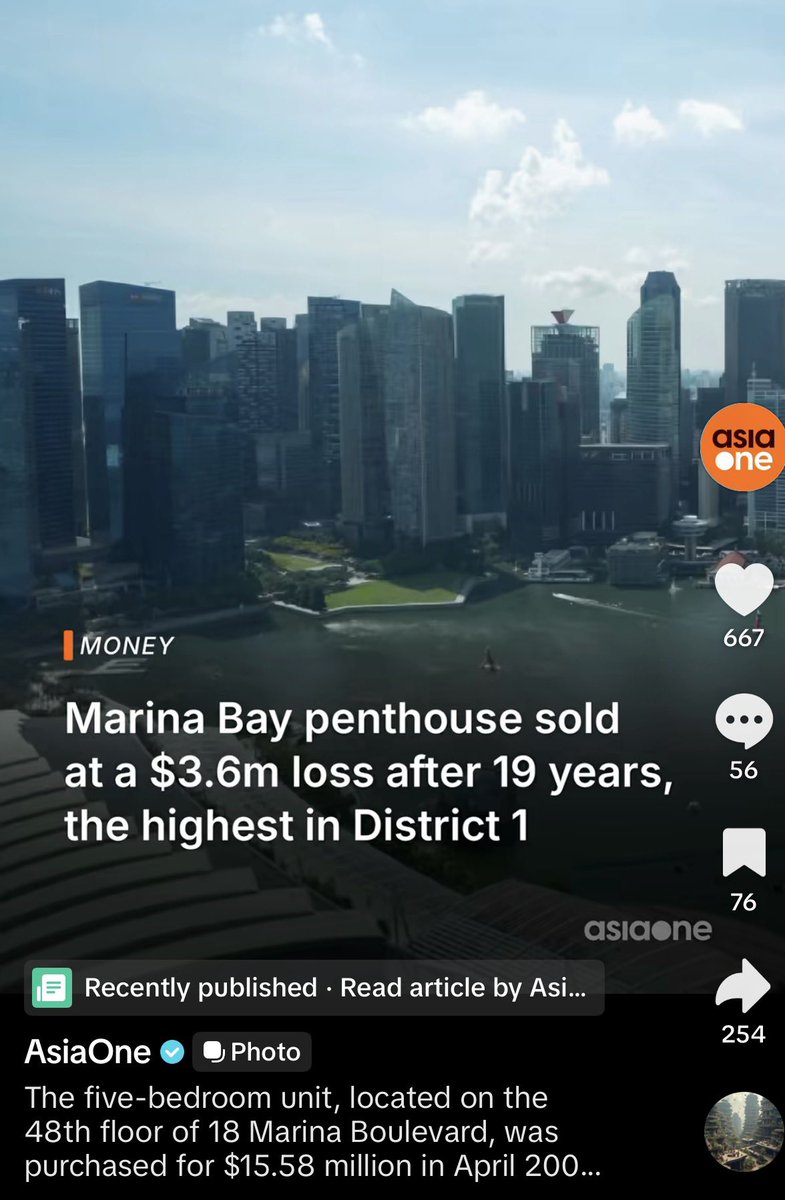
@mofmof_investor HDD stocks have more than triple the forward PE of memory stocks. This is expected by the market.
English
UshakF
743 posts




7/ Meanwhile market share is collapsing where it matters. #OpenRouter, April 2026: Chinese providers combined = 51.2%. Anthropic = 15.4%, down from a 29.1% peak. #Xiaomi alone has more traffic than #Anthropic.



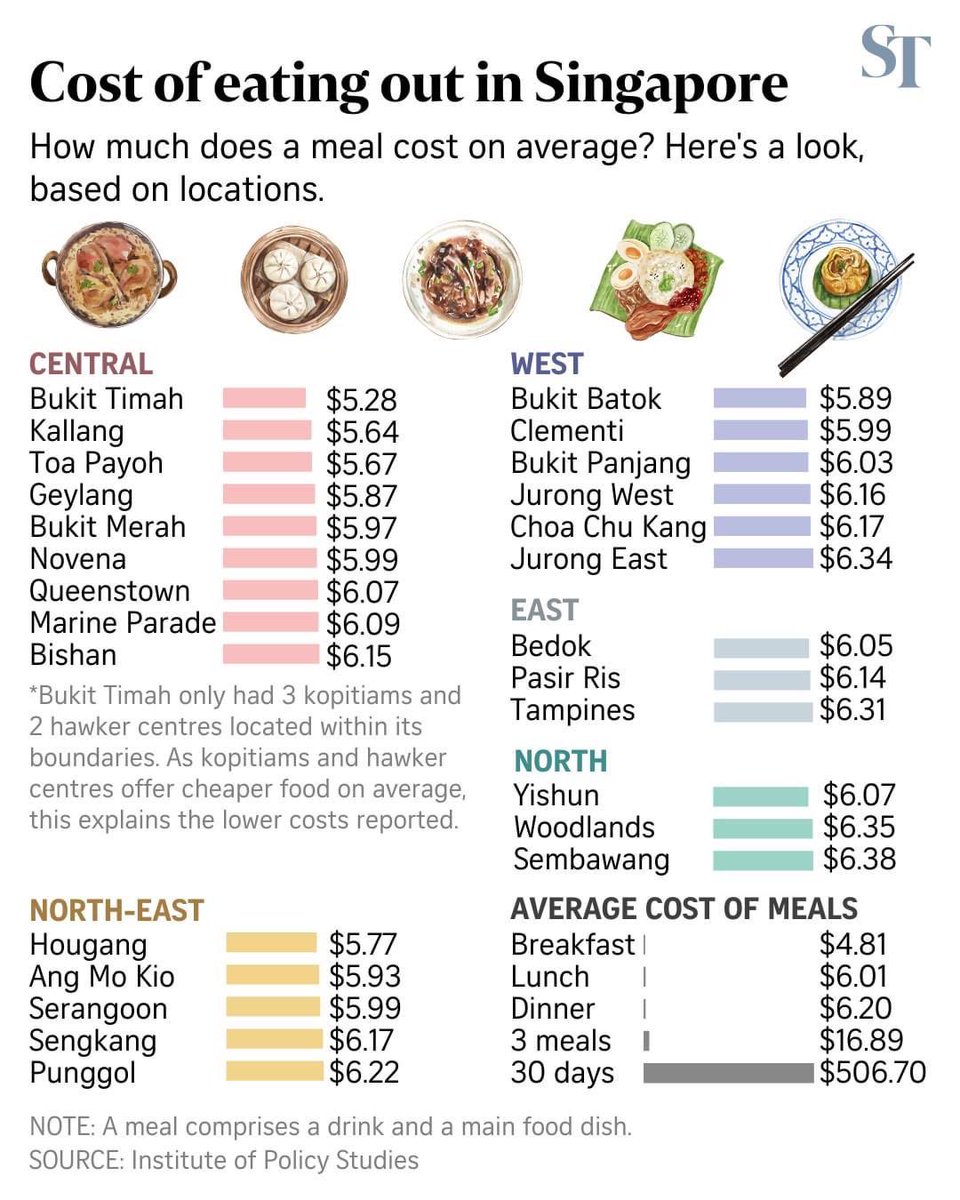
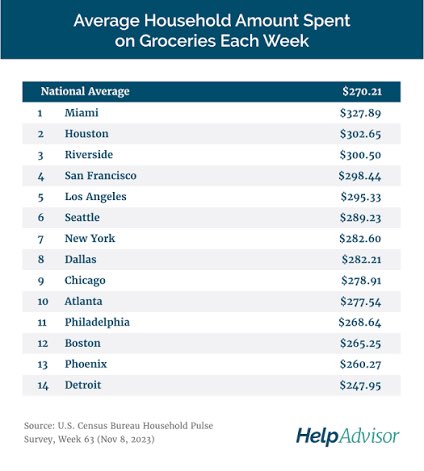
That’s why I’ve never got the whole ‘Singapore is expensive’ stereotype, especially when it comes from locals. Singapore is expensive for expats, given that they have to rent private housing, are subject to expensive international school fees for their children etc. But for locals? In relation to the average salaries, it’s far cheaper than our neighbours and other global cities.

For frontier AI chips, memory is the largest and fastest-growing component cost. High-bandwidth memory (HBM) has grown from 52% to 63% of total AI chip component spending between Q1 2024 and Q4 2025.

ANTHROPIC EYES MICROSOFT CHIPS Anthropic is in early talks to rent Azure servers powered by $MSFT’s Maia AI chips, per The Information. This would deepen a relationship that is already moving fast: Microsoft has pledged up to $5B to Anthropic, Anthropic committed $30B of Azure spend, and Microsoft is reselling Claude through Azure. The chip angle matters because Maia is being pitched as cheaper than Nvidia for some inference workloads, not as a frontier training replacement. Anthropic already uses Amazon, Google, and Nvidia chips. Now Microsoft wants Maia in that mix.

Absolutely true — I was meeting with those same telco equipment guys regularly in 2000. Also irrelevant to the point I was trying to make. Back then, supply could largely keep up with demand because there was massive underutilized wafer capacity coming out of the 1998 Asian crisis that could ramp quickly. The relatively quick supply response led to an overbuild, which caused the crash as the overbuild was largely debt funded which required an immediate ROI for the CLECs to service their debt. There is no comparable slack in the system today. Leading edge wafers and power are both structurally constrained, and neither can be turned on in a matter of months. That’s the core difference imo. And obviously the largest buyers of compute will have no trouble servicing their debt anytime in their near future. I might be wrong, we might be in a bubble, you might be right, time will tell. Good luck!

The Korean stock market is experiencing 5-8% moves every day Nursing homes are buying leveraged positions, their under 35 male population (who is going extinct) are selling plasma to buy stocks & the government is full bore backing it

FORWARD DEPLOYED NATION 🇸🇬 @OpenAI 's first applied ai lab outside of the US is in singapore if you aren't bullish on that pink ic yet, you should be nowww 🩷



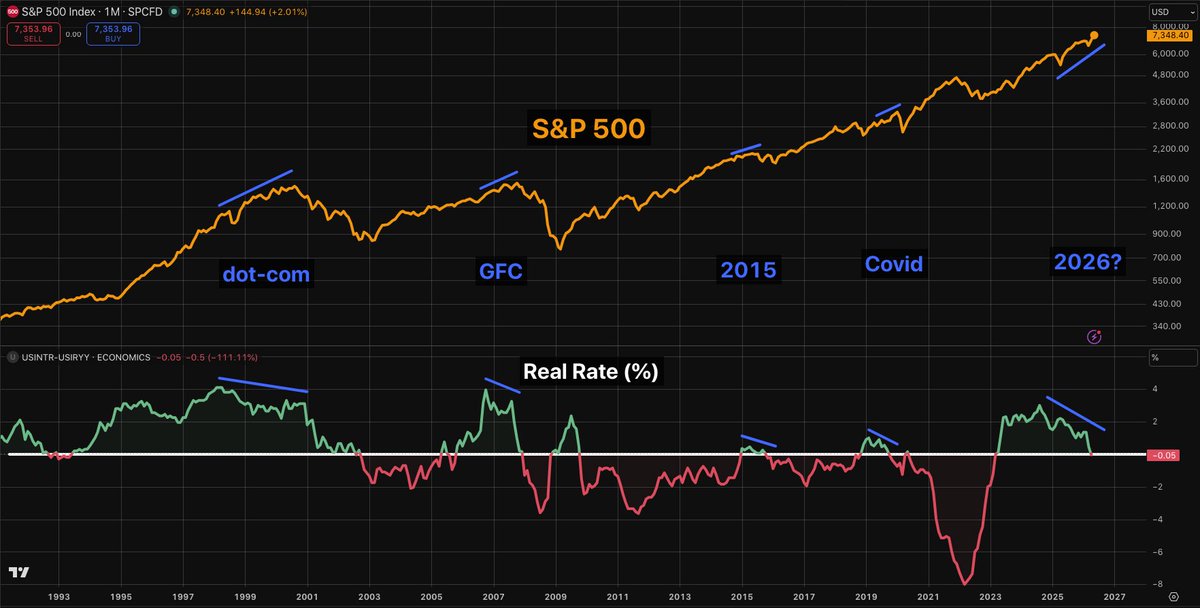
easiest trade a Singaporean 🇸🇬 can take right now stockpile $SGD, downpay a private apartment / landed property, take the remaining 75% as a loan hold until SGD:USD moves to 1:1, while your land quietly appreciates 2–3% net per year and if you calculate the gain against your down payment instead of the full property value, the return starts looking a lot crazier Currency + Real estate appreciation