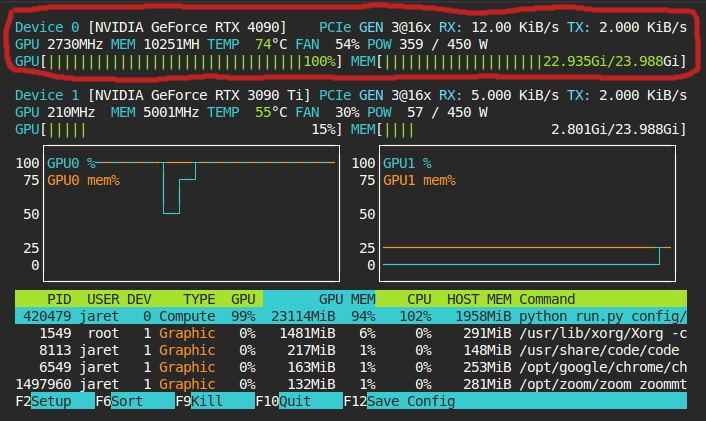
This can be optimized further. I think you could maybe do mixed precision 8bit quantization on the transformer (maybe). But, no matter how optimized it gets, I don't think it will ever be possible to train on current consumer hardware (<=24gb). Someone please prove me wrong.




🔮 Based on my research of open source Grok-1, I am confident in saying that Grok-2 will be one of the most powerful LLM AI platforms when it is released. It will surpass OpenAI on just about every metric.






#solarllm @upstageai Tech report: arxiv.org/abs/2312.15166 We introduce depth up-scaling (DUS), a novel technique to up-scale base LLMs efficiently and effectively in a simple manner. In contrast to mixture-of-experts (MoE), DUS does not require complex changes to train and inference. Using DUS, we build SOLAR 10.7B, a large language model (LLM) with 10.7 billion parameters, demonstrating superior performance in various natural language processing (NLP) tasks. Comparative evaluations show that SOLAR 10.7B outperforms existing open-source pretrained LLMs, such as Llama 2 and Mistral 7B. We additionally present SOLAR 10.7B-Instruct, a variant fine-tuned for instruction-following capabilities, surpassing Mixtral-8x7B. SOLAR 10.7B is publicly available under the Apache 2.0 license, promoting broad access and application in the LLM field.